Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel multi-scale loss function for classification problems in machine learning
Paper and Code
Jun 04, 2021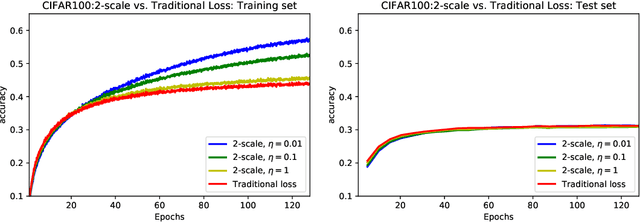
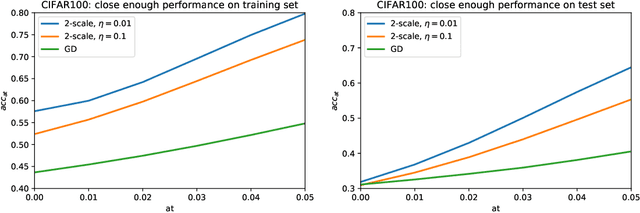
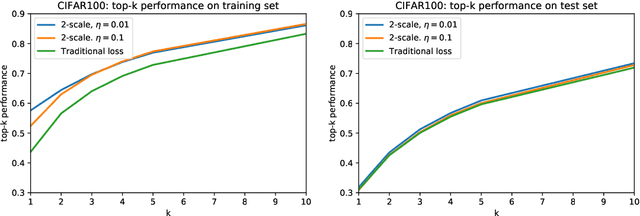
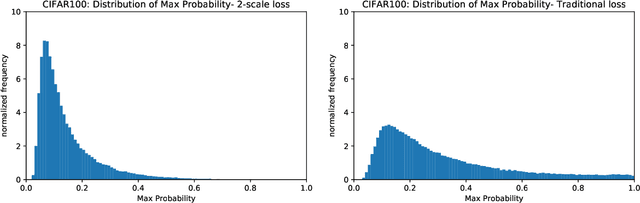
We introduce two-scale loss functions for use in various gradient descent algorithms applied to classification problems via deep neural networks. This new method is generic in the sense that it can be applied to a wide range of machine learning architectures, from deep neural networks to support vector machines for example. These two-scale loss functions allow to focus the training onto objects in the training set which are not well classified. This leads to an increase in several measures of performance for appropriately-defined two-scale loss functions with respect to the more classical cross-entropy when tested on traditional deep neural networks on the MNIST, CIFAR10, and CIFAR100 data-sets.
* 22 pages; 11 figure
View paper on