 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtein-SE(3): Benchmarking SE(3)-based Generative Models for Protein Structure Design
Jul 27, 2025SE(3)-based generative models have shown great promise in protein geometry modeling and effective structure design. However, the field currently lacks a modularized benchmark to enable comprehensive investigation and fair comparison of different methods. In this paper, we propose Protein-SE(3), a new benchmark based on a unified training framework, which comprises protein scaffolding tasks, integrated generative models, high-level mathematical abstraction, and diverse evaluation metrics. Recent advanced generative models designed for protein scaffolding, from multiple perspectives like DDPM (Genie1 and Genie2), Score Matching (FrameDiff and RfDiffusion) and Flow Matching (FoldFlow and FrameFlow) are integrated into our framework. All integrated methods are fairly investigated with the same training dataset and evaluation metrics. Furthermore, we provide a high-level abstraction of the mathematical foundations behind the generative models, enabling fast prototyping of future algorithms without reliance on explicit protein structures. Accordingly, we release the first comprehensive benchmark built upon unified training framework for SE(3)-based protein structure design, which is publicly accessible at https://github.com/BruthYU/protein-se3.
MELO: Enhancing Model Editing with Neuron-Indexed Dynamic LoRA
Dec 19, 2023Large language models (LLMs) have shown great success in various Natural Language Processing (NLP) tasks, whist they still need updates after deployment to fix errors or keep pace with the changing knowledge in the world. Researchers formulate such problem as Model Editing and have developed various editors focusing on different axes of editing properties. However, current editors can hardly support all properties and rely on heavy computational resources. In this paper, we propose a plug-in Model Editing method based on neuron-indexed dynamic LoRA (MELO), which alters the behavior of language models by dynamically activating certain LoRA blocks according to the index built in an inner vector database. Our method satisfies various editing properties with high efficiency and can be easily integrated into multiple LLM backbones. Experimental results show that our proposed MELO achieves state-of-the-art editing performance on three sequential editing tasks (document classification, question answering and hallucination correction), while requires the least trainable parameters and computational cost.
Counterfactual reasoning: Testing language models' understanding of hypothetical scenarios
May 26, 2023Current pre-trained language models have enabled remarkable improvements in downstream tasks, but it remains difficult to distinguish effects of statistical correlation from more systematic logical reasoning grounded on the understanding of real world. We tease these factors apart by leveraging counterfactual conditionals, which force language models to predict unusual consequences based on hypothetical propositions. We introduce a set of tests from psycholinguistic experiments, as well as larger-scale controlled datasets, to probe counterfactual predictions from five pre-trained language models. We find that models are consistently able to override real-world knowledge in counterfactual scenarios, and that this effect is more robust in case of stronger baseline world knowledge -- however, we also find that for most models this effect appears largely to be driven by simple lexical cues. When we mitigate effects of both world knowledge and lexical cues to test knowledge of linguistic nuances of counterfactuals, we find that only GPT-3 shows sensitivity to these nuances, though this sensitivity is also non-trivially impacted by lexical associative factors.
Counterfactual reasoning: Do language models need world knowledge for causal understanding?
Dec 06, 2022Current pre-trained language models have enabled remarkable improvements in downstream tasks, but it remains difficult to distinguish effects of statistical correlation from more systematic logical reasoning grounded on understanding of the real world. In this paper we tease these factors apart by leveraging counterfactual conditionals, which force language models to predict unusual consequences based on hypothetical propositions. We introduce a set of tests drawn from psycholinguistic experiments, as well as larger-scale controlled datasets, to probe counterfactual predictions from a variety of popular pre-trained language models. We find that models are consistently able to override real-world knowledge in counterfactual scenarios, and that this effect is more robust in case of stronger baseline world knowledge -- however, we also find that for most models this effect appears largely to be driven by simple lexical cues. When we mitigate effects of both world knowledge and lexical cues to test knowledge of linguistic nuances of counterfactuals, we find that only GPT-3 shows sensitivity to these nuances, though this sensitivity is also non-trivially impacted by lexical associative factors.
"No, they did not": Dialogue response dynamics in pre-trained language models
Oct 05, 2022



A critical component of competence in language is being able to identify relevant components of an utterance and reply appropriately. In this paper we examine the extent of such dialogue response sensitivity in pre-trained language models, conducting a series of experiments with a particular focus on sensitivity to dynamics involving phenomena of at-issueness and ellipsis. We find that models show clear sensitivity to a distinctive role of embedded clauses, and a general preference for responses that target main clause content of prior utterances. However, the results indicate mixed and generally weak trends with respect to capturing the full range of dynamics involved in targeting at-issue versus not-at-issue content. Additionally, models show fundamental limitations in grasp of the dynamics governing ellipsis, and response selections show clear interference from superficial factors that outweigh the influence of principled discourse constraints.
On the Interplay Between Fine-tuning and Composition in Transformers
Jun 01, 2021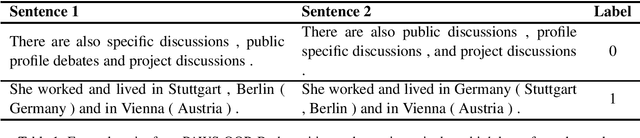

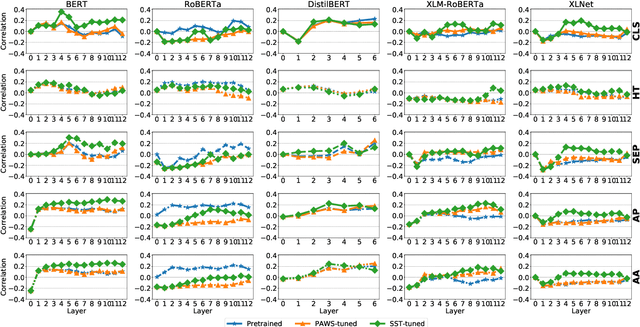
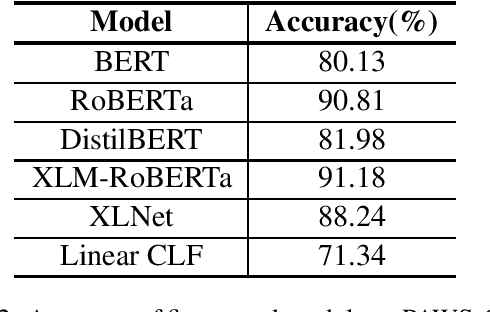
Pre-trained transformer language models have shown remarkable performance on a variety of NLP tasks. However, recent research has suggested that phrase-level representations in these models reflect heavy influences of lexical content, but lack evidence of sophisticated, compositional phrase information. Here we investigate the impact of fine-tuning on the capacity of contextualized embeddings to capture phrase meaning information beyond lexical content. Specifically, we fine-tune models on an adversarial paraphrase classification task with high lexical overlap, and on a sentiment classification task. After fine-tuning, we analyze phrasal representations in controlled settings following prior work. We find that fine-tuning largely fails to benefit compositionality in these representations, though training on sentiment yields a small, localized benefit for certain models. In follow-up analyses, we identify confounding cues in the paraphrase dataset that may explain the lack of composition benefits from that task, and we discuss potential factors underlying the localized benefits from sentiment training.
Assessing Phrasal Representation and Composition in Transformers
Oct 14, 2020
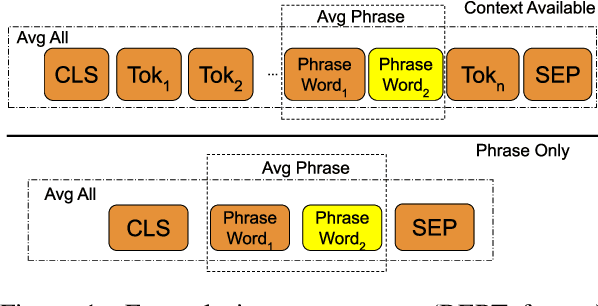

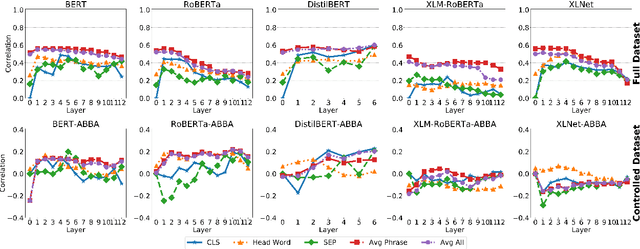
Deep transformer models have pushed performance on NLP tasks to new limits, suggesting sophisticated treatment of complex linguistic inputs, such as phrases. However, we have limited understanding of how these models handle representation of phrases, and whether this reflects sophisticated composition of phrase meaning like that done by humans. In this paper, we present systematic analysis of phrasal representations in state-of-the-art pre-trained transformers. We use tests leveraging human judgments of phrase similarity and meaning shift, and compare results before and after control of word overlap, to tease apart lexical effects versus composition effects. We find that phrase representation in these models relies heavily on word content, with little evidence of nuanced composition. We also identify variations in phrase representation quality across models, layers, and representation types, and make corresponding recommendations for usage of representations from these models.