 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Effects and Uncertainty Quantification in Neural Actor Critic Algorithms
Jan 25, 2026We investigate the neural Actor Critic algorithm using shallow neural networks for both the Actor and Critic models. The focus of this work is twofold: first, to compare the convergence properties of the network outputs under various scaling schemes as the network width and the number of training steps tend to infinity; and second, to provide precise control of the approximation error associated with each scaling regime. Previous work has shown convergence to ordinary differential equations with random initial conditions under inverse square root scaling in the network width. In this work, we shift the focus from convergence speed alone to a more comprehensive statistical characterization of the algorithm's output, with the goal of quantifying uncertainty in neural Actor Critic methods. Specifically, we study a general inverse polynomial scaling in the network width, with an exponent treated as a tunable hyperparameter taking values strictly between one half and one. We derive an asymptotic expansion of the network outputs, interpreted as statistical estimators, in order to clarify their structure. To leading order, we show that the variance decays as a power of the network width, with an exponent equal to one half minus the scaling parameter, implying improved statistical robustness as the scaling parameter approaches one. Numerical experiments support this behavior and further suggest faster convergence for this choice of scaling. Finally, our analysis yields concrete guidelines for selecting algorithmic hyperparameters, including learning rates and exploration rates, as functions of the network width and the scaling parameter, ensuring provably favorable statistical behavior.
Global Convergence of Adjoint-Optimized Neural PDEs
Jun 16, 2025Many engineering and scientific fields have recently become interested in modeling terms in partial differential equations (PDEs) with neural networks. The resulting neural-network PDE model, being a function of the neural network parameters, can be calibrated to available data by optimizing over the PDE using gradient descent, where the gradient is evaluated in a computationally efficient manner by solving an adjoint PDE. These neural-network PDE models have emerged as an important research area in scientific machine learning. In this paper, we study the convergence of the adjoint gradient descent optimization method for training neural-network PDE models in the limit where both the number of hidden units and the training time tend to infinity. Specifically, for a general class of nonlinear parabolic PDEs with a neural network embedded in the source term, we prove convergence of the trained neural-network PDE solution to the target data (i.e., a global minimizer). The global convergence proof poses a unique mathematical challenge that is not encountered in finite-dimensional neural network convergence analyses due to (1) the neural network training dynamics involving a non-local neural network kernel operator in the infinite-width hidden layer limit where the kernel lacks a spectral gap for its eigenvalues and (2) the nonlinearity of the limit PDE system, which leads to a non-convex optimization problem, even in the infinite-width hidden layer limit (unlike in typical neual network training cases where the optimization problem becomes convex in the large neuron limit). The theoretical results are illustrated and empirically validated by numerical studies.
Convergence Analysis of Real-time Recurrent Learning (RTRL) for a class of Recurrent Neural Networks
Jan 14, 2025Recurrent neural networks (RNNs) are commonly trained with the truncated backpropagation-through-time (TBPTT) algorithm. For the purposes of computational tractability, the TBPTT algorithm truncates the chain rule and calculates the gradient on a finite block of the overall data sequence. Such approximation could lead to significant inaccuracies, as the block length for the truncated backpropagation is typically limited to be much smaller than the overall sequence length. In contrast, Real-time recurrent learning (RTRL) is an online optimization algorithm which asymptotically follows the true gradient of the loss on the data sequence as the number of sequence time steps $t \rightarrow \infty$. RTRL forward propagates the derivatives of the RNN hidden/memory units with respect to the parameters and, using the forward derivatives, performs online updates of the parameters at each time step in the data sequence. RTRL's online forward propagation allows for exact optimization over extremely long data sequences, although it can be computationally costly for models with large numbers of parameters. We prove convergence of the RTRL algorithm for a class of RNNs. The convergence analysis establishes a fixed point for the joint distribution of the data sequence, RNN hidden layer, and the RNN hidden layer forward derivatives as the number of data samples from the sequence and the number of training steps tend to infinity. We prove convergence of the RTRL algorithm to a stationary point of the loss. Numerical studies illustrate our theoretical results. One potential application area for RTRL is the analysis of financial data, which typically involve long time series and models with small to medium numbers of parameters. This makes RTRL computationally tractable and a potentially appealing optimization method for training models. Thus, we include an example of RTRL applied to limit order book data.
Kernel Limit of Recurrent Neural Networks Trained on Ergodic Data Sequences
Aug 28, 2023Mathematical methods are developed to characterize the asymptotics of recurrent neural networks (RNN) as the number of hidden units, data samples in the sequence, hidden state updates, and training steps simultaneously grow to infinity. In the case of an RNN with a simplified weight matrix, we prove the convergence of the RNN to the solution of an infinite-dimensional ODE coupled with the fixed point of a random algebraic equation. The analysis requires addressing several challenges which are unique to RNNs. In typical mean-field applications (e.g., feedforward neural networks), discrete updates are of magnitude $\mathcal{O}(\frac{1}{N})$ and the number of updates is $\mathcal{O}(N)$. Therefore, the system can be represented as an Euler approximation of an appropriate ODE/PDE, which it will converge to as $N \rightarrow \infty$. However, the RNN hidden layer updates are $\mathcal{O}(1)$. Therefore, RNNs cannot be represented as a discretization of an ODE/PDE and standard mean-field techniques cannot be applied. Instead, we develop a fixed point analysis for the evolution of the RNN memory states, with convergence estimates in terms of the number of update steps and the number of hidden units. The RNN hidden layer is studied as a function in a Sobolev space, whose evolution is governed by the data sequence (a Markov chain), the parameter updates, and its dependence on the RNN hidden layer at the previous time step. Due to the strong correlation between updates, a Poisson equation must be used to bound the fluctuations of the RNN around its limit equation. These mathematical methods give rise to the neural tangent kernel (NTK) limits for RNNs trained on data sequences as the number of data samples and size of the neural network grow to infinity.
Transport map unadjusted Langevin algorithms
Feb 28, 2023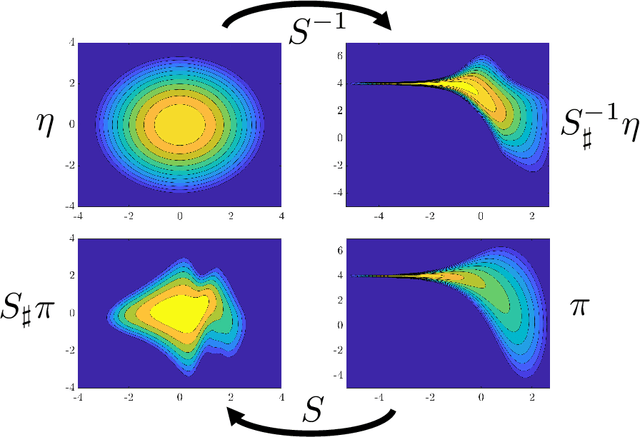
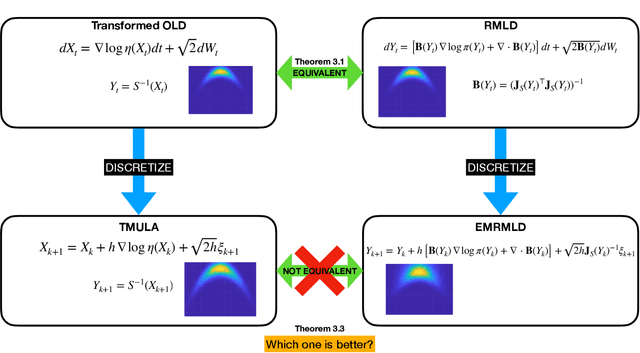
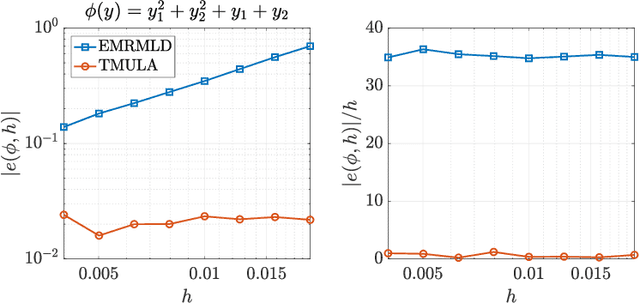
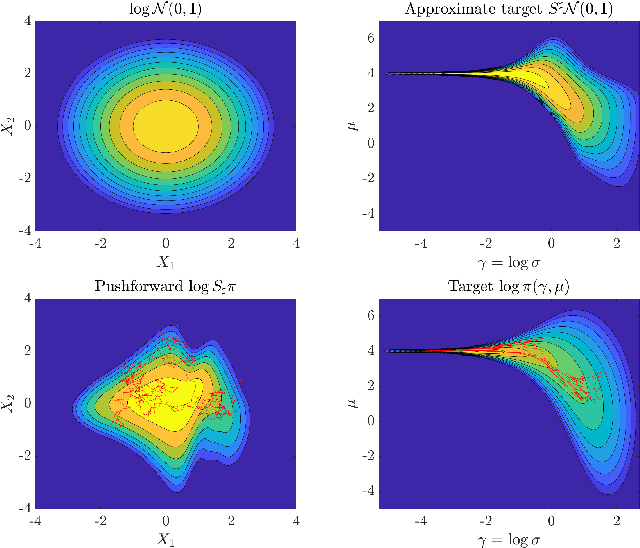
Langevin dynamics are widely used in sampling high-dimensional, non-Gaussian distributions whose densities are known up to a normalizing constant. In particular, there is strong interest in unadjusted Langevin algorithms (ULA), which directly discretize Langevin dynamics to estimate expectations over the target distribution. We study the use of transport maps that approximately normalize a target distribution as a way to precondition and accelerate the convergence of Langevin dynamics. We show that in continuous time, when a transport map is applied to Langevin dynamics, the result is a Riemannian manifold Langevin dynamics (RMLD) with metric defined by the transport map. This connection suggests more systematic ways of learning metrics, and also yields alternative discretizations of the RMLD described by the map, which we study. Moreover, we show that under certain conditions, when the transport map is used in conjunction with ULA, we can improve the geometric rate of convergence of the output process in the 2--Wasserstein distance. Illustrative numerical results complement our theoretical claims.
Normalization effects on deep neural networks
Sep 02, 2022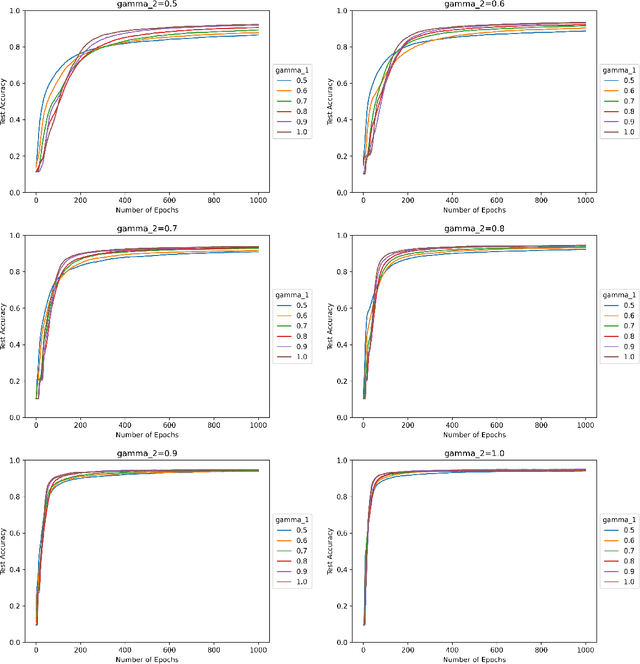
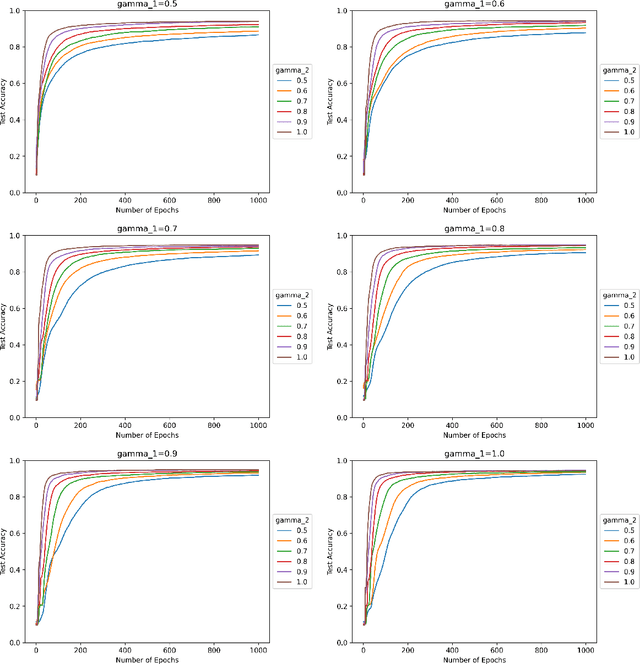
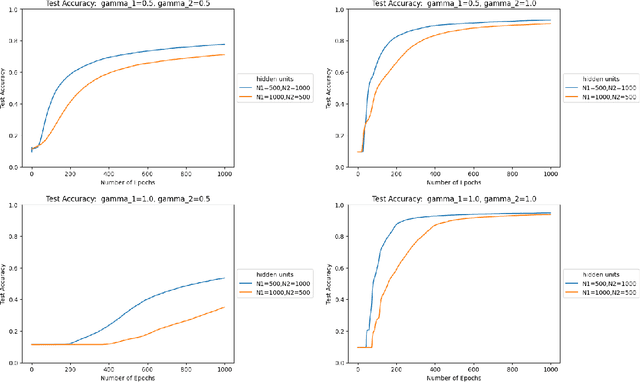
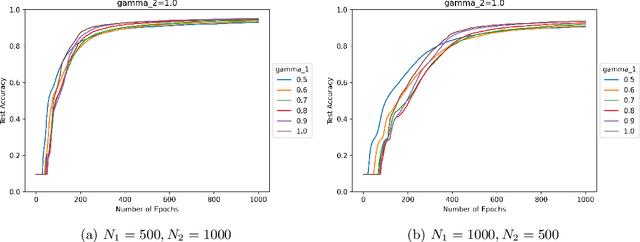
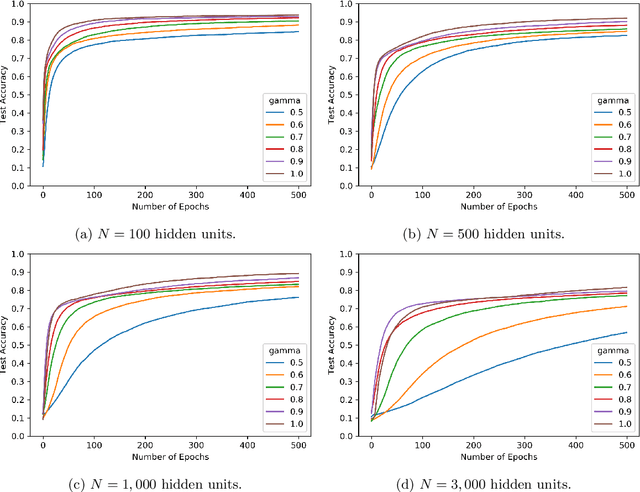
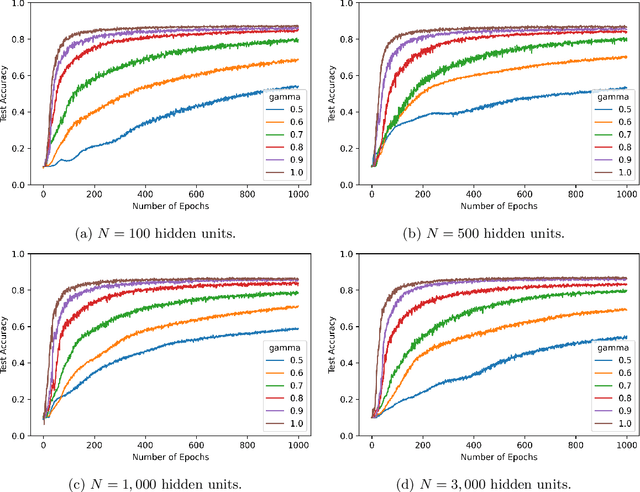
We study the effect of normalization on the layers of deep neural networks of feed-forward type. A given layer $i$ with $N_{i}$ hidden units is allowed to be normalized by $1/N_{i}^{\gamma_{i}}$ with $\gamma_{i}\in[1/2,1]$ and we study the effect of the choice of the $\gamma_{i}$ on the statistical behavior of the neural network's output (such as variance) as well as on the test accuracy on the MNIST data set. We find that in terms of variance of the neural network's output and test accuracy the best choice is to choose the $\gamma_{i}$'s to be equal to one, which is the mean-field scaling. We also find that this is particularly true for the outer layer, in that the neural network's behavior is more sensitive in the scaling of the outer layer as opposed to the scaling of the inner layers. The mechanism for the mathematical analysis is an asymptotic expansion for the neural network's output. An important practical consequence of the analysis is that it provides a systematic and mathematically informed way to choose the learning rate hyperparameters. Such a choice guarantees that the neural network behaves in a statistically robust way as the $N_i$ grow to infinity.
Geometry-informed irreversible perturbations for accelerated convergence of Langevin dynamics
Aug 18, 2021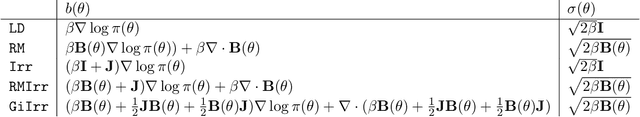

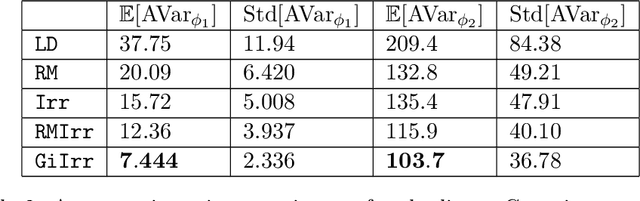
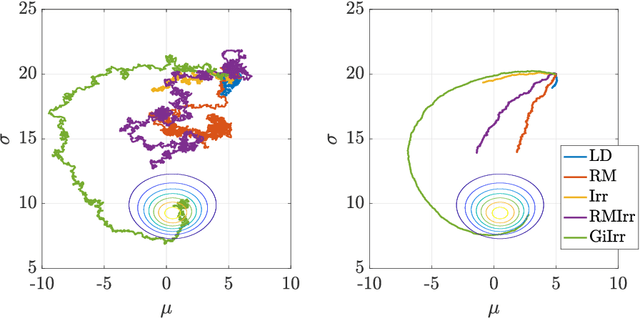
We introduce a novel geometry-informed irreversible perturbation that accelerates convergence of the Langevin algorithm for Bayesian computation. It is well documented that there exist perturbations to the Langevin dynamics that preserve its invariant measure while accelerating its convergence. Irreversible perturbations and reversible perturbations (such as Riemannian manifold Langevin dynamics (RMLD)) have separately been shown to improve the performance of Langevin samplers. We consider these two perturbations simultaneously by presenting a novel form of irreversible perturbation for RMLD that is informed by the underlying geometry. Through numerical examples, we show that this new irreversible perturbation can improve performance of the estimator over reversible perturbations that do not take the geometry into account. Moreover we demonstrate that irreversible perturbations generally can be implemented in conjunction with the stochastic gradient version of the Langevin algorithm. Lastly, while continuous-time irreversible perturbations cannot impair the performance of a Langevin estimator, the situation can sometimes be more complicated when discretization is considered. To this end, we describe a discrete-time example in which irreversibility increases both the bias and variance of the resulting estimator.
PDE-constrained Models with Neural Network Terms: Optimization and Global Convergence
May 18, 2021


Recent research has used deep learning to develop partial differential equation (PDE) models in science and engineering. The functional form of the PDE is determined by a neural network, and the neural network parameters are calibrated to available data. Calibration of the embedded neural network can be performed by optimizing over the PDE. Motivated by these applications, we rigorously study the optimization of a class of linear elliptic PDEs with neural network terms. The neural network parameters in the PDE are optimized using gradient descent, where the gradient is evaluated using an adjoint PDE. As the number of parameters become large, the PDE and adjoint PDE converge to a non-local PDE system. Using this limit PDE system, we are able to prove convergence of the neural network-PDE to a global minimum during the optimization. The limit PDE system contains a non-local linear operator whose eigenvalues are positive but become arbitrarily small. The lack of a spectral gap for the eigenvalues poses the main challenge for the global convergence proof. Careful analysis of the spectral decomposition of the coupled PDE and adjoint PDE system is required. Finally, we use this adjoint method to train a neural network model for an application in fluid mechanics, in which the neural network functions as a closure model for the Reynolds-averaged Navier-Stokes (RANS) equations. The RANS neural network model is trained on several datasets for turbulent channel flow and is evaluated out-of-sample at different Reynolds numbers.
Normalization effects on shallow neural networks and related asymptotic expansions
Nov 20, 2020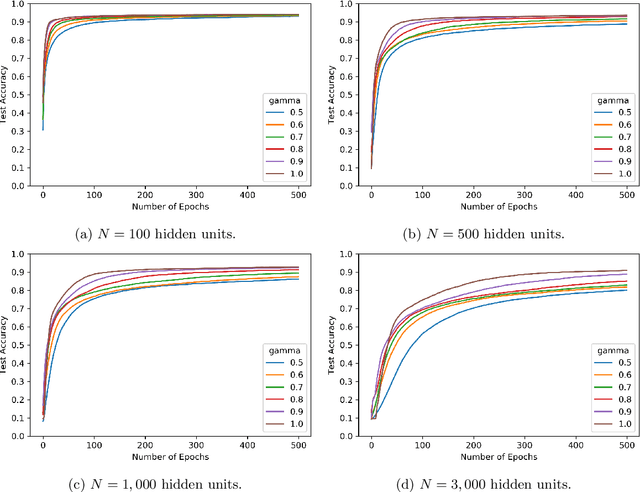
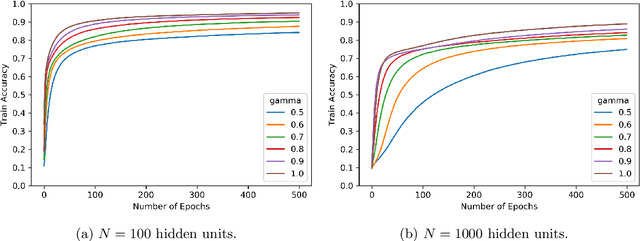
We consider shallow (single hidden layer) neural networks and characterize their performance when trained with stochastic gradient descent as the number of hidden units $N$ and gradient descent steps grow to infinity. In particular, we investigate the effect of different scaling schemes, which lead to different normalizations of the neural network, on the network's statistical output, closing the gap between the $1/\sqrt{N}$ and the mean-field $1/N$ normalization. We develop an asymptotic expansion for the neural network's statistical output pointwise with respect to the scaling parameter as the number of hidden units grows to infinity. Based on this expansion we demonstrate mathematically that to leading order in $N$ there is no bias-variance trade off, in that both bias and variance (both explicitly characterized) decrease as the number of hidden units increases and time grows. In addition, we show that to leading order in $N$, the variance of the neural network's statistical output decays as the implied normalization by the scaling parameter approaches the mean field normalization. Numerical studies on the MNIST and CIFAR10 datasets show that test and train accuracy monotonically improve as the neural network's normalization gets closer to the mean field normalization.
Asymptotics of Reinforcement Learning with Neural Networks
Nov 13, 2019We prove that a single-layer neural network trained with the Q-learning algorithm converges in distribution to a random ordinary differential equation as the size of the model and the number of training steps become large. Analysis of the limit differential equation shows that it has a unique stationary solution which is the solution of the Bellman equation, thus giving the optimal control for the problem. In addition, we study the convergence of the limit differential equation to the stationary solution. As a by-product of our analysis, we obtain the limiting behavior of single-layer neural networks when trained on i.i.d. data with stochastic gradient descent under the widely-used Xavier initialization.