 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Pyramid Hashing
Apr 04, 2019
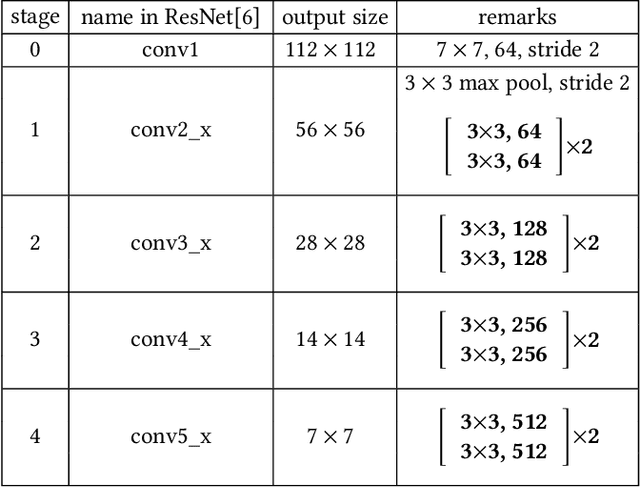
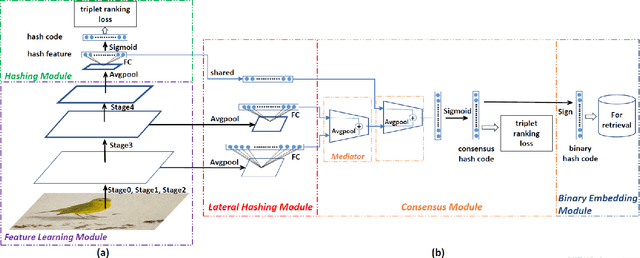
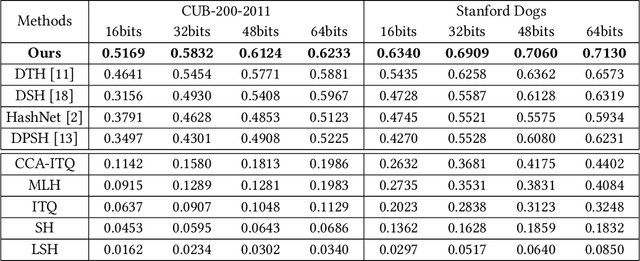
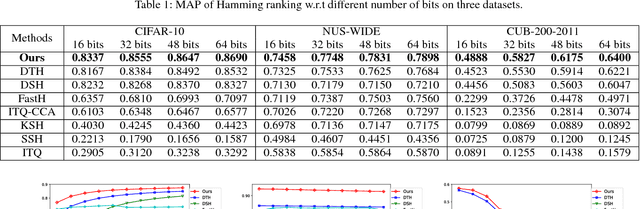
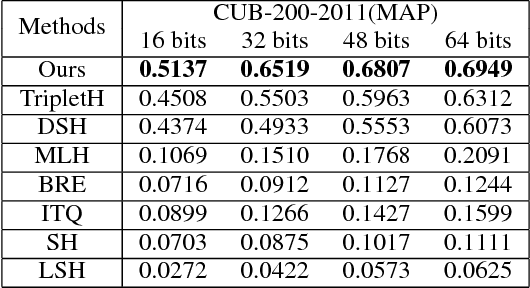
In recent years, deep-networks-based hashing has become a leading approach for large-scale image retrieval. Most deep hashing approaches use the high layer to extract the powerful semantic representations. However, these methods have limited ability for fine-grained image retrieval because the semantic features extracted from the high layer are difficult in capturing the subtle differences. To this end, we propose a novel two-pyramid hashing architecture to learn both the semantic information and the subtle appearance details for fine-grained image search. Inspired by the feature pyramids of convolutional neural network, a vertical pyramid is proposed to capture the high-layer features and a horizontal pyramid combines multiple low-layer features with structural information to capture the subtle differences. To fuse the low-level features, a novel combination strategy, called consensus fusion, is proposed to capture all subtle information from several low-layers for finer retrieval. Extensive evaluation on two fine-grained datasets CUB-200-2011 and Stanford Dogs demonstrate that the proposed method achieves significant performance compared with the state-of-art baselines.
Regularizing Deep Hashing Networks Using GAN Generated Fake Images
Sep 02, 2018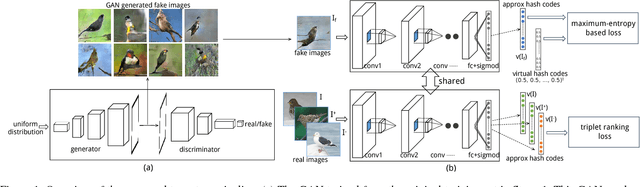

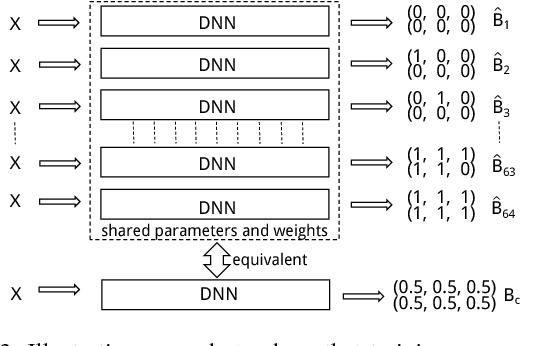
Recently, deep-networks-based hashing (deep hashing) has become a leading approach for large-scale image retrieval. It aims to learn a compact bitwise representation for images via deep networks, so that similar images are mapped to nearby hash codes. Since a deep network model usually has a large number of parameters, it may probably be too complicated for the training data we have, leading to model over-fitting. To address this issue, in this paper, we propose a simple two-stage pipeline to learn deep hashing models, by regularizing the deep hashing networks using fake images. The first stage is to generate fake images from the original training set without extra data, via a generative adversarial network (GAN). In the second stage, we propose a deep architec- ture to learn hash functions, in which we use a maximum-entropy based loss to incorporate the newly created fake images by the GAN. We show that this loss acts as a strong regularizer of the deep architecture, by penalizing low-entropy output hash codes. This loss can also be interpreted as a model ensemble by simultaneously training many network models with massive weight sharing but over different training sets. Empirical evaluation results on several benchmark datasets show that the proposed method has superior performance gains over state-of-the-art hashing methods.
Improving Deep Binary Embedding Networks by Order-aware Reweighting of Triplets
Apr 17, 2018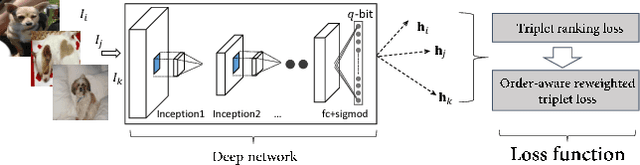
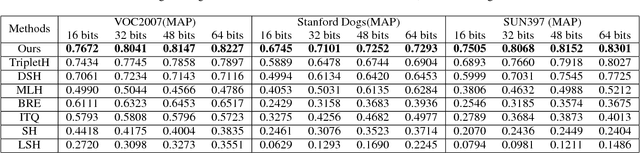
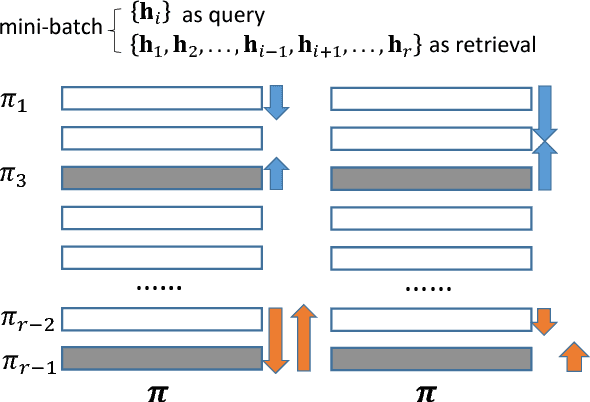
In this paper, we focus on triplet-based deep binary embedding networks for image retrieval task. The triplet loss has been shown to be most effective for the ranking problem. However, most of the previous works treat the triplets equally or select the hard triplets based on the loss. Such strategies do not consider the order relations, which is important for retrieval task. To this end, we propose an order-aware reweighting method to effectively train the triplet-based deep networks, which up-weights the important triplets and down-weights the uninformative triplets. First, we present the order-aware weighting factors to indicate the importance of the triplets, which depend on the rank order of binary codes. Then, we reshape the triplet loss to the squared triplet loss such that the loss function will put more weights on the important triplets. Extensive evaluations on four benchmark datasets show that the proposed method achieves significant performance compared with the state-of-the-art baselines.