 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Monte Carlo applied to virtual flow meter calibration
Apr 13, 2023Soft-sensors are gaining popularity due to their ability to provide estimates of key process variables with little intervention required on the asset and at a low cost. In oil and gas production, virtual flow metering (VFM) is a popular soft-sensor that attempts to estimate multiphase flow rates in real time. VFMs are based on models, and these models require calibration. The calibration is highly dependent on the application, both due to the great diversity of the models, and in the available measurements. The most accurate calibration is achieved by careful tuning of the VFM parameters to well tests, but this can be work intensive, and not all wells have frequent well test data available. This paper presents a calibration method based on the measurement provided by the production separator, and the assumption that the observed flow should be equal to the sum of flow rates from each individual well. This allows us to jointly calibrate the VFMs continuously. The method applies Sequential Monte Carlo (SMC) to infer a tuning factor and the flow composition for each well. The method is tested on a case with ten wells, using both synthetic and real data. The results are promising and the method is able to provide reasonable estimates of the parameters without relying on well tests. However, some challenges are identified and discussed, particularly related to the process noise and how to manage varying data quality.
Multi-task neural networks by learned contextual inputs
Mar 01, 2023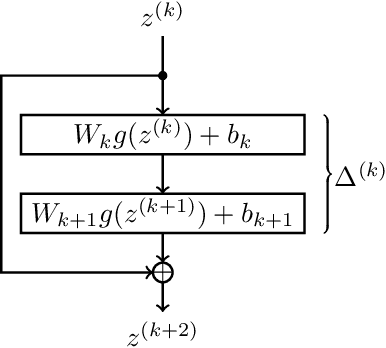
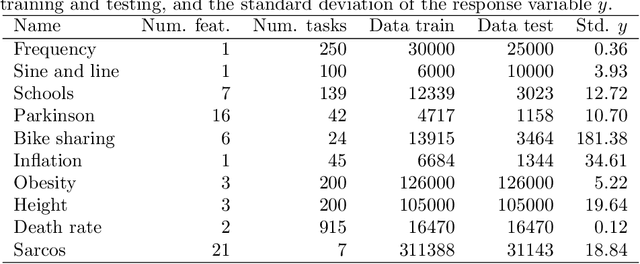
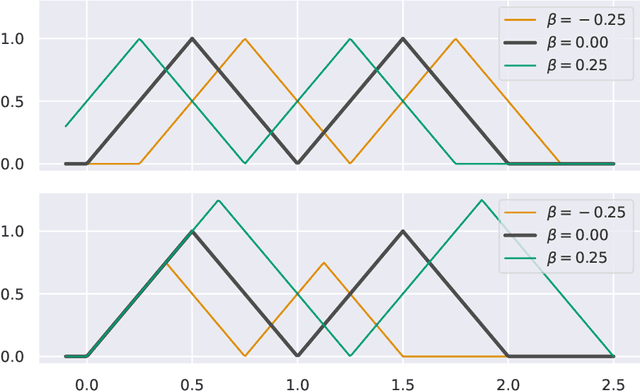
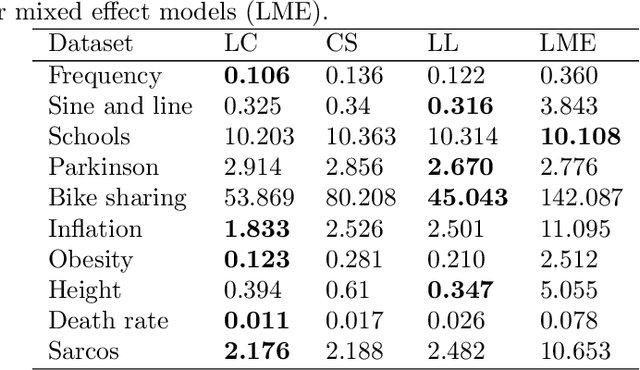
This paper explores learned-context neural networks. It is a multi-task learning architecture based on a fully shared neural network and an augmented input vector containing trainable task parameters. The architecture is interesting due to its powerful task adaption mechanism, which facilitates a low-dimensional task parameter space. Theoretically, we show that a scalar task parameter is sufficient for universal approximation of all tasks, which is not necessarily the case for more common architectures. Evidence towards the practicality of such a small task parameter space is given empirically. The task parameter space is found to be well-behaved, and simplifies workflows related to updating models as new data arrives, and training new tasks when the shared parameters are frozen. Additionally, the architecture displays robustness towards cases with few data points. The architecture's performance is compared to similar neural network architectures on ten datasets.
Multi-task learning for virtual flow metering
Mar 15, 2021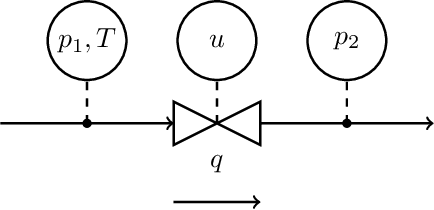
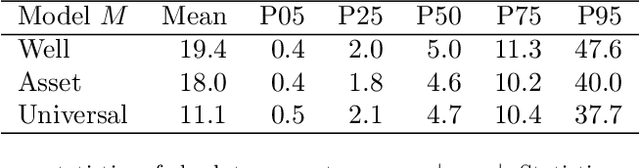
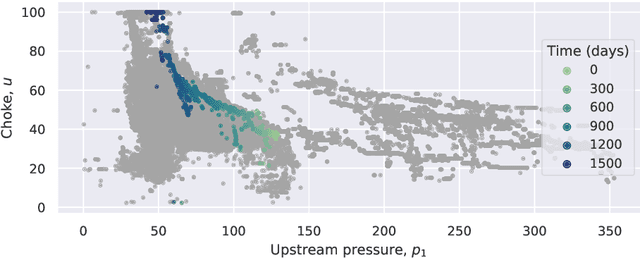
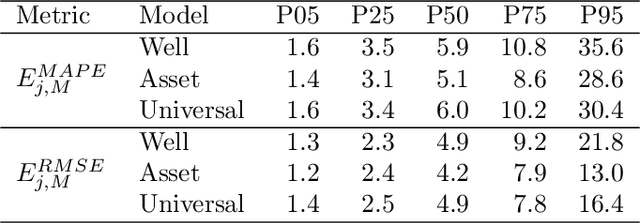
Virtual flow metering (VFM) is a cost-effective and non-intrusive technology for inferring multi-phase flow rates in petroleum assets. Inferences about flow rates are fundamental to decision support systems which operators extensively rely on. Data-driven VFM, where mechanistic models are replaced with machine learning models, has recently gained attention due to its promise of lower maintenance costs. While excellent performance in small sample studies have been reported in the literature, there is still considerable doubt towards the robustness of data-driven VFM. In this paper we propose a new multi-task learning (MTL) architecture for data-driven VFM. Our method differs from previous methods in that it enables learning across oil and gas wells. We study the method by modeling 55 wells from four petroleum assets. Our findings show that MTL improves robustness over single task methods, without sacrificing performance. MTL yields a 25-50% error reduction on average for the assets where single task architectures are struggling.
Bayesian Neural Networks for Virtual Flow Metering: An Empirical Study
Feb 02, 2021
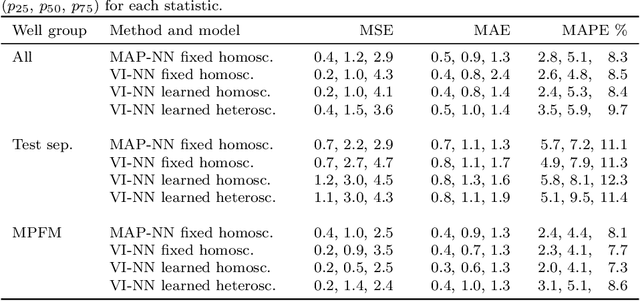
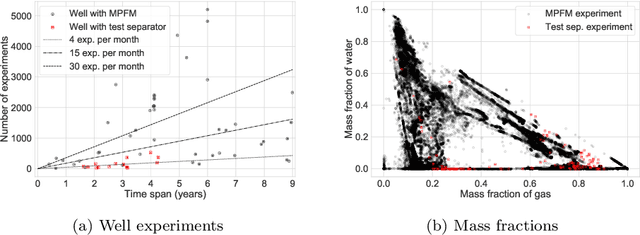
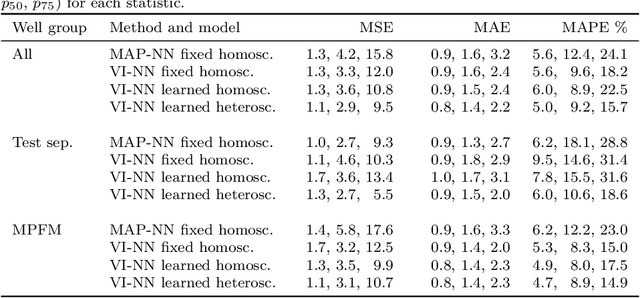
Recent works have presented promising results from the application of machine learning (ML) to the modeling of flow rates in oil and gas wells. The encouraging results combined with advantageous properties of ML models, such as computationally cheap evaluation and ease of calibration to new data, have sparked optimism for the development of data-driven virtual flow meters (VFMs). We contribute to this development by presenting a probabilistic VFM based on a Bayesian neural network. We consider homoscedastic and heteroscedastic measurement noise, and show how to train the models using maximum a posteriori estimation and variational inference. We study the methods by modeling on a large and heterogeneous dataset, consisting of 60 wells across five different oil and gas assets. The predictive performance is analyzed on historical and future test data, where we achieve an average error of 5-6% and 9-13% for the 50% best performing models, respectively. Variational inference appears to provide more robust predictions than the reference approach on future data. The difference in prediction performance and uncertainty on historical and future data is explored in detail, and the findings motivate the development of alternative strategies for data-driven VFM.