 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTYolov5: A Temporal Yolov5 Detector Based on Quasi-Recurrent Neural Networks for Real-Time Handgun Detection in Video
Nov 19, 2021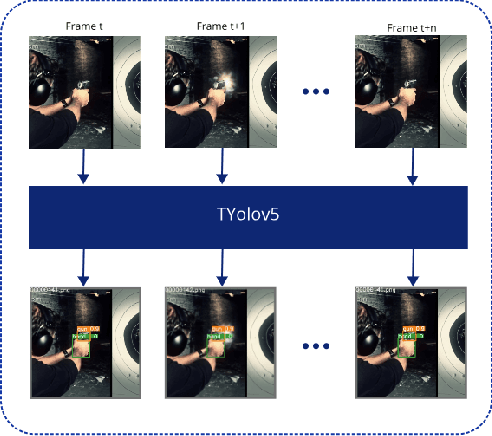
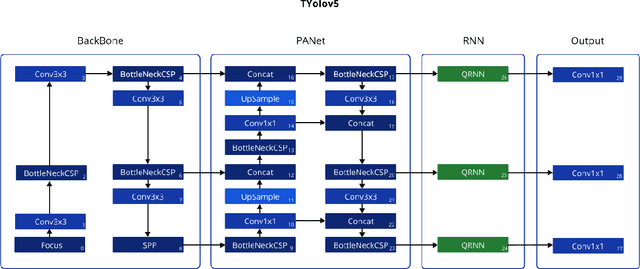
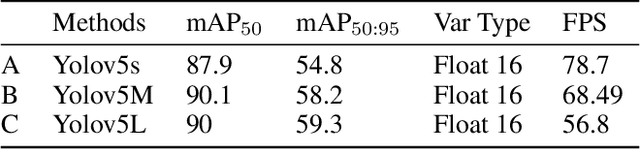
Timely handgun detection is a crucial problem to improve public safety; nevertheless, the effectiveness of many surveillance systems still depends of finite human attention. Much of the previous research on handgun detection is based on static image detectors, leaving aside valuable temporal information that could be used to improve object detection in videos. To improve the performance of surveillance systems, a real-time temporal handgun detection system should be built. Using Temporal Yolov5, an architecture based on Quasi-Recurrent Neural Networks, temporal information is extracted from video to improve the results of handgun detection. Moreover, two publicly available datasets are proposed, labeled with hands, guns, and phones. One containing 2199 static images to train static detectors, and another with 5960 frames of videos to train temporal modules. Additionally, we explore two temporal data augmentation techniques based on Mosaic and Mixup. The resulting systems are three temporal architectures: one focused in reducing inference with a mAP$_{50:95}$ of 55.9, another in having a good balance between inference and accuracy with a mAP$_{50:95}$ of 59, and a last one specialized in accuracy with a mAP$_{50:95}$ of 60.2. Temporal Yolov5 achieves real-time detection in the small and medium architectures. Moreover, it takes advantage of temporal features contained in videos to perform better than Yolov5 in our temporal dataset, making TYolov5 suitable for real-world applications. The source code is publicly available at https://github.com/MarioDuran/TYolov5.
Real-time Instance Segmentation of Surgical Instruments using Attention and Multi-scale Feature Fusion
Nov 10, 2021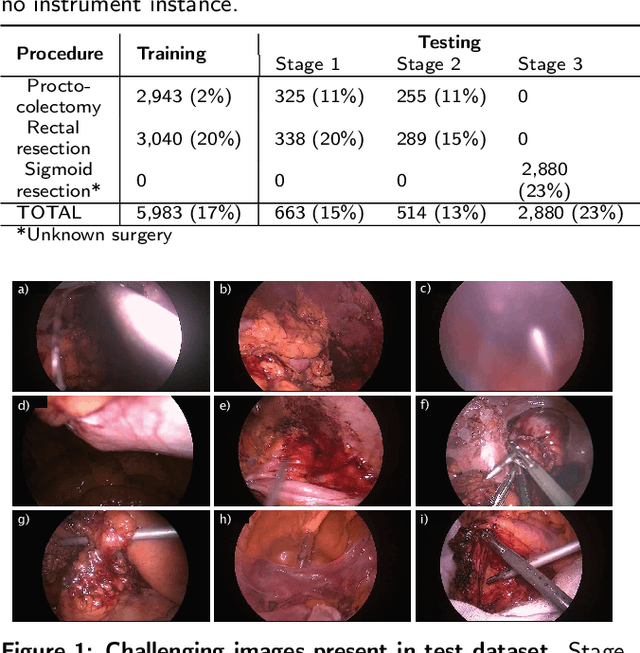


Precise instrument segmentation aid surgeons to navigate the body more easily and increase patient safety. While accurate tracking of surgical instruments in real-time plays a crucial role in minimally invasive computer-assisted surgeries, it is a challenging task to achieve, mainly due to 1) complex surgical environment, and 2) model design with both optimal accuracy and speed. Deep learning gives us the opportunity to learn complex environment from large surgery scene environments and placements of these instruments in real world scenarios. The Robust Medical Instrument Segmentation 2019 challenge (ROBUST-MIS) provides more than 10,000 frames with surgical tools in different clinical settings. In this paper, we use a light-weight single stage instance segmentation model complemented with a convolutional block attention module for achieving both faster and accurate inference. We further improve accuracy through data augmentation and optimal anchor localisation strategies. To our knowledge, this is the first work that explicitly focuses on both real-time performance and improved accuracy. Our approach out-performed top team performances in the ROBUST-MIS challenge with over 44% improvement on both area-based metric MI_DSC and distance-based metric MI_NSD. We also demonstrate real-time performance (> 60 frames-per-second) with different but competitive variants of our final approach.
Assessing YOLACT++ for real time and robust instance segmentation of medical instruments in endoscopic procedures
Mar 30, 2021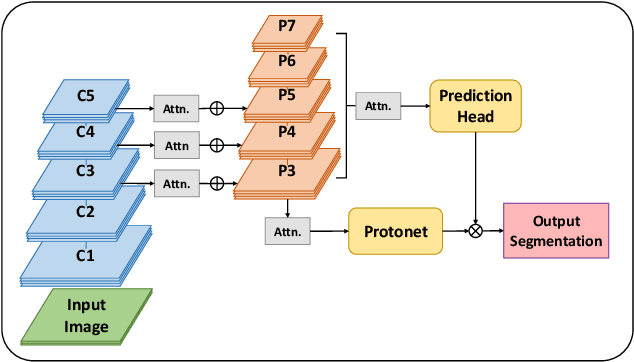
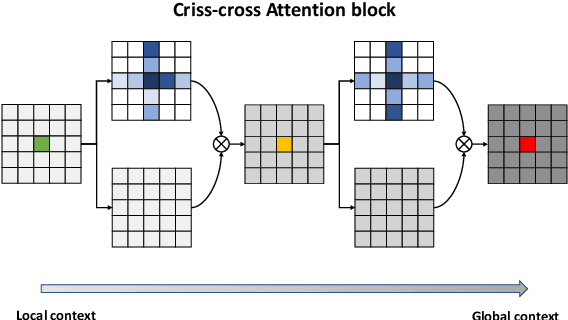
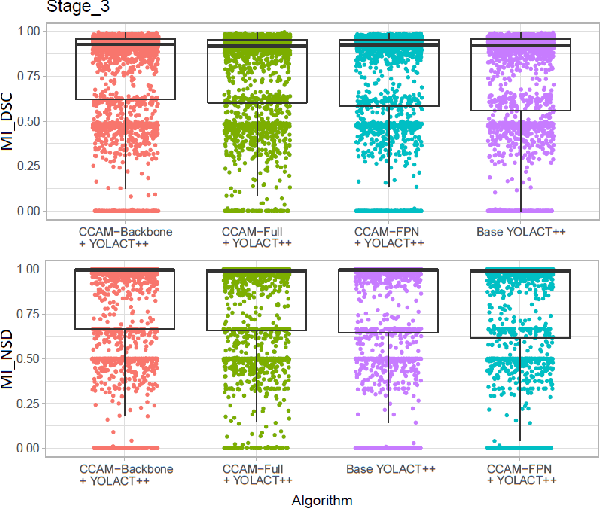
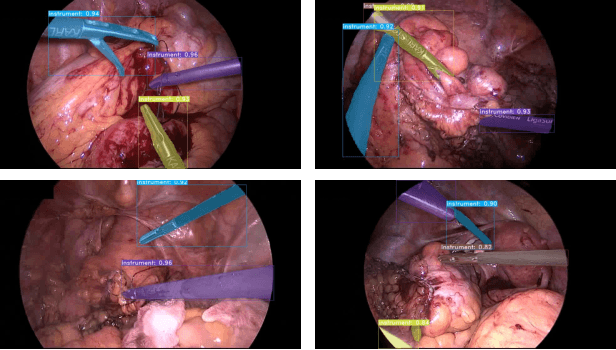
Image-based tracking of laparoscopic instruments plays a fundamental role in computer and robotic-assisted surgeries by aiding surgeons and increasing patient safety. Computer vision contests, such as the Robust Medical Instrument Segmentation (ROBUST-MIS) Challenge, seek to encourage the development of robust models for such purposes, providing large, diverse, and annotated datasets. To date, most of the existing models for instance segmentation of medical instruments were based on two-stage detectors, which provide robust results but are nowhere near to the real-time (5 frames-per-second (fps)at most). However, in order for the method to be clinically applicable, real-time capability is utmost required along with high accuracy. In this paper, we propose the addition of attention mechanisms to the YOLACT architecture that allows real-time instance segmentation of instrument with improved accuracy on the ROBUST-MIS dataset. Our proposed approach achieves competitive performance compared to the winner ofthe 2019 ROBUST-MIS challenge in terms of robustness scores,obtaining 0.313 MI_DSC and 0.338 MI_NSD, while achieving real-time performance (37 fps)
Fingerprint Presentation Attack Detection Based on Local Features Encoding for Unknown Attacks
Aug 27, 2019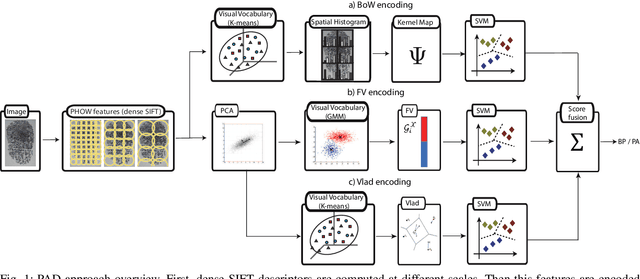
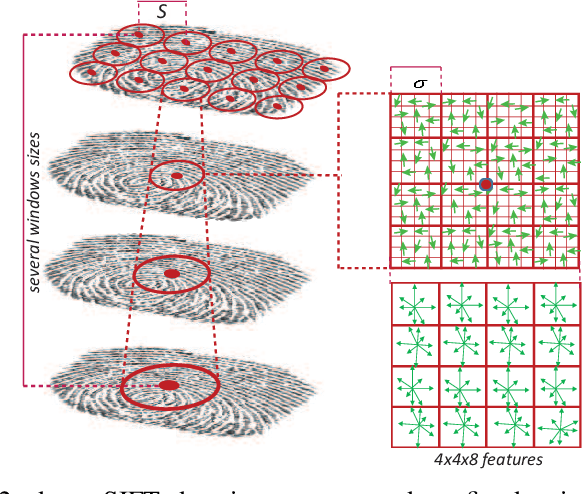
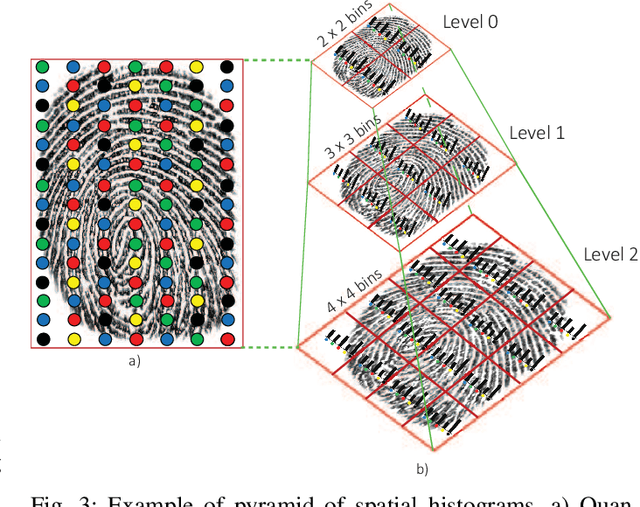
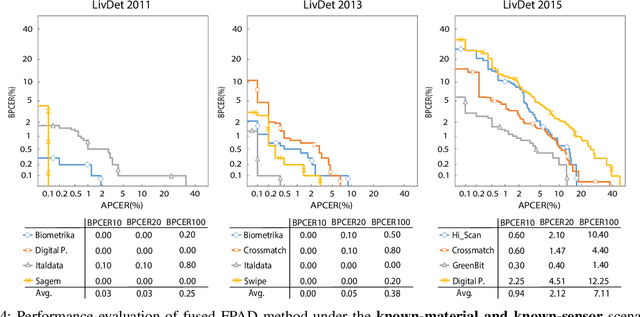
Fingerprint-based biometric systems have experienced a large development in the last years. Despite their many advantages, they are still vulnerable to presentation attacks (PAs). Therefore, the task of determining whether a sample stems from a live subject (i.e., bona fide) or from an artificial replica is a mandatory issue which has received a lot of attention recently. Nowadays, when the materials for the fabrication of the Presentation Attack Instruments (PAIs) have been used to train the PA Detection (PAD) methods, the PAIs can be successfully identified. However, current PAD methods still face difficulties detecting PAIs built from unknown materials or captured using other sensors. Based on that fact, we propose a new PAD technique based on three image representation approaches combining local and global information of the fingerprint. By transforming these representations into a common feature space, we can correctly discriminate bona fide from attack presentations in the aforementioned scenarios. The experimental evaluation of our proposal over the LivDet 2011 to 2015 databases, yielded error rates outperforming the top state-of-the-art results by up to 50\% in the most challenging scenarios. In addition, the best configuration achieved the best results in the LivDet 2019 competition (overall accuracy of 96.17\%).