 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing LLMs to Capture Users' Temporal Context for Recommendation
Aug 11, 2025Effective recommender systems demand dynamic user understanding, especially in complex, evolving environments. Traditional user profiling often fails to capture the nuanced, temporal contextual factors of user preferences, such as transient short-term interests and enduring long-term tastes. This paper presents an assessment of Large Language Models (LLMs) for generating semantically rich, time-aware user profiles. We do not propose a novel end-to-end recommendation architecture; instead, the core contribution is a systematic investigation into the degree of LLM effectiveness in capturing the dynamics of user context by disentangling short-term and long-term preferences. This approach, framing temporal preferences as dynamic user contexts for recommendations, adaptively fuses these distinct contextual components into comprehensive user embeddings. The evaluation across Movies&TV and Video Games domains suggests that while LLM-generated profiles offer semantic depth and temporal structure, their effectiveness for context-aware recommendations is notably contingent on the richness of user interaction histories. Significant gains are observed in dense domains (e.g., Movies&TV), whereas improvements are less pronounced in sparse environments (e.g., Video Games). This work highlights LLMs' nuanced potential in enhancing user profiling for adaptive, context-aware recommendations, emphasizing the critical role of dataset characteristics for practical applicability.
Temporal User Profiling with LLMs: Balancing Short-Term and Long-Term Preferences for Recommendations
Aug 11, 2025Accurately modeling user preferences is crucial for improving the performance of content-based recommender systems. Existing approaches often rely on simplistic user profiling methods, such as averaging or concatenating item embeddings, which fail to capture the nuanced nature of user preference dynamics, particularly the interactions between long-term and short-term preferences. In this work, we propose LLM-driven Temporal User Profiling (LLM-TUP), a novel method for user profiling that explicitly models short-term and long-term preferences by leveraging interaction timestamps and generating natural language representations of user histories using a large language model (LLM). These representations are encoded into high-dimensional embeddings using a pre-trained BERT model, and an attention mechanism is applied to dynamically fuse the short-term and long-term embeddings into a comprehensive user profile. Experimental results on real-world datasets demonstrate that LLM-TUP achieves substantial improvements over several baselines, underscoring the effectiveness of our temporally aware user-profiling approach and the use of semantically rich user profiles, generated by LLMs, for personalized content-based recommendation.
Towards Explainable Temporal User Profiling with LLMs
May 01, 2025Accurately modeling user preferences is vital not only for improving recommendation performance but also for enhancing transparency in recommender systems. Conventional user profiling methods, such as averaging item embeddings, often overlook the evolving, nuanced nature of user interests, particularly the interplay between short-term and long-term preferences. In this work, we leverage large language models (LLMs) to generate natural language summaries of users' interaction histories, distinguishing recent behaviors from more persistent tendencies. Our framework not only models temporal user preferences but also produces natural language profiles that can be used to explain recommendations in an interpretable manner. These textual profiles are encoded via a pre-trained model, and an attention mechanism dynamically fuses the short-term and long-term embeddings into a comprehensive user representation. Beyond boosting recommendation accuracy over multiple baselines, our approach naturally supports explainability: the interpretable text summaries and attention weights can be exposed to end users, offering insights into why specific items are suggested. Experiments on real-world datasets underscore both the performance gains and the promise of generating clearer, more transparent justifications for content-based recommendations.
Beyond Static Calibration: The Impact of User Preference Dynamics on Calibrated Recommendation
May 16, 2024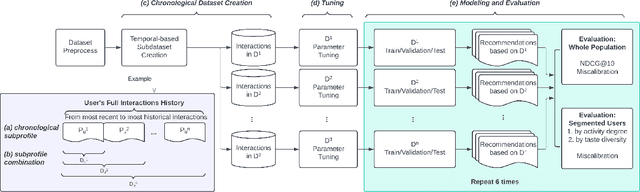

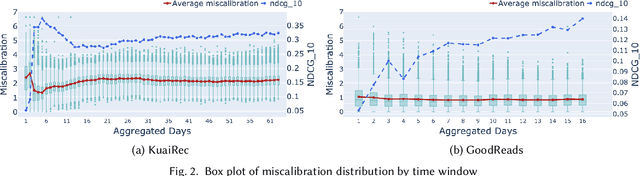
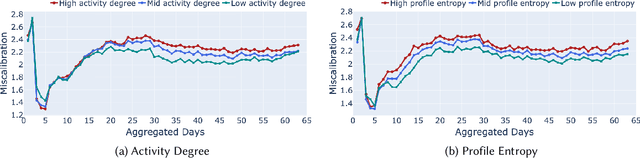
Calibration in recommender systems is an important performance criterion that ensures consistency between the distribution of user preference categories and that of recommendations generated by the system. Standard methods for mitigating miscalibration typically assume that user preference profiles are static, and they measure calibration relative to the full history of user's interactions, including possibly outdated and stale preference categories. We conjecture that this approach can lead to recommendations that, while appearing calibrated, in fact, distort users' true preferences. In this paper, we conduct a preliminary investigation of recommendation calibration at a more granular level, taking into account evolving user preferences. By analyzing differently sized training time windows from the most recent interactions to the oldest, we identify the most relevant segment of user's preferences that optimizes the calibration metric. We perform an exploratory analysis with datasets from different domains with distinctive user-interaction characteristics. We demonstrate how the evolving nature of user preferences affects recommendation calibration, and how this effect is manifested differently depending on the characteristics of the data in a given domain. Datasets, codes, and more detailed experimental results are available at: https://github.com/nicolelin13/DynamicCalibrationUMAP.
Crank up the volume: preference bias amplification in collaborative recommendation
Sep 13, 2019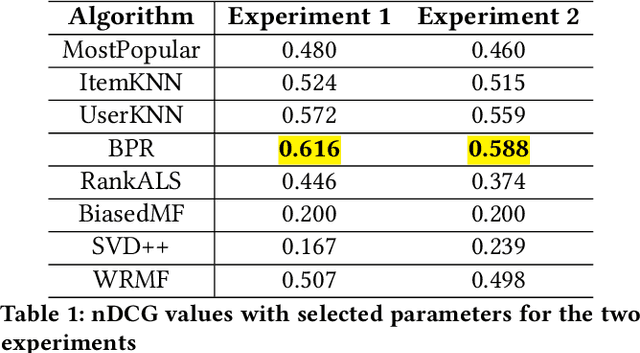
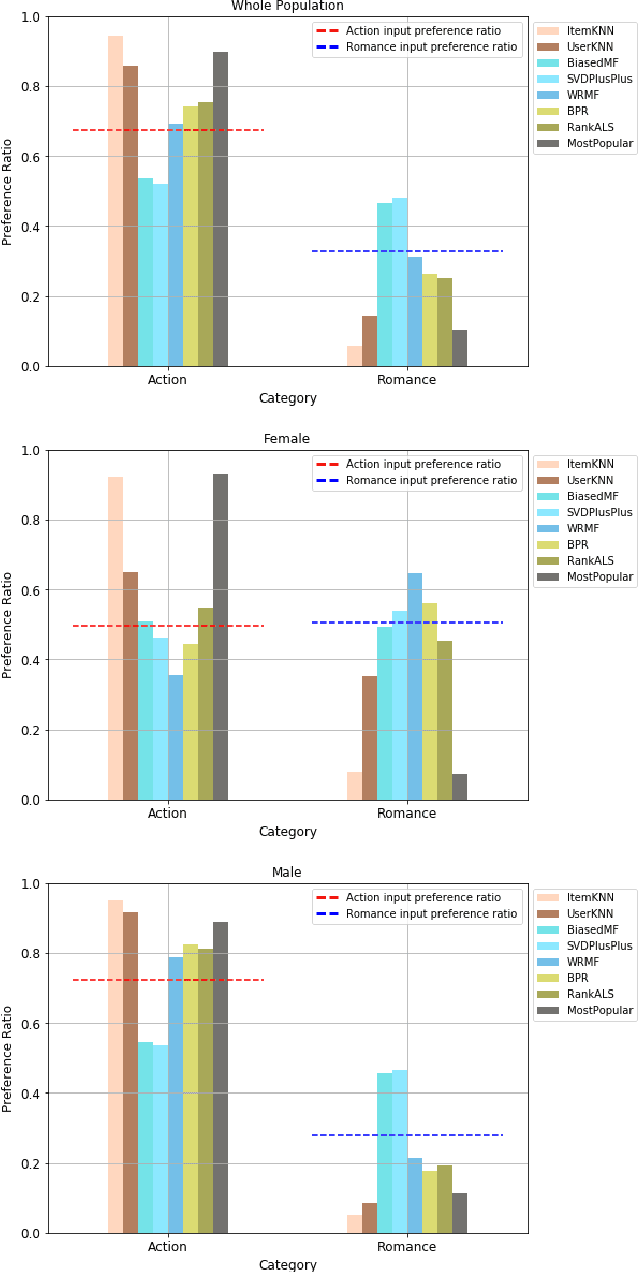

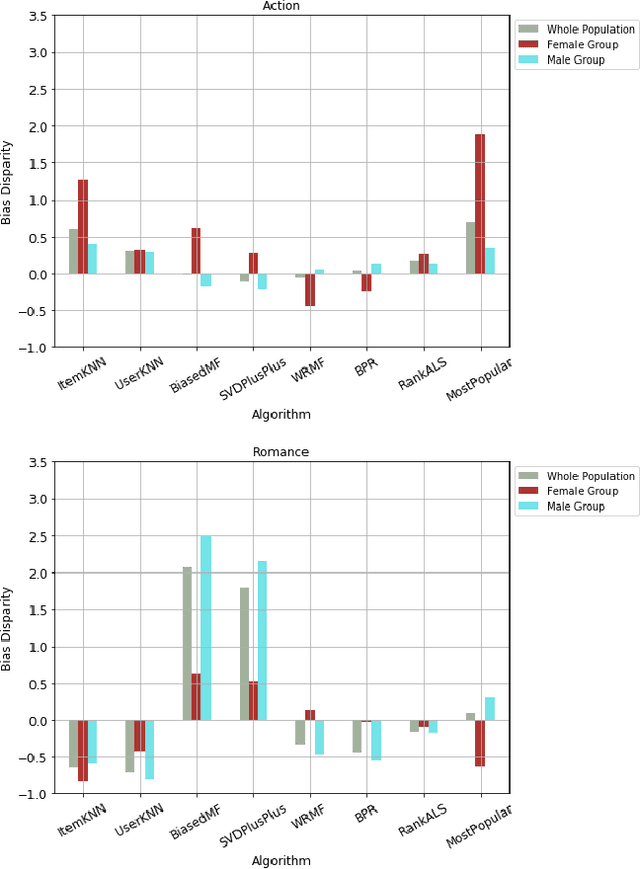
Recommender systems are personalized: we expect the results given to a particular user to reflect that user's preferences. Some researchers have studied the notion of calibration, how well recommendations match users' stated preferences, and bias disparity the extent to which mis-calibration affects different user groups. In this paper, we examine bias disparity over a range of different algorithms and for different item categories and demonstrate significant differences between model-based and memory-based algorithms.