 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Effectiveness of Dataset Synthesis: An application of Apple Detection in Orchards
Jun 20, 2023

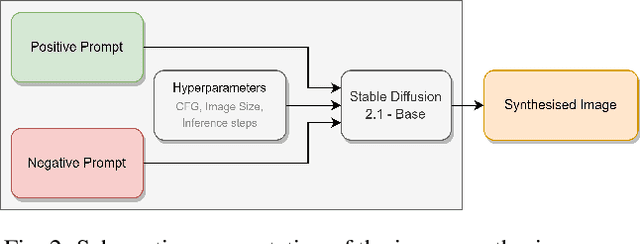

Deep object detection models have achieved notable successes in recent years, but one major obstacle remains: the requirement for a large amount of training data. Obtaining such data is a tedious process and is mainly time consuming, leading to the exploration of new research avenues like synthetic data generation techniques. In this study, we explore the usability of Stable Diffusion 2.1-base for generating synthetic datasets of apple trees for object detection and compare it to a baseline model trained on real-world data. After creating a dataset of realistic apple trees with prompt engineering and utilizing a previously trained Stable Diffusion model, the custom dataset was annotated and evaluated by training a YOLOv5m object detection model to predict apples in a real-world apple detection dataset. YOLOv5m was chosen for its rapid inference time and minimal hardware demands. Results demonstrate that the model trained on generated data is slightly underperforming compared to a baseline model trained on real-world images when evaluated on a set of real-world images. However, these findings remain highly promising, as the average precision difference is only 0.09 and 0.06, respectively. Qualitative results indicate that the model can accurately predict the location of apples, except in cases of heavy shading. These findings illustrate the potential of synthetic data generation techniques as a viable alternative to the collection of extensive training data for object detection models.
The Big Data Myth: Using Diffusion Models for Dataset Generation to Train Deep Detection Models
Jun 16, 2023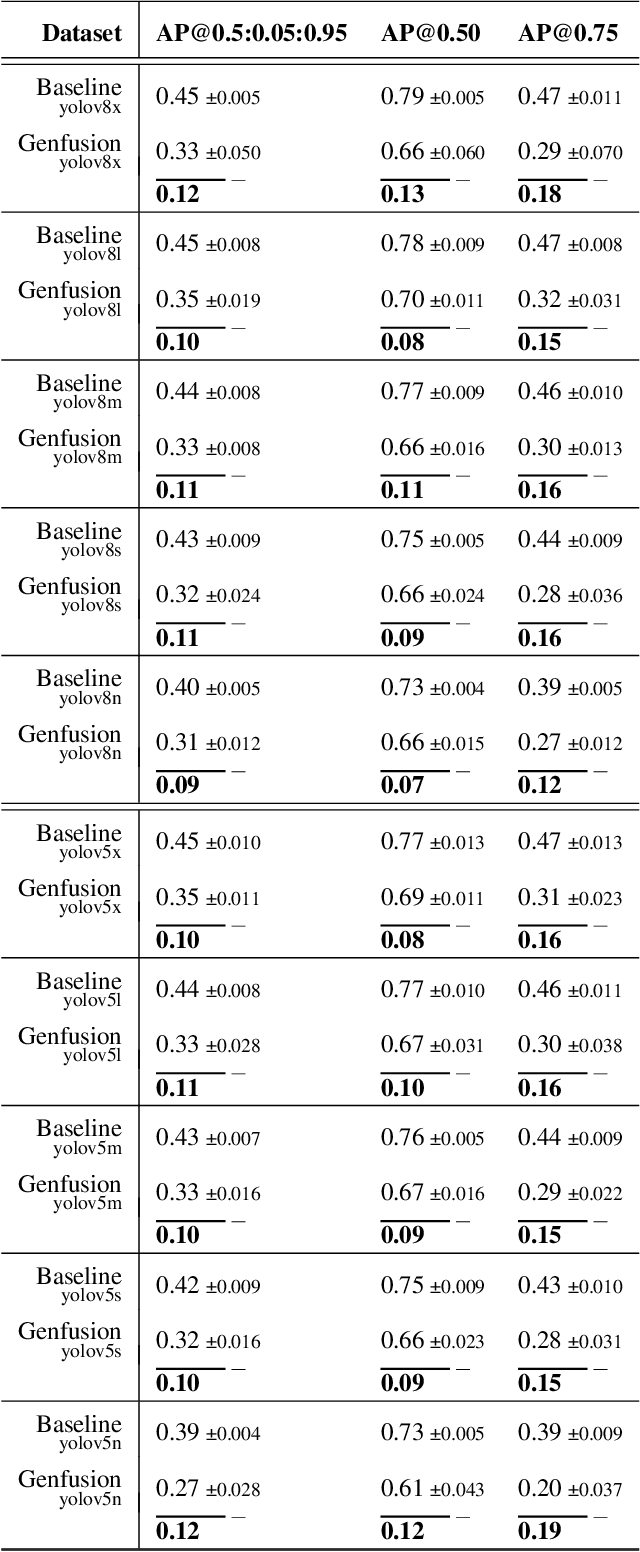

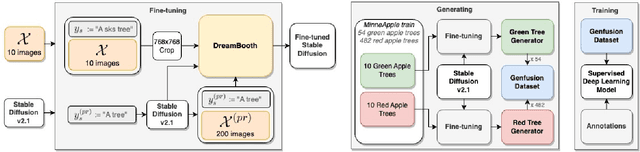
Despite the notable accomplishments of deep object detection models, a major challenge that persists is the requirement for extensive amounts of training data. The process of procuring such real-world data is a laborious undertaking, which has prompted researchers to explore new avenues of research, such as synthetic data generation techniques. This study presents a framework for the generation of synthetic datasets by fine-tuning pretrained stable diffusion models. The synthetic datasets are then manually annotated and employed for training various object detection models. These detectors are evaluated on a real-world test set of 331 images and compared against a baseline model that was trained on real-world images. The results of this study reveal that the object detection models trained on synthetic data perform similarly to the baseline model. In the context of apple detection in orchards, the average precision deviation with the baseline ranges from 0.09 to 0.12. This study illustrates the potential of synthetic data generation techniques as a viable alternative to the collection of extensive training data for the training of deep models.
Hyper-Spectral Imaging for Overlapping Plastic Flakes Segmentation
Mar 23, 2022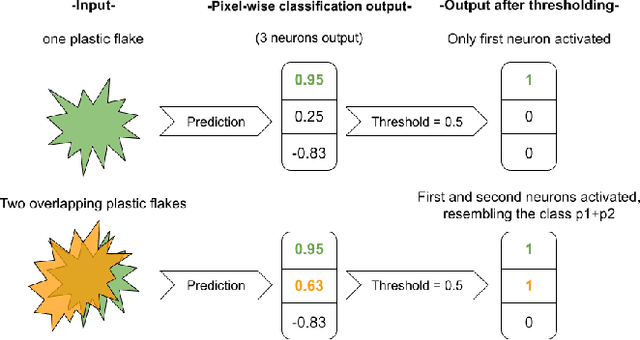
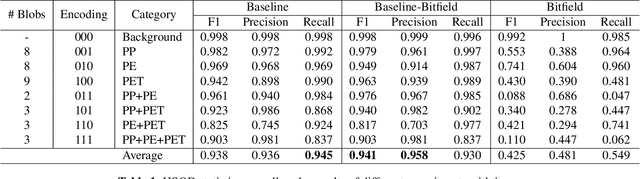

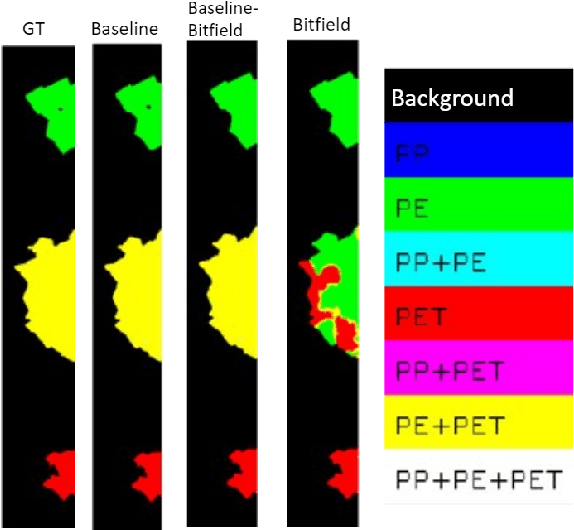
Given the hyper-spectral imaging unique potentials in grasping the polymer characteristics of different materials, it is commonly used in sorting procedures. In a practical plastic sorting scenario, multiple plastic flakes may overlap which depending on their characteristics, the overlap can be reflected in their spectral signature. In this work, we use hyper-spectral imaging for the segmentation of three types of plastic flakes and their possible overlapping combinations. We propose an intuitive and simple multi-label encoding approach, bitfield encoding, to account for the overlapping regions. With our experiments, we show that the bitfield encoding improves over the baseline single-label approach and we further demonstrate its potential in predicting multiple labels for overlapping classes even when the model is only trained with non-overlapping classes.
On the Effect of Pre-Processing and Model Complexity for Plastic Analysis Using Short-Wave-Infrared Hyper-Spectral Imaging
Mar 21, 2022

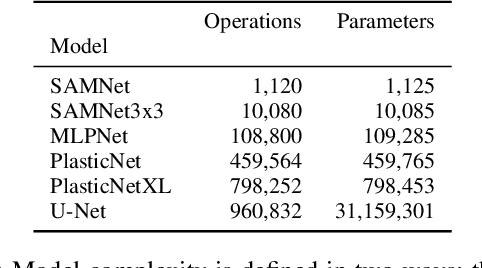
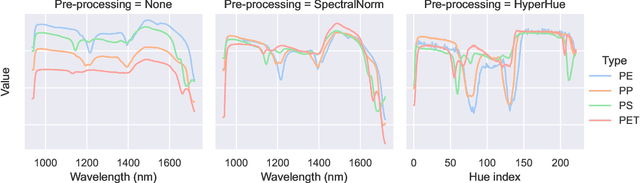
The importance of plastic waste recycling is undeniable. In this respect, computer vision and deep learning enable solutions through the automated analysis of short-wave-infrared hyper-spectral images of plastics. In this paper, we offer an exhaustive empirical study to show the importance of efficient model selection for resolving the task of hyper-spectral image segmentation of various plastic flakes using deep learning. We assess the complexity level of generic and specialized models and infer their performance capacity: generic models are often unnecessarily complex. We introduce two variants of a specialized hyper-spectral architecture, PlasticNet, that outperforms several well-known segmentation architectures in both performance as well as computational complexity. In addition, we shed lights on the significance of signal pre-processing within the realm of hyper-spectral imaging. To complete our contribution, we introduce the largest, most versatile hyper-spectral dataset of plastic flakes of four primary polymer types.