 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimized Algorithms for Text Clustering with LLM-Generated Constraints
Jan 16, 2026Clustering is a fundamental tool that has garnered significant interest across a wide range of applications including text analysis. To improve clustering accuracy, many researchers have incorporated background knowledge, typically in the form of must-link and cannot-link constraints, to guide the clustering process. With the recent advent of large language models (LLMs), there is growing interest in improving clustering quality through LLM-based automatic constraint generation. In this paper, we propose a novel constraint-generation approach that reduces resource consumption by generating constraint sets rather than using traditional pairwise constraints. This approach improves both query efficiency and constraint accuracy compared to state-of-the-art methods. We further introduce a constrained clustering algorithm tailored to the characteristics of LLM-generated constraints. Our method incorporates a confidence threshold and a penalty mechanism to address potentially inaccurate constraints. We evaluate our approach on five text datasets, considering both the cost of constraint generation and the overall clustering performance. The results show that our method achieves clustering accuracy comparable to the state-of-the-art algorithms while reducing the number of LLM queries by more than 20 times.
Memorization in deep learning: A survey
Jun 06, 2024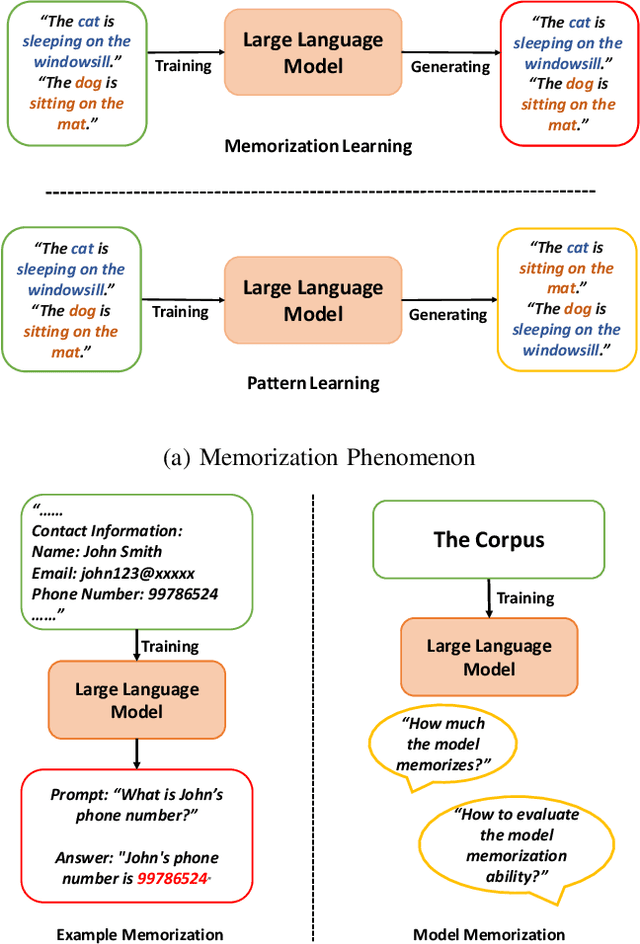
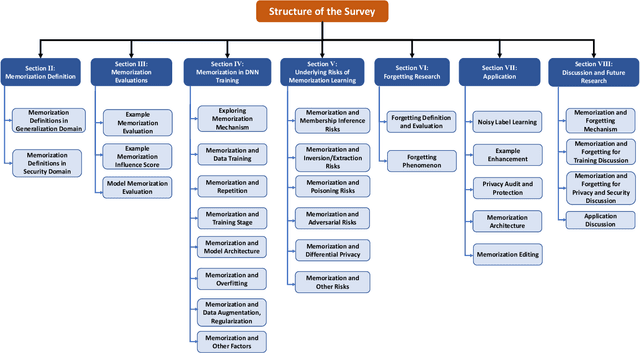
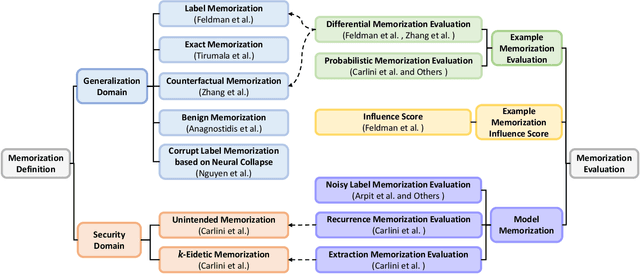
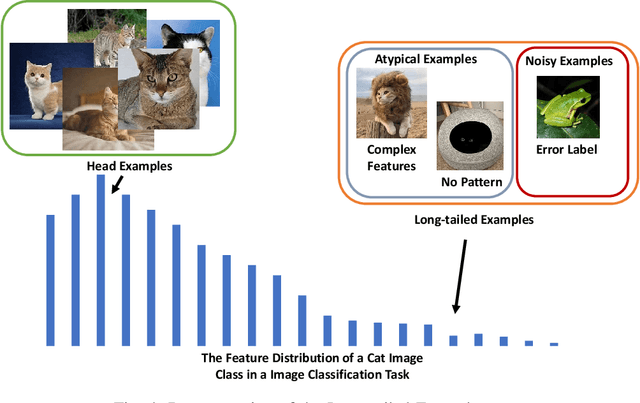
Deep Learning (DL) powered by Deep Neural Networks (DNNs) has revolutionized various domains, yet understanding the intricacies of DNN decision-making and learning processes remains a significant challenge. Recent investigations have uncovered an interesting memorization phenomenon in which DNNs tend to memorize specific details from examples rather than learning general patterns, affecting model generalization, security, and privacy. This raises critical questions about the nature of generalization in DNNs and their susceptibility to security breaches. In this survey, we present a systematic framework to organize memorization definitions based on the generalization and security/privacy domains and summarize memorization evaluation methods at both the example and model levels. Through a comprehensive literature review, we explore DNN memorization behaviors and their impacts on security and privacy. We also introduce privacy vulnerabilities caused by memorization and the phenomenon of forgetting and explore its connection with memorization. Furthermore, we spotlight various applications leveraging memorization and forgetting mechanisms, including noisy label learning, privacy preservation, and model enhancement. This survey offers the first-in-kind understanding of memorization in DNNs, providing insights into its challenges and opportunities for enhancing AI development while addressing critical ethical concerns.
Client-side Gradient Inversion Against Federated Learning from Poisoning
Sep 14, 2023



Federated Learning (FL) enables distributed participants (e.g., mobile devices) to train a global model without sharing data directly to a central server. Recent studies have revealed that FL is vulnerable to gradient inversion attack (GIA), which aims to reconstruct the original training samples and poses high risk against the privacy of clients in FL. However, most existing GIAs necessitate control over the server and rely on strong prior knowledge including batch normalization and data distribution information. In this work, we propose Client-side poisoning Gradient Inversion (CGI), which is a novel attack method that can be launched from clients. For the first time, we show the feasibility of a client-side adversary with limited knowledge being able to recover the training samples from the aggregated global model. We take a distinct approach in which the adversary utilizes a malicious model that amplifies the loss of a specific targeted class of interest. When honest clients employ the poisoned global model, the gradients of samples belonging to the targeted class are magnified, making them the dominant factor in the aggregated update. This enables the adversary to effectively reconstruct the private input belonging to other clients using the aggregated update. In addition, our CGI also features its ability to remain stealthy against Byzantine-robust aggregation rules (AGRs). By optimizing malicious updates and blending benign updates with a malicious replacement vector, our method remains undetected by these defense mechanisms. To evaluate the performance of CGI, we conduct experiments on various benchmark datasets, considering representative Byzantine-robust AGRs, and exploring diverse FL settings with different levels of adversary knowledge about the data. Our results demonstrate that CGI consistently and successfully extracts training input in all tested scenarios.
Predictive modelling of training loads and injury in Australian football
Jun 14, 2017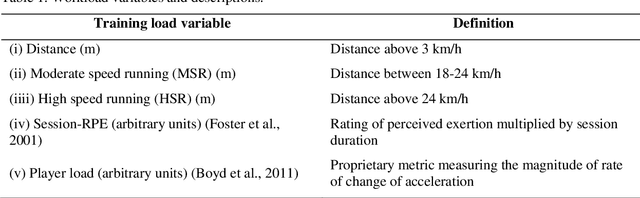

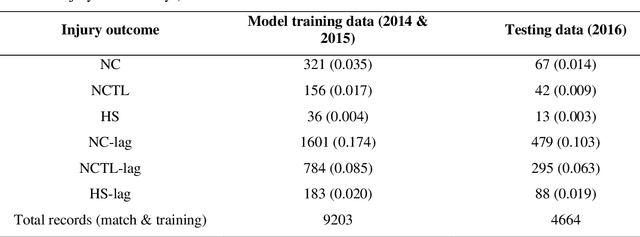
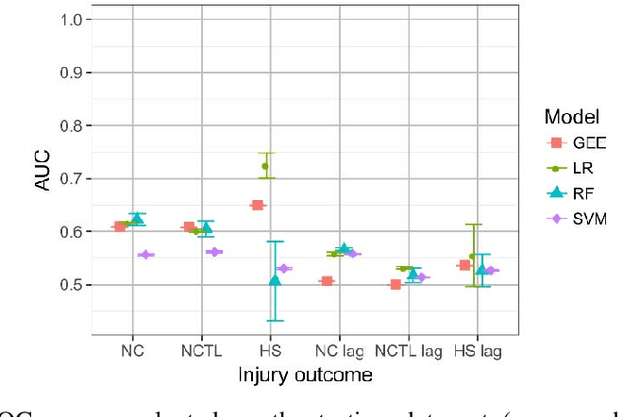
To investigate whether training load monitoring data could be used to predict injuries in elite Australian football players, data were collected from elite athletes over 3 seasons at an Australian football club. Loads were quantified using GPS devices, accelerometers and player perceived exertion ratings. Absolute and relative training load metrics were calculated for each player each day (rolling average, exponentially weighted moving average, acute:chronic workload ratio, monotony and strain). Injury prediction models (regularised logistic regression, generalised estimating equations, random forests and support vector machines) were built for non-contact, non-contact time-loss and hamstring specific injuries using the first two seasons of data. Injury predictions were generated for the third season and evaluated using the area under the receiver operator characteristic (AUC). Predictive performance was only marginally better than chance for models of non-contact and non-contact time-loss injuries (AUC$<$0.65). The best performing model was a multivariate logistic regression for hamstring injuries (best AUC=0.76). Learning curves suggested logistic regression was underfitting the load-injury relationship and that using a more complex model or increasing the amount of model building data may lead to future improvements. Injury prediction models built using training load data from a single club showed poor ability to predict injuries when tested on previously unseen data, suggesting they are limited as a daily decision tool for practitioners. Focusing the modelling approach on specific injury types and increasing the amount of training data may lead to the development of improved predictive models for injury prevention.