 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End Framework for Functionality-Embedded Provenance Graph Construction and Threat Interpretation
Mar 17, 2026Provenance graphs model causal system-level interactions from logs, enabling anomaly detectors to learn normal behavior and detect deviations as attacks. However, existing approaches rely on brittle, manually engineered rules to build provenance graphs, lack functional context for system entities, and provide limited support for analyst investigation. We present Auto-Prov, an adaptive, end-to-end framework that leverages large language models (LLMs) to automatically construct provenance graphs from heterogeneous and evolving logs, embed system-level functional attributes into the graph, enable provenance graph-based anomaly detectors to learn from these enriched graphs, and summarize the detected attacks to assist an analyst's investigation. Auto-Prov clusters unseen log types and efficiently extracts provenance edges and entity-level information via automatically generated rules. It further infers system-level functional context for both known and previously unseen system entities using a combination of LLM inference and behavior-based estimation. Attacks detected by provenance-graph-based anomaly detectors trained on Auto-Prov's graphs are then summarized into natural-language text. We evaluate Auto-Prov with four state-of-the-art provenance graph-based detectors across diverse logs. Results show that Auto-Prov consistently enhances detection performance, generalizes across heterogeneous log formats, and produces stable, interpretable attack summaries that remain robust under system evolution.
Unsupervised Parameter-free Outlier Detection using HDBSCAN* Outlier Profiles
Nov 13, 2024In machine learning and data mining, outliers are data points that significantly differ from the dataset and often introduce irrelevant information that can induce bias in its statistics and models. Therefore, unsupervised methods are crucial to detect outliers if there is limited or no information about them. Global-Local Outlier Scores based on Hierarchies (GLOSH) is an unsupervised outlier detection method within HDBSCAN*, a state-of-the-art hierarchical clustering method. GLOSH estimates outlier scores for each data point by comparing its density to the highest density of the region they reside in the HDBSCAN* hierarchy. GLOSH may be sensitive to HDBSCAN*'s minpts parameter that influences density estimation. With limited knowledge about the data, choosing an appropriate minpts value beforehand is challenging as one or some minpts values may better represent the underlying cluster structure than others. Additionally, in the process of searching for ``potential outliers'', one has to define the number of outliers n a dataset has, which may be impractical and is often unknown. In this paper, we propose an unsupervised strategy to find the ``best'' minpts value, leveraging the range of GLOSH scores across minpts values to identify the value for which GLOSH scores can best identify outliers from the rest of the dataset. Moreover, we propose an unsupervised strategy to estimate a threshold for classifying points into inliers and (potential) outliers without the need to pre-define any value. Our experiments show that our strategies can automatically find the minpts value and threshold that yield the best or near best outlier detection results using GLOSH.
On the combined effect of class imbalance and concept complexity in deep learning
Jul 29, 2021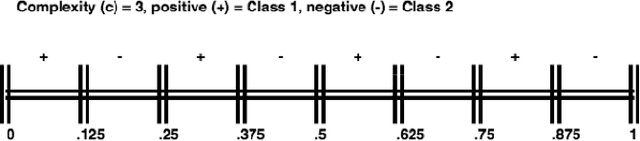
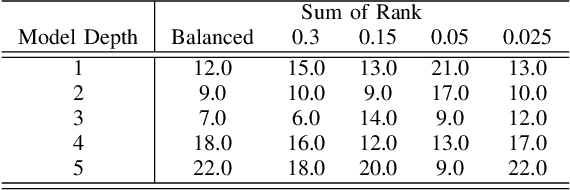
Structural concept complexity, class overlap, and data scarcity are some of the most important factors influencing the performance of classifiers under class imbalance conditions. When these effects were uncovered in the early 2000s, understandably, the classifiers on which they were demonstrated belonged to the classical rather than Deep Learning categories of approaches. As Deep Learning is gaining ground over classical machine learning and is beginning to be used in critical applied settings, it is important to assess systematically how well they respond to the kind of challenges their classical counterparts have struggled with in the past two decades. The purpose of this paper is to study the behavior of deep learning systems in settings that have previously been deemed challenging to classical machine learning systems to find out whether the depth of the systems is an asset in such settings. The results in both artificial and real-world image datasets (MNIST Fashion, CIFAR-10) show that these settings remain mostly challenging for Deep Learning systems and that deeper architectures seem to help with structural concept complexity but not with overlap challenges in simple artificial domains. Data scarcity is not overcome by deeper layers, either. In the real-world image domains, where overfitting is a greater concern than in the artificial domains, the advantage of deeper architectures is less obvious: while it is observed in certain cases, it is quickly cancelled as models get deeper and perform worse than their shallower counterparts.