 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task neural networks by learned contextual inputs
Paper and Code
Mar 01, 2023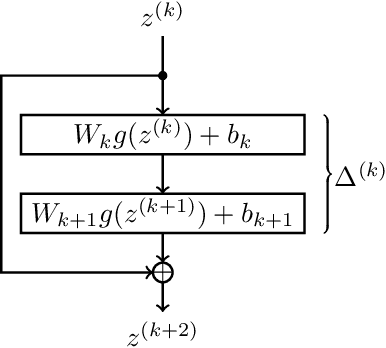
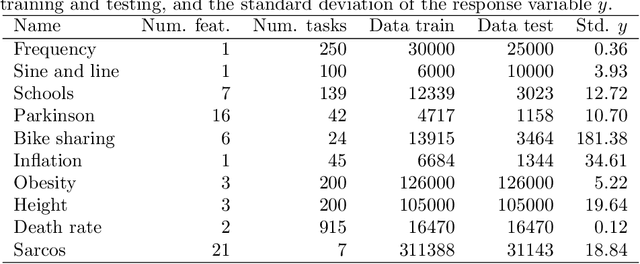
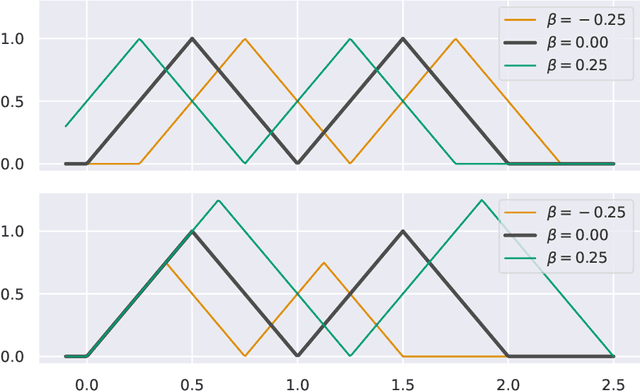
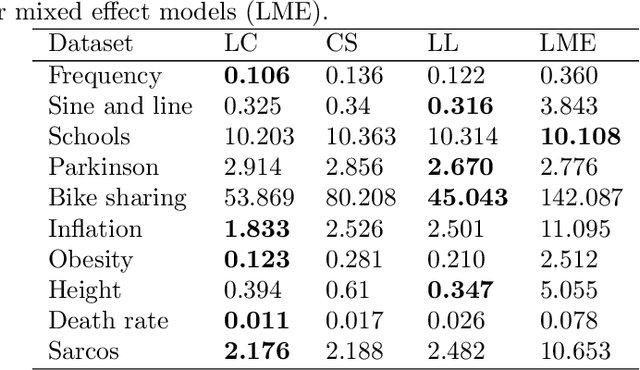
This paper explores learned-context neural networks. It is a multi-task learning architecture based on a fully shared neural network and an augmented input vector containing trainable task parameters. The architecture is interesting due to its powerful task adaption mechanism, which facilitates a low-dimensional task parameter space. Theoretically, we show that a scalar task parameter is sufficient for universal approximation of all tasks, which is not necessarily the case for more common architectures. Evidence towards the practicality of such a small task parameter space is given empirically. The task parameter space is found to be well-behaved, and simplifies workflows related to updating models as new data arrives, and training new tasks when the shared parameters are frozen. Additionally, the architecture displays robustness towards cases with few data points. The architecture's performance is compared to similar neural network architectures on ten datasets.