 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Surrogates in Conformal Inference of Individual Causal Effects
Dec 16, 2024Learning the Individual Treatment Effect (ITE) is essential for personalized decision making, yet causal inference has traditionally focused on aggregated treatment effects. While integrating conformal prediction with causal inference can provide valid uncertainty quantification for ITEs, the resulting prediction intervals are often excessively wide, limiting their practical utility. To address this limitation, we introduce \underline{S}urrogate-assisted \underline{C}onformal \underline{I}nference for \underline{E}fficient I\underline{N}dividual \underline{C}ausal \underline{E}ffects (SCIENCE), a framework designed to construct more efficient prediction intervals for ITEs. SCIENCE applies to various data configurations, including semi-supervised and surrogate-assisted semi-supervised learning. It accommodates covariate shifts between source data, which contain primary outcomes, and target data, which may include only surrogate outcomes or covariates. Leveraging semi-parametric efficiency theory, SCIENCE produces rate double-robust prediction intervals under mild rate convergence conditions, permitting the use of flexible non-parametric models to estimate nuisance functions. We quantify efficiency gains by comparing semi-parametric efficiency bounds with and without the incorporation of surrogates. Simulation studies demonstrate that our surrogate-assisted intervals offer substantial efficiency improvements over existing methods while maintaining valid group-conditional coverage. Applied to the phase 3 Moderna COVE COVID-19 vaccine trial, SCIENCE illustrates how multiple surrogate markers can be leveraged to generate more efficient prediction intervals.
Multi-Source Conformal Inference Under Distribution Shift
May 15, 2024



Recent years have experienced increasing utilization of complex machine learning models across multiple sources of data to inform more generalizable decision-making. However, distribution shifts across data sources and privacy concerns related to sharing individual-level data, coupled with a lack of uncertainty quantification from machine learning predictions, make it challenging to achieve valid inferences in multi-source environments. In this paper, we consider the problem of obtaining distribution-free prediction intervals for a target population, leveraging multiple potentially biased data sources. We derive the efficient influence functions for the quantiles of unobserved outcomes in the target and source populations, and show that one can incorporate machine learning prediction algorithms in the estimation of nuisance functions while still achieving parametric rates of convergence to nominal coverage probabilities. Moreover, when conditional outcome invariance is violated, we propose a data-adaptive strategy to upweight informative data sources for efficiency gain and downweight non-informative data sources for bias reduction. We highlight the robustness and efficiency of our proposals for a variety of conformal scores and data-generating mechanisms via extensive synthetic experiments. Hospital length of stay prediction intervals for pediatric patients undergoing a high-risk cardiac surgical procedure between 2016-2022 in the U.S. illustrate the utility of our methodology.
A Transfer Learning Causal Approach to Evaluate Racial/Ethnic and Geographic Variation in Outcomes Following Congenital Heart Surgery
Mar 21, 2024Congenital heart defects (CHD) are the most prevalent birth defects in the United States and surgical outcomes vary considerably across the country. The outcomes of treatment for CHD differ for specific patient subgroups, with non-Hispanic Black and Hispanic populations experiencing higher rates of mortality and morbidity. A valid comparison of outcomes within racial/ethnic subgroups is difficult given large differences in case-mix and small subgroup sizes. We propose a causal inference framework for outcome assessment and leverage advances in transfer learning to incorporate data from both target and source populations to help estimate causal effects while accounting for different sources of risk factor and outcome differences across populations. Using the Society of Thoracic Surgeons' Congenital Heart Surgery Database (STS-CHSD), we focus on a national cohort of patients undergoing the Norwood operation from 2016-2022 to assess operative mortality and morbidity outcomes across U.S. geographic regions by race/ethnicity. We find racial and ethnic outcome differences after controlling for potential confounding factors. While geography does not have a causal effect on outcomes for non-Hispanic Caucasian patients, non-Hispanic Black patients experience wide variability in outcomes with estimated 30-day mortality ranging from 5.9% (standard error 2.2%) to 21.6% (4.4%) across U.S. regions.
Multiply Robust Federated Estimation of Targeted Average Treatment Effects
Sep 22, 2023
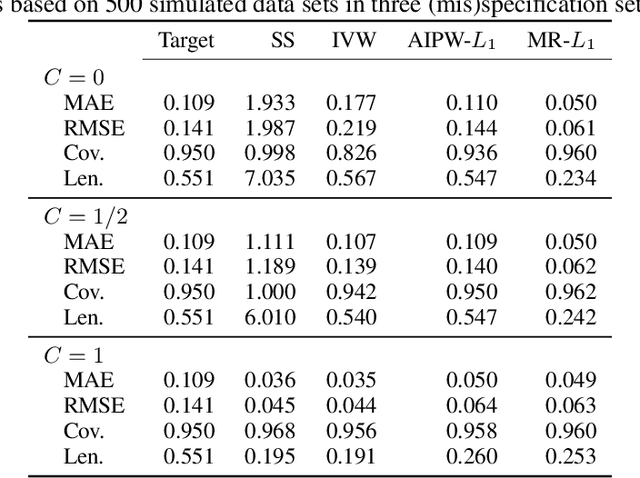


Federated or multi-site studies have distinct advantages over single-site studies, including increased generalizability, the ability to study underrepresented populations, and the opportunity to study rare exposures and outcomes. However, these studies are challenging due to the need to preserve the privacy of each individual's data and the heterogeneity in their covariate distributions. We propose a novel federated approach to derive valid causal inferences for a target population using multi-site data. We adjust for covariate shift and covariate mismatch between sites by developing multiply-robust and privacy-preserving nuisance function estimation. Our methodology incorporates transfer learning to estimate ensemble weights to combine information from source sites. We show that these learned weights are efficient and optimal under different scenarios. We showcase the finite sample advantages of our approach in terms of efficiency and robustness compared to existing approaches.