 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Benefits of Word Embeddings Features for Active Learning in Clinical Information Extraction
Nov 15, 2016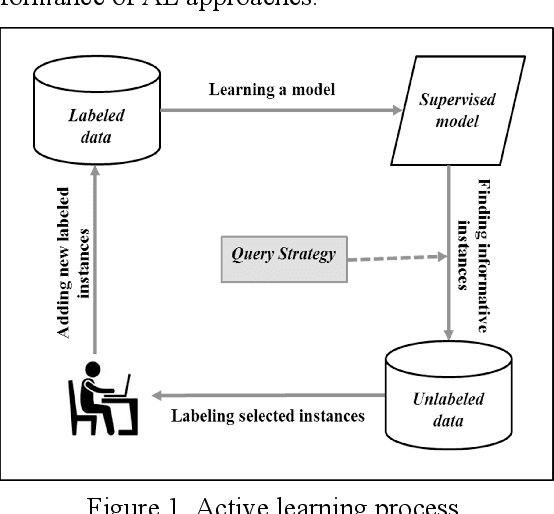
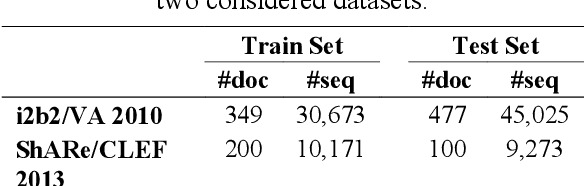
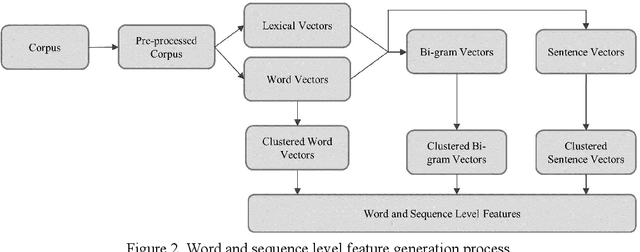
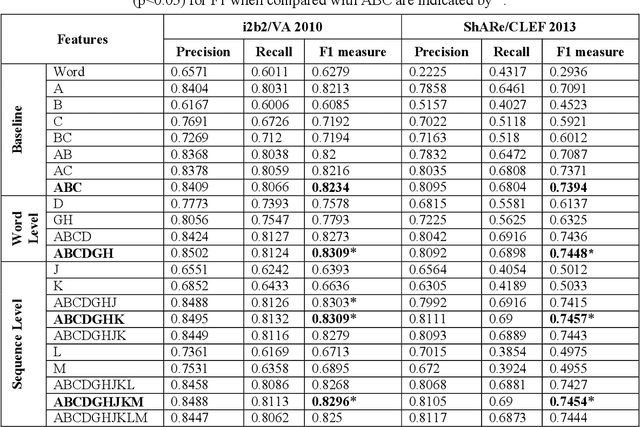
This study investigates the use of unsupervised word embeddings and sequence features for sample representation in an active learning framework built to extract clinical concepts from clinical free text. The objective is to further reduce the manual annotation effort while achieving higher effectiveness compared to a set of baseline features. Unsupervised features are derived from skip-gram word embeddings and a sequence representation approach. The comparative performance of unsupervised features and baseline hand-crafted features in an active learning framework are investigated using a wide range of selection criteria including least confidence, information diversity, information density and diversity, and domain knowledge informativeness. Two clinical datasets are used for evaluation: the i2b2/VA 2010 NLP challenge and the ShARe/CLEF 2013 eHealth Evaluation Lab. Our results demonstrate significant improvements in terms of effectiveness as well as annotation effort savings across both datasets. Using unsupervised features along with baseline features for sample representation lead to further savings of up to 9% and 10% of the token and concept annotation rates, respectively.
A probabilistic framework for analysing the compositionality of conceptual combinations
Nov 21, 2014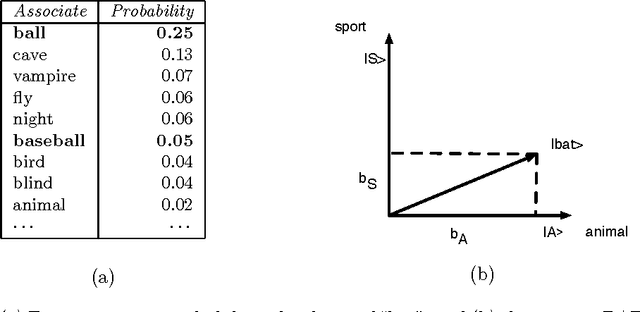
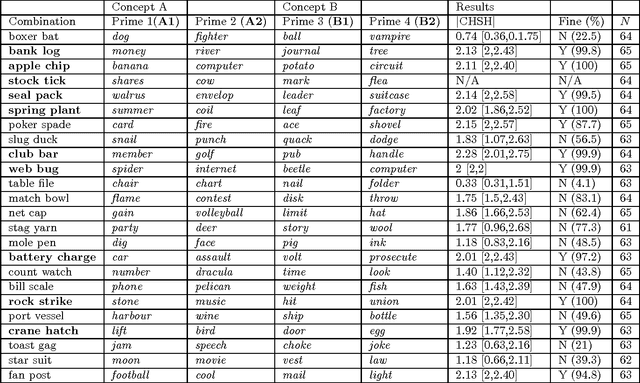
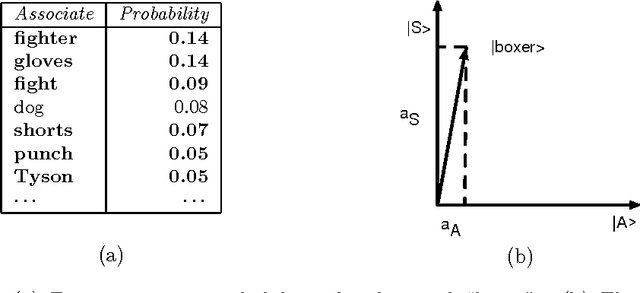

Conceptual combination performs a fundamental role in creating the broad range of compound phrases utilized in everyday language. This article provides a novel probabilistic framework for assessing whether the semantics of conceptual combinations are compositional, and so can be considered as a function of the semantics of the constituent concepts, or not. While the systematicity and productivity of language provide a strong argument in favor of assuming compositionality, this very assumption is still regularly questioned in both cognitive science and philosophy. Additionally, the principle of semantic compositionality is underspecified, which means that notions of both "strong" and "weak" compositionality appear in the literature. Rather than adjudicating between different grades of compositionality, the framework presented here contributes formal methods for determining a clear dividing line between compositional and non-compositional semantics. In addition, we suggest that the distinction between these is contextually sensitive. Utilizing formal frameworks developed for analyzing composite systems in quantum theory, we present two methods that allow the semantics of conceptual combinations to be classified as "compositional" or "non-compositional". Compositionality is first formalised by factorising the joint probability distribution modeling the combination, where the terms in the factorisation correspond to individual concepts. This leads to the necessary and sufficient condition for the joint probability distribution to exist. A failure to meet this condition implies that the underlying concepts cannot be modeled in a single probability space when considering their combination, and the combination is thus deemed "non-compositional". The formal analysis methods are demonstrated by applying them to an empirical study of twenty-four non-lexicalised conceptual combinations.