 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Line Segmentation of Historical Documents: a Survey
Apr 10, 2007
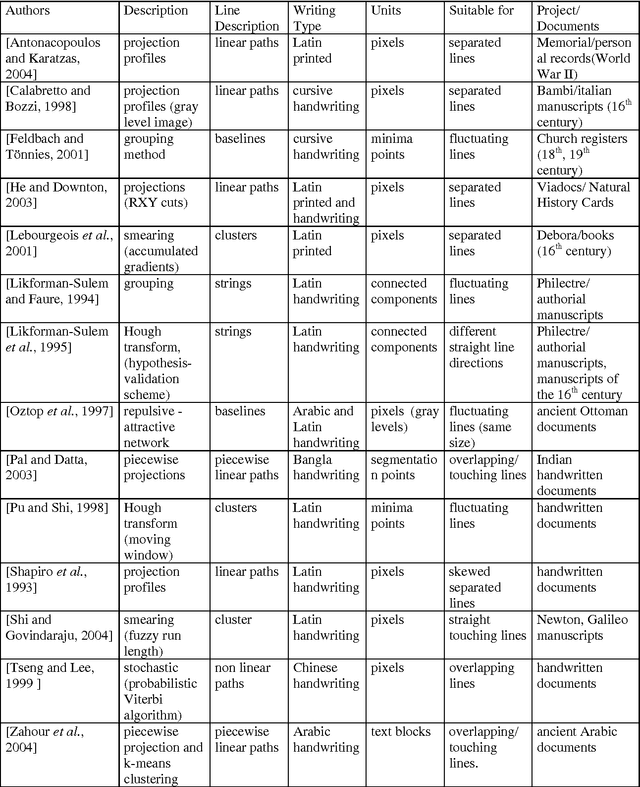

There is a huge amount of historical documents in libraries and in various National Archives that have not been exploited electronically. Although automatic reading of complete pages remains, in most cases, a long-term objective, tasks such as word spotting, text/image alignment, authentication and extraction of specific fields are in use today. For all these tasks, a major step is document segmentation into text lines. Because of the low quality and the complexity of these documents (background noise, artifacts due to aging, interfering lines),automatic text line segmentation remains an open research field. The objective of this paper is to present a survey of existing methods, developed during the last decade, and dedicated to documents of historical interest.
* 25 pages, submitted version, To appear in International Journal on Document Analysis and Recognition, On line version available at http://www.springerlink.com/content/k2813176280456k3/