 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClothFit: Cloth-Human-Attribute Guided Virtual Try-On Network Using 3D Simulated Dataset
Jun 24, 2023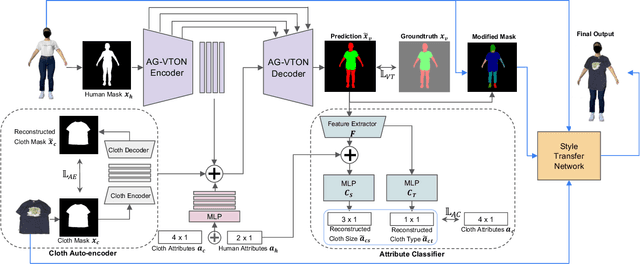
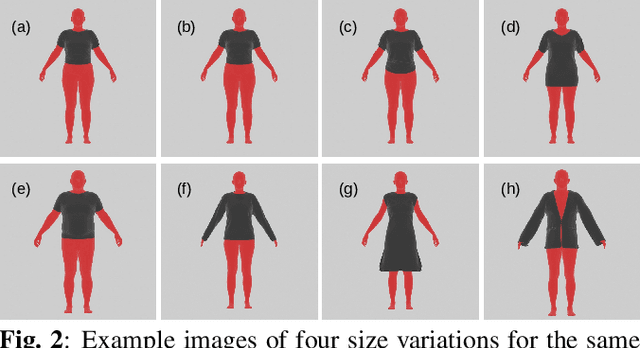

Online clothing shopping has become increasingly popular, but the high rate of returns due to size and fit issues has remained a major challenge. To address this problem, virtual try-on systems have been developed to provide customers with a more realistic and personalized way to try on clothing. In this paper, we propose a novel virtual try-on method called ClothFit, which can predict the draping shape of a garment on a target body based on the actual size of the garment and human attributes. Unlike existing try-on models, ClothFit considers the actual body proportions of the person and available cloth sizes for clothing virtualization, making it more appropriate for current online apparel outlets. The proposed method utilizes a U-Net-based network architecture that incorporates cloth and human attributes to guide the realistic virtual try-on synthesis. Specifically, we extract features from a cloth image using an auto-encoder and combine them with features from the user's height, weight, and cloth size. The features are concatenated with the features from the U-Net encoder, and the U-Net decoder synthesizes the final virtual try-on image. Our experimental results demonstrate that ClothFit can significantly improve the existing state-of-the-art methods in terms of photo-realistic virtual try-on results.
Estimation of 3D Body Shape and Clothing Measurements from Frontal- and Side-view Images
May 28, 2022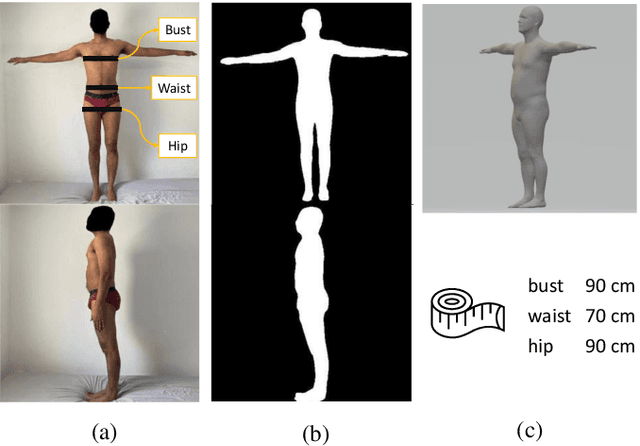
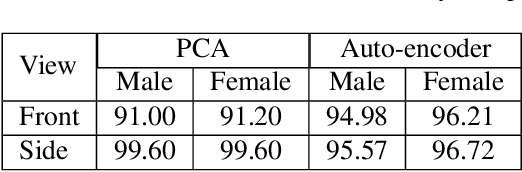
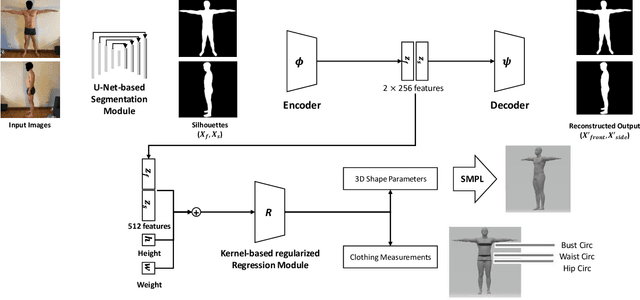
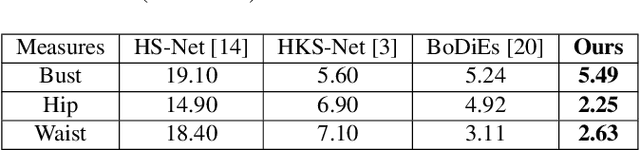
The estimation of 3D human body shape and clothing measurements is crucial for virtual try-on and size recommendation problems in the fashion industry but has always been a challenging problem due to several conditions, such as lack of publicly available realistic datasets, ambiguity in multiple camera resolutions, and the undefinable human shape space. Existing works proposed various solutions to these problems but could not succeed in the industry adaptation because of complexity and restrictions. To solve the complexity and challenges, in this paper, we propose a simple yet effective architecture to estimate both shape and measures from frontal- and side-view images. We utilize silhouette segmentation from the two multi-view images and implement an auto-encoder network to learn low-dimensional features from segmented silhouettes. Then, we adopt a kernel-based regularized regression module to estimate the body shape and measurements. The experimental results show that the proposed method provides competitive results on the synthetic dataset, NOMO-3d-400-scans Dataset, and RGB Images of humans captured in different cameras.