 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Accuracy in Deep Learning Using Random Matrix Theory
Oct 04, 2023In this study, we explore the applications of random matrix theory (RMT) in the training of deep neural networks (DNNs), focusing on layer pruning to simplify DNN architecture and loss landscape. RMT, recently used to address overfitting in deep learning, enables the examination of DNN's weight layer spectra. We use these techniques to optimally determine the number of singular values to be removed from the weight layers of a DNN during training via singular value decomposition (SVD). This process aids in DNN simplification and accuracy enhancement, as evidenced by training simple DNN models on the MNIST and Fashion MNIST datasets. Our method can be applied to any fully connected or convolutional layer of a pretrained DNN, decreasing the layer's parameters and simplifying the DNN architecture while preserving or even enhancing the model's accuracy. By discarding small singular values based on RMT criteria, the accuracy of the test set remains consistent, facilitating more efficient DNN training without compromising performance. We provide both theoretical and empirical evidence supporting our claim that the elimination of small singular values based on RMT does not negatively impact the DNN's accuracy. Our results offer valuable insights into the practical application of RMT for the creation of more efficient and accurate deep-learning models.
Deep Learning Weight Pruning with RMT-SVD: Increasing Accuracy and Reducing Overfitting
Mar 15, 2023

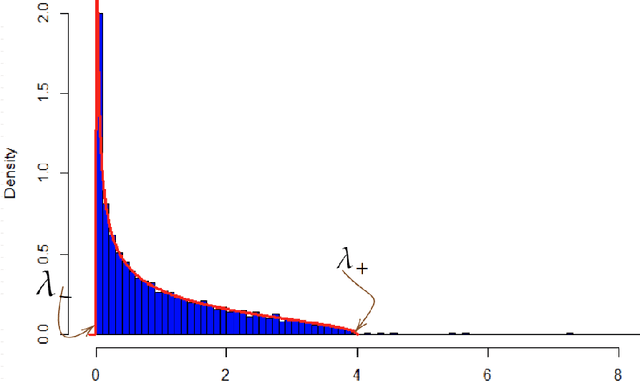

In this work, we present some applications of random matrix theory for the training of deep neural networks. Recently, random matrix theory (RMT) has been applied to the overfitting problem in deep learning. Specifically, it has been shown that the spectrum of the weight layers of a deep neural network (DNN) can be studied and understood using techniques from RMT. In this work, these RMT techniques will be used to determine which and how many singular values should be removed from the weight layers of a DNN during training, via singular value decomposition (SVD), so as to reduce overfitting and increase accuracy. We show the results on a simple DNN model trained on MNIST. In general, these techniques may be applied to any fully connected layer of a pretrained DNN to reduce the number of parameters in the layer while preserving and sometimes increasing the accuracy of the DNN.
Stability of Accuracy for the Training of DNNs Via the Uniform Doubling Condition
Oct 16, 2022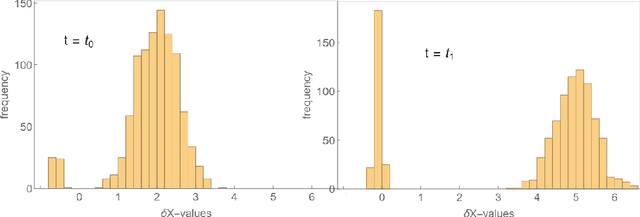


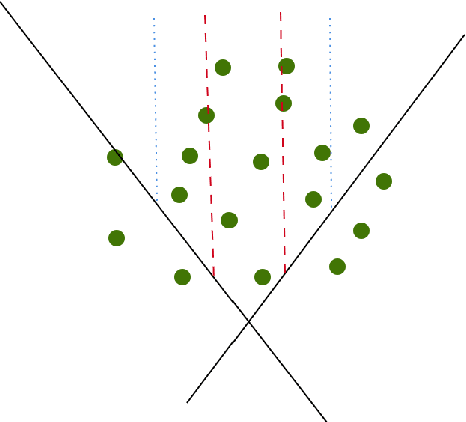
We study the stability of accuracy for the training of deep neural networks. Here the training of a DNN is preformed via the minimization of a cross-entropy loss function and the performance metric is the accuracy (the proportion of objects classified correctly). While training amounts to the decrease of loss, the accuracy does not necessarily increase during the training. A recent result by Berlyand, Jabin and Safsten introduces a doubling condition on the training data which ensures the stability of accuracy during training for DNNs with the absolute value activation function. For training data in $\R^n$, this doubling condition is formulated using slabs in $\R^n$ and it depends on the choice of the slabs. The goal of this paper is twofold. First to make the doubling condition uniform, that is independent on the choice of slabs leading to sufficient conditions for stability in terms of training data only. Second to extend the original stability results for the absolute value activation function to a broader class of piecewise linear activation function with finitely many critical points such as the popular Leaky ReLU.