 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA deep latent variable model for semi-supervised multi-unit soft sensing in industrial processes
Jul 18, 2024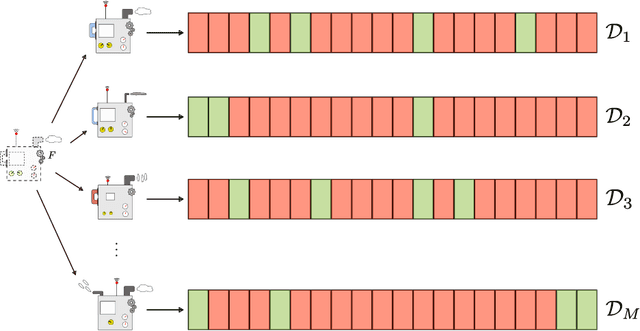
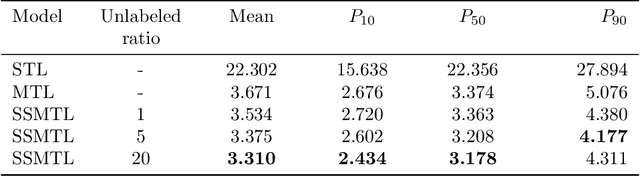
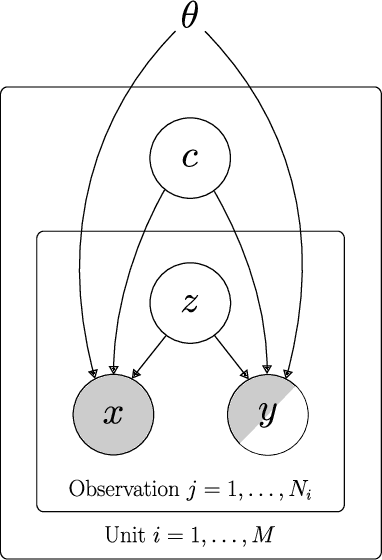
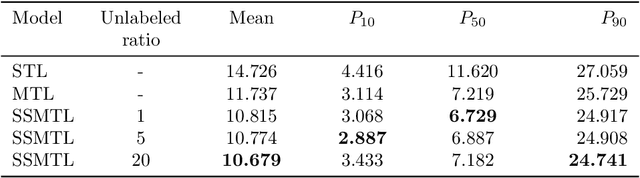
In many industrial processes, an apparent lack of data limits the development of data-driven soft sensors. There are, however, often opportunities to learn stronger models by being more data-efficient. To achieve this, one can leverage knowledge about the data from which the soft sensor is learned. Taking advantage of properties frequently possessed by industrial data, we introduce a deep latent variable model for semi-supervised multi-unit soft sensing. This hierarchical, generative model is able to jointly model different units, as well as learning from both labeled and unlabeled data. An empirical study of multi-unit soft sensing is conducted using two datasets: a synthetic dataset of single-phase fluid flow, and a large, real dataset of multi-phase flow in oil and gas wells. We show that by combining semi-supervised and multi-task learning, the proposed model achieves superior results, outperforming current leading methods for this soft sensing problem. We also show that when a model has been trained on a multi-unit dataset, it may be finetuned to previously unseen units using only a handful of data points. In this finetuning procedure, unlabeled data improve soft sensor performance; remarkably, this is true even when no labeled data are available.
Multi-unit soft sensing permits few-shot learning
Sep 27, 2023



Recent literature has explored various ways to improve soft sensors using learning algorithms with transferability. Broadly put, the performance of a soft sensor may be strengthened when it is learned by solving multiple tasks. The usefulness of transferability depends on how strongly related the devised learning tasks are. A particularly relevant case for transferability, is when a soft sensor is to be developed for a process of which there are many realizations, e.g. system or device with many implementations from which data is available. Then, each realization presents a soft sensor learning task, and it is reasonable to expect that the different tasks are strongly related. Applying transferability in this setting leads to what we call multi-unit soft sensing, where a soft sensor models a process by learning from data from all of its realizations. This paper explores the learning abilities of a multi-unit soft sensor, which is formulated as a hierarchical model and implemented using a deep neural network. In particular, we investigate how well the soft sensor generalizes as the number of units increase. Using a large industrial dataset, we demonstrate that, when the soft sensor is learned from a sufficient number of tasks, it permits few-shot learning on data from new units. Surprisingly, regarding the difficulty of the task, few-shot learning on 1-3 data points often leads to a high performance on new units.
Bayesian Neural Networks for Virtual Flow Metering: An Empirical Study
Feb 02, 2021
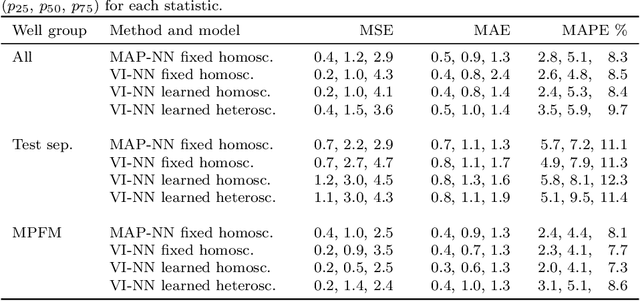
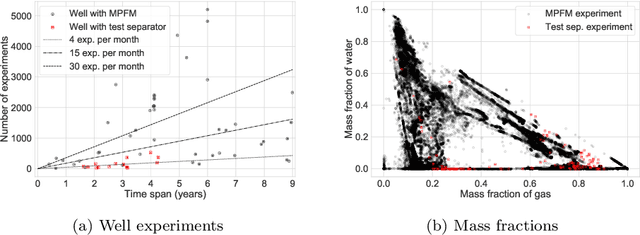
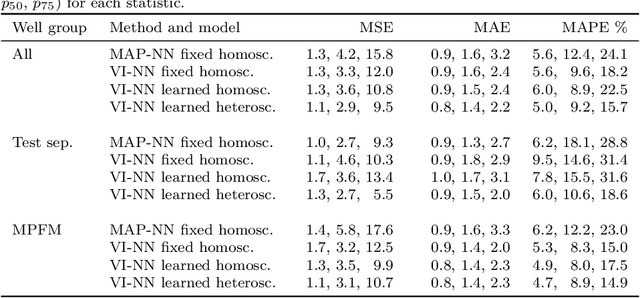
Recent works have presented promising results from the application of machine learning (ML) to the modeling of flow rates in oil and gas wells. The encouraging results combined with advantageous properties of ML models, such as computationally cheap evaluation and ease of calibration to new data, have sparked optimism for the development of data-driven virtual flow meters (VFMs). We contribute to this development by presenting a probabilistic VFM based on a Bayesian neural network. We consider homoscedastic and heteroscedastic measurement noise, and show how to train the models using maximum a posteriori estimation and variational inference. We study the methods by modeling on a large and heterogeneous dataset, consisting of 60 wells across five different oil and gas assets. The predictive performance is analyzed on historical and future test data, where we achieve an average error of 5-6% and 9-13% for the 50% best performing models, respectively. Variational inference appears to provide more robust predictions than the reference approach on future data. The difference in prediction performance and uncertainty on historical and future data is explored in detail, and the findings motivate the development of alternative strategies for data-driven VFM.