 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacter Recognition in Byzantine Seals with Deep Neural Networks
Jan 19, 2024
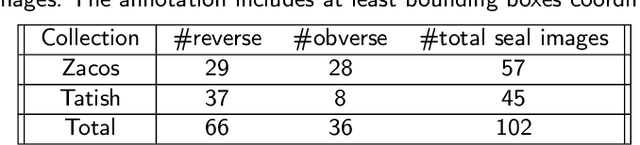


Seals are small coin-shaped artifacts, mostly made of lead, held with strings to seal letters. This work presents the first attempt towards automatic reading of text on Byzantine seal images.Byzantine seals are generally decorated with iconography on the obverse side and Greek text on the reverse side. Text may include the sender's name, position in the Byzantine aristocracy, and elements of prayers. Both text and iconography are precious literary sources that wait to be exploited electronically, so the development of computerized systems for interpreting seals images is of paramount importance. This work's contribution is hence a deep, two-stages, character reading pipeline for transcribing Byzantine seal images. A first deep convolutional neural network (CNN) detects characters in the seal (character localization). A second convolutional network reads the localized characters (character classification). Finally, a diplomatic transcription of the seal is provided by post-processing the two network outputs. We provide an experimental evaluation of each CNN in isolation and both CNNs in combination. All performances are evaluated by cross-validation. Character localization achieves a mean average precision (mAP@0.5) greater than 0.9. Classification of characters cropped from ground truth bounding boxes achieves Top-1 accuracy greater than 0.92. End-to-end evaluation shows the efficiency of the proposed approach when compared to the SoTA for similar tasks.
EMOTHAW: A novel database for emotional state recognition from handwriting
Feb 23, 2022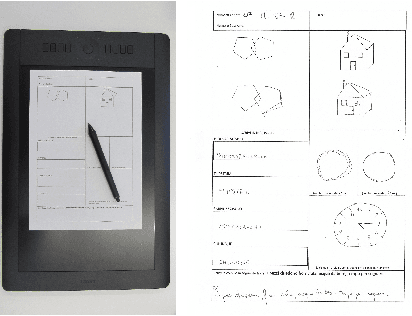
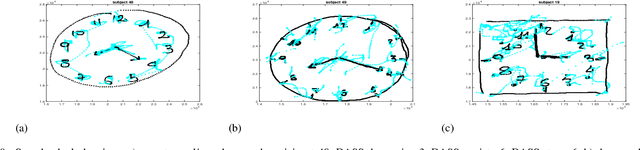


The detection of negative emotions through daily activities such as handwriting is useful for promoting well-being. The spread of human-machine interfaces such as tablets makes the collection of handwriting samples easier. In this context, we present a first publicly available handwriting database which relates emotional states to handwriting, that we call EMOTHAW. This database includes samples of 129 participants whose emotional states, namely anxiety, depression and stress, are assessed by the Depression Anxiety Stress Scales (DASS) questionnaire. Seven tasks are recorded through a digitizing tablet: pentagons and house drawing, words copied in handprint, circles and clock drawing, and one sentence copied in cursive writing. Records consist in pen positions, on-paper and in-air, time stamp, pressure, pen azimuth and altitude. We report our analysis on this database. From collected data, we first compute measurements related to timing and ductus. We compute separate measurements according to the position of the writing device: on paper or in-air. We analyse and classify this set of measurements (referred to as features) using a random forest approach. This latter is a machine learning method [2], based on an ensemble of decision trees, which includes a feature ranking process. We use this ranking process to identify the features which best reveal a targeted emotional state. We then build random forest classifiers associated to each emotional state. Our results, obtained from cross-validation experiments, show that the targeted emotional states can be identified with accuracies ranging from 60% to 71%.
* 31 pages
Handwriting Recognition of Historical Documents with few labeled data
Nov 10, 2018
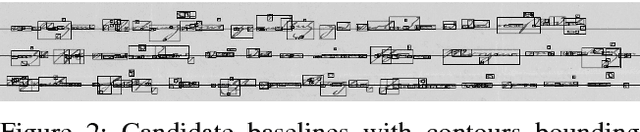

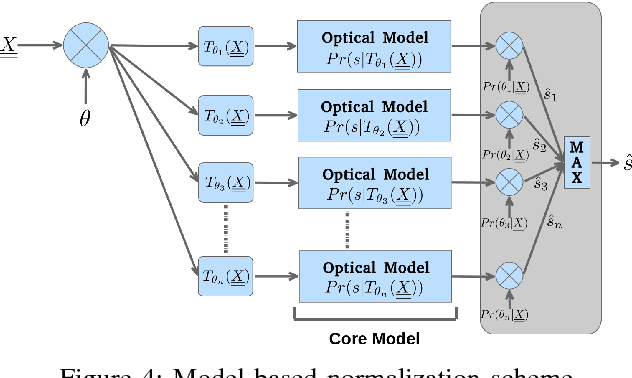
Historical documents present many challenges for offline handwriting recognition systems, among them, the segmentation and labeling steps. Carefully annotated textlines are needed to train an HTR system. In some scenarios, transcripts are only available at the paragraph level with no text-line information. In this work, we demonstrate how to train an HTR system with few labeled data. Specifically, we train a deep convolutional recurrent neural network (CRNN) system on only 10% of manually labeled text-line data from a dataset and propose an incremental training procedure that covers the rest of the data. Performance is further increased by augmenting the training set with specially crafted multiscale data. We also propose a model-based normalization scheme which considers the variability in the writing scale at the recognition phase. We apply this approach to the publicly available READ dataset. Our system achieved the second best result during the ICDAR2017 competition.
Text Line Segmentation of Historical Documents: a Survey
Apr 10, 2007
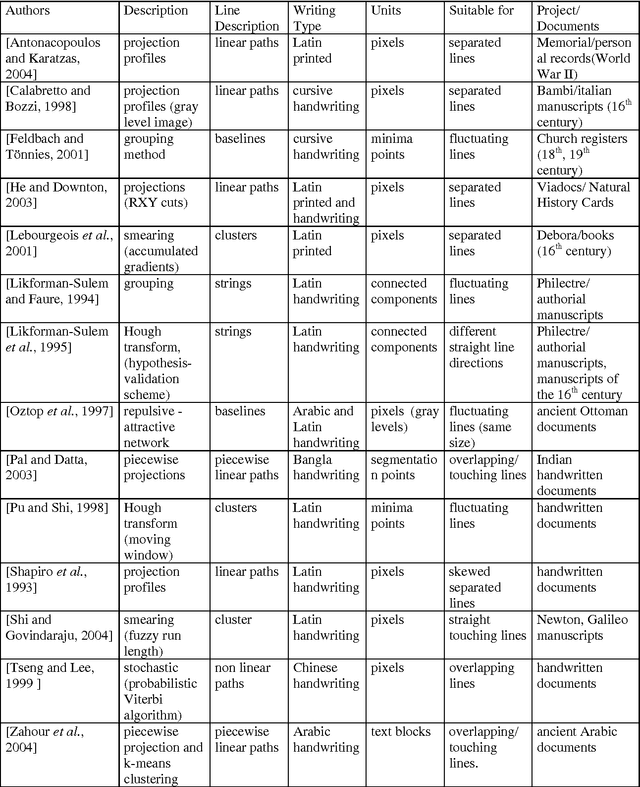

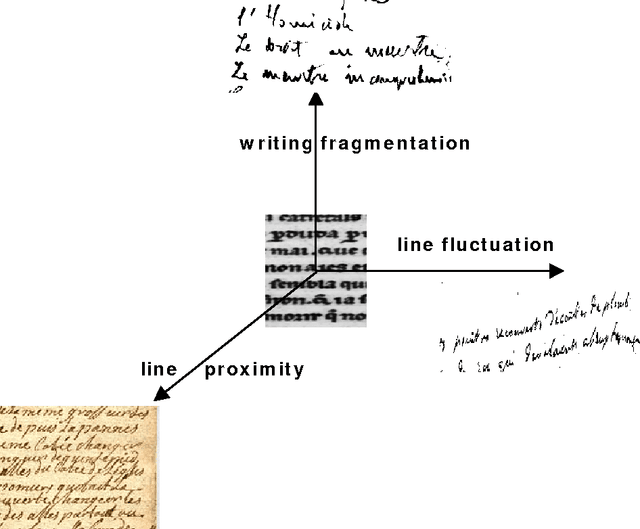
There is a huge amount of historical documents in libraries and in various National Archives that have not been exploited electronically. Although automatic reading of complete pages remains, in most cases, a long-term objective, tasks such as word spotting, text/image alignment, authentication and extraction of specific fields are in use today. For all these tasks, a major step is document segmentation into text lines. Because of the low quality and the complexity of these documents (background noise, artifacts due to aging, interfering lines),automatic text line segmentation remains an open research field. The objective of this paper is to present a survey of existing methods, developed during the last decade, and dedicated to documents of historical interest.
* 25 pages, submitted version, To appear in International Journal on Document Analysis and Recognition, On line version available at http://www.springerlink.com/content/k2813176280456k3/