 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Accuracy in Deep Learning Using Random Matrix Theory
Oct 04, 2023In this study, we explore the applications of random matrix theory (RMT) in the training of deep neural networks (DNNs), focusing on layer pruning to simplify DNN architecture and loss landscape. RMT, recently used to address overfitting in deep learning, enables the examination of DNN's weight layer spectra. We use these techniques to optimally determine the number of singular values to be removed from the weight layers of a DNN during training via singular value decomposition (SVD). This process aids in DNN simplification and accuracy enhancement, as evidenced by training simple DNN models on the MNIST and Fashion MNIST datasets. Our method can be applied to any fully connected or convolutional layer of a pretrained DNN, decreasing the layer's parameters and simplifying the DNN architecture while preserving or even enhancing the model's accuracy. By discarding small singular values based on RMT criteria, the accuracy of the test set remains consistent, facilitating more efficient DNN training without compromising performance. We provide both theoretical and empirical evidence supporting our claim that the elimination of small singular values based on RMT does not negatively impact the DNN's accuracy. Our results offer valuable insights into the practical application of RMT for the creation of more efficient and accurate deep-learning models.
A novel multi-scale loss function for classification problems in machine learning
Jun 04, 2021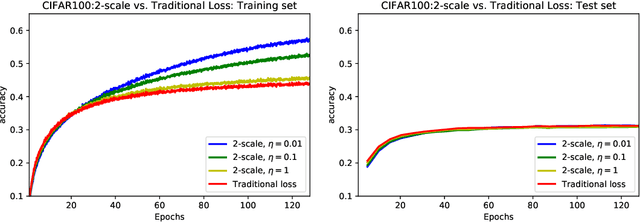
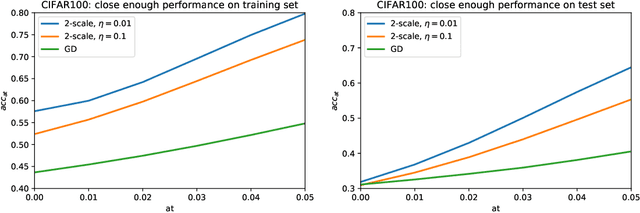
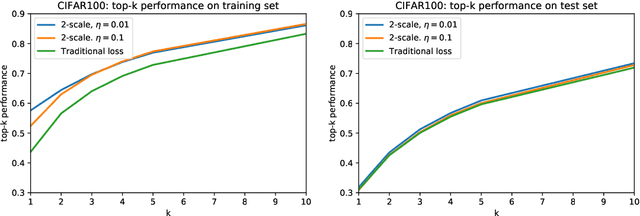
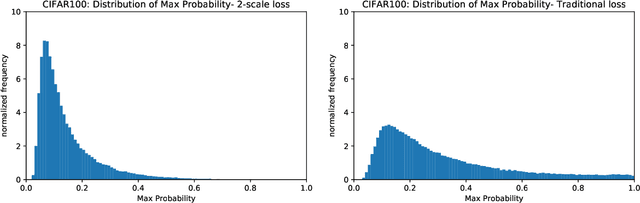
We introduce two-scale loss functions for use in various gradient descent algorithms applied to classification problems via deep neural networks. This new method is generic in the sense that it can be applied to a wide range of machine learning architectures, from deep neural networks to support vector machines for example. These two-scale loss functions allow to focus the training onto objects in the training set which are not well classified. This leads to an increase in several measures of performance for appropriately-defined two-scale loss functions with respect to the more classical cross-entropy when tested on traditional deep neural networks on the MNIST, CIFAR10, and CIFAR100 data-sets.
Stability for the Training of Deep Neural Networks and Other Classifiers
Feb 10, 2020
We examine the stability of loss-minimizing training processes that are used for deep neural network (DNN) and other classifiers. While a classifier is optimized during training through a so-called loss function, the performance of classifiers is usually evaluated by some measure of accuracy, such as the overall accuracy which quantifies the proportion of objects that are well classified. This leads to the guiding question of stability: does decreasing loss through training always result in increased accuracy? We formalize the notion of stability, and provide examples of instability. Our main result is two novel conditions on the classifier which, if either is satisfied, ensure stability of training, that is we derive tight bounds on accuracy as loss decreases. These conditions are explicitly verifiable in practice on a given dataset. Our results do not depend on the algorithm used for training, as long as loss decreases with training.