 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted Extraction of Temporal Facts from Textual Resources for Improved Temporal Question Answering over Knowledge Bases
Mar 21, 2022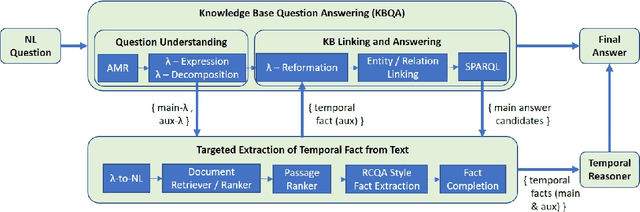
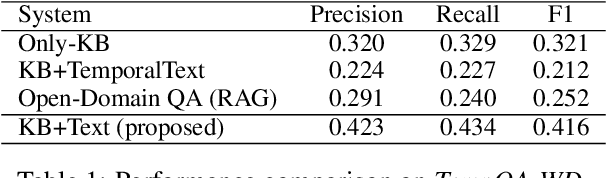
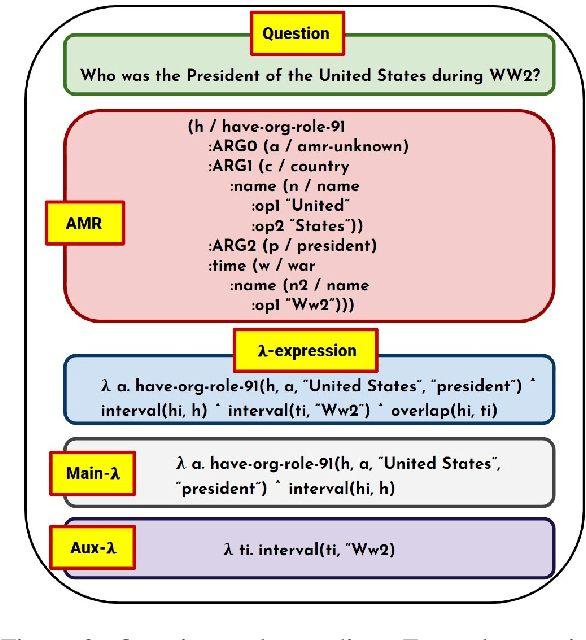
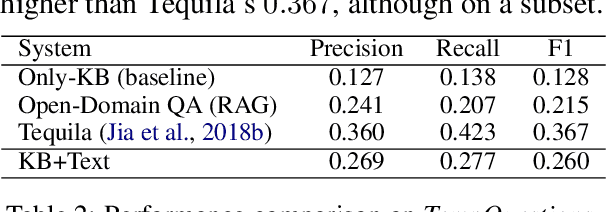
Knowledge Base Question Answering (KBQA) systems have the goal of answering complex natural language questions by reasoning over relevant facts retrieved from Knowledge Bases (KB). One of the major challenges faced by these systems is their inability to retrieve all relevant facts due to factors such as incomplete KB and entity/relation linking errors. In this paper, we address this particular challenge for systems handling a specific category of questions called temporal questions, where answer derivation involve reasoning over facts asserting point/intervals of time for various events. We propose a novel approach where a targeted temporal fact extraction technique is used to assist KBQA whenever it fails to retrieve temporal facts from the KB. We use $\lambda$-expressions of the questions to logically represent the component facts and the reasoning steps needed to derive the answer. This allows us to spot those facts that failed to get retrieved from the KB and generate textual queries to extract them from the textual resources in an open-domain question answering fashion. We evaluated our approach on a benchmark temporal question answering dataset considering Wikidata and Wikipedia respectively as the KB and textual resource. Experimental results show a significant $\sim$30\% relative improvement in answer accuracy, demonstrating the effectiveness of our approach.
A Benchmark for Generalizable and Interpretable Temporal Question Answering over Knowledge Bases
Jan 15, 2022
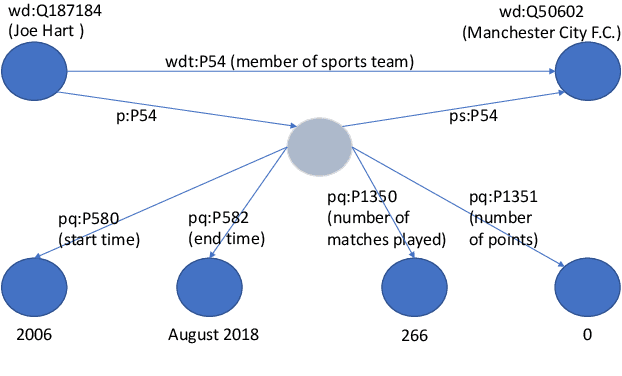


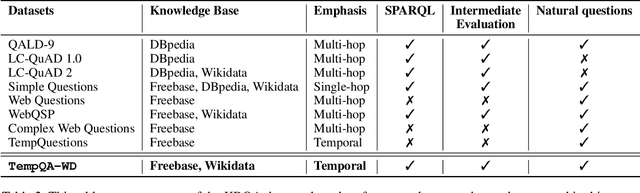
Knowledge Base Question Answering (KBQA) tasks that involve complex reasoning are emerging as an important research direction. However, most existing KBQA datasets focus primarily on generic multi-hop reasoning over explicit facts, largely ignoring other reasoning types such as temporal, spatial, and taxonomic reasoning. In this paper, we present a benchmark dataset for temporal reasoning, TempQA-WD, to encourage research in extending the present approaches to target a more challenging set of complex reasoning tasks. Specifically, our benchmark is a temporal question answering dataset with the following advantages: (a) it is based on Wikidata, which is the most frequently curated, openly available knowledge base, (b) it includes intermediate sparql queries to facilitate the evaluation of semantic parsing based approaches for KBQA, and (c) it generalizes to multiple knowledge bases: Freebase and Wikidata. The TempQA-WD dataset is available at https://github.com/IBM/tempqa-wd.
SYGMA: System for Generalizable Modular Question Answering OverKnowledge Bases
Sep 28, 2021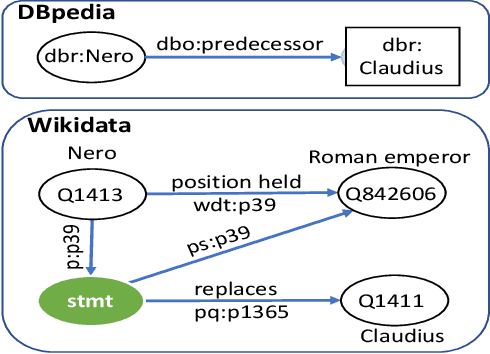


Knowledge Base Question Answering (KBQA) tasks that in-volve complex reasoning are emerging as an important re-search direction. However, most KBQA systems struggle withgeneralizability, particularly on two dimensions: (a) acrossmultiple reasoning types where both datasets and systems haveprimarily focused on multi-hop reasoning, and (b) across mul-tiple knowledge bases, where KBQA approaches are specif-ically tuned to a single knowledge base. In this paper, wepresent SYGMA, a modular approach facilitating general-izability across multiple knowledge bases and multiple rea-soning types. Specifically, SYGMA contains three high levelmodules: 1) KB-agnostic question understanding module thatis common across KBs 2) Rules to support additional reason-ing types and 3) KB-specific question mapping and answeringmodule to address the KB-specific aspects of the answer ex-traction. We demonstrate effectiveness of our system by evalu-ating on datasets belonging to two distinct knowledge bases,DBpedia and Wikidata. In addition, to demonstrate extensi-bility to additional reasoning types we evaluate on multi-hopreasoning datasets and a new Temporal KBQA benchmarkdataset on Wikidata, namedTempQA-WD1, introduced in thispaper. We show that our generalizable approach has bettercompetetive performance on multiple datasets on DBpediaand Wikidata that requires both multi-hop and temporal rea-soning