 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackground Mixup Data Augmentation for Hand and Object-in-Contact Detection
Mar 01, 2022

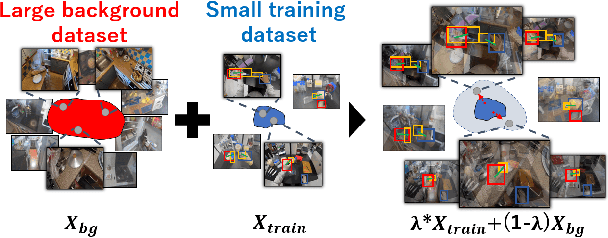
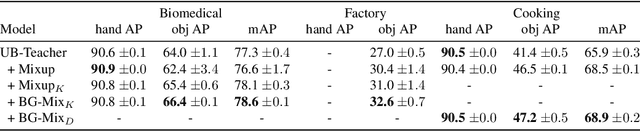
Detecting the positions of human hands and objects-in-contact (hand-object detection) in each video frame is vital for understanding human activities from videos. For training an object detector, a method called Mixup, which overlays two training images to mitigate data bias, has been empirically shown to be effective for data augmentation. However, in hand-object detection, mixing two hand-manipulation images produces unintended biases, e.g., the concentration of hands and objects in a specific region degrades the ability of the hand-object detector to identify object boundaries. We propose a data-augmentation method called Background Mixup that leverages data-mixing regularization while reducing the unintended effects in hand-object detection. Instead of mixing two images where a hand and an object in contact appear, we mix a target training image with background images without hands and objects-in-contact extracted from external image sources, and use the mixed images for training the detector. Our experiments demonstrated that the proposed method can effectively reduce false positives and improve the performance of hand-object detection in both supervised and semi-supervised learning settings.
Anime-to-Real Clothing: Cosplay Costume Generation via Image-to-Image Translation
Aug 26, 2020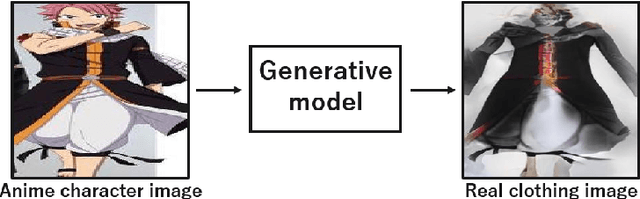


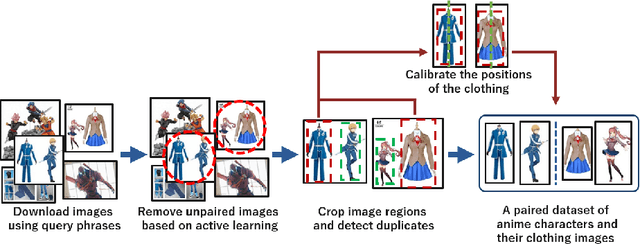
Cosplay has grown from its origins at fan conventions into a billion-dollar global dress phenomenon. To facilitate imagination and reinterpretation from animated images to real garments, this paper presents an automatic costume image generation method based on image-to-image translation. Cosplay items can be significantly diverse in their styles and shapes, and conventional methods cannot be directly applied to the wide variation in clothing images that are the focus of this study. To solve this problem, our method starts by collecting and preprocessing web images to prepare a cleaned, paired dataset of the anime and real domains. Then, we present a novel architecture for generative adversarial networks (GANs) to facilitate high-quality cosplay image generation. Our GAN consists of several effective techniques to fill the gap between the two domains and improve both the global and local consistency of generated images. Experiments demonstrated that, with two types of evaluation metrics, the proposed GAN achieves better performance than existing methods. We also showed that the images generated by the proposed method are more realistic than those generated by the conventional methods. Our codes and pretrained model are available on the web.