 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Contextual Deep Network Based Multimodal Pedestrian Detection For Autonomous Driving
May 26, 2021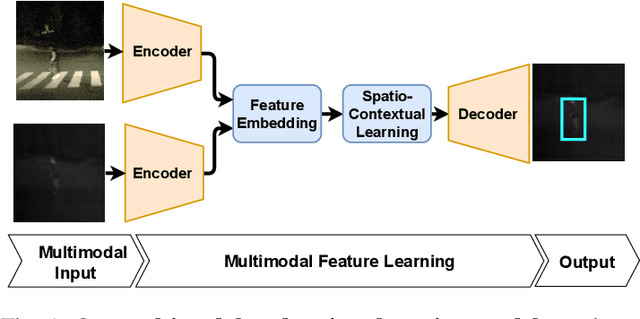
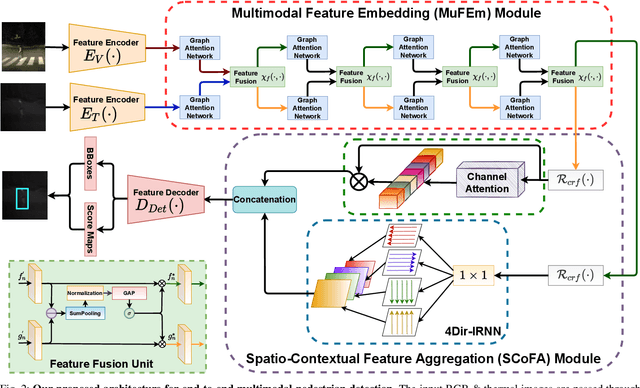


Pedestrian Detection is the most critical module of an Autonomous Driving system. Although a camera is commonly used for this purpose, its quality degrades severely in low-light night time driving scenarios. On the other hand, the quality of a thermal camera image remains unaffected in similar conditions. This paper proposes an end-to-end multimodal fusion model for pedestrian detection using RGB and thermal images. Its novel spatio-contextual deep network architecture is capable of exploiting the multimodal input efficiently. It consists of two distinct deformable ResNeXt-50 encoders for feature extraction from the two modalities. Fusion of these two encoded features takes place inside a multimodal feature embedding module (MuFEm) consisting of several groups of a pair of Graph Attention Network and a feature fusion unit. The output of the last feature fusion unit of MuFEm is subsequently passed to two CRFs for their spatial refinement. Further enhancement of the features is achieved by applying channel-wise attention and extraction of contextual information with the help of four RNNs traversing in four different directions. Finally, these feature maps are used by a single-stage decoder to generate the bounding box of each pedestrian and the score map. We have performed extensive experiments of the proposed framework on three publicly available multimodal pedestrian detection benchmark datasets, namely KAIST, CVC-14, and UTokyo. The results on each of them improved the respective state-of-the-art performance. A short video giving an overview of this work along with its qualitative results can be seen at https://youtu.be/FDJdSifuuCs.
Scale-Invariant Multi-Oriented Text Detection in Wild Scene Images
Feb 15, 2020
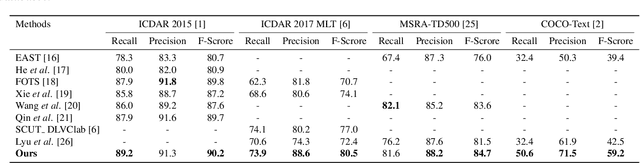


Automatic detection of scene texts in the wild is a challenging problem, particularly due to the difficulties in handling (i) occlusions of varying percentages, (ii) widely different scales and orientations, (iii) severe degradations in the image quality etc. In this article, we propose a fully convolutional neural network architecture consisting of a novel Feature Representation Block (FRB) capable of efficient abstraction of information. The proposed network has been trained using curriculum learning with respect to difficulties in image samples and gradual pixel-wise blurring. It is capable of detecting texts of different scales and orientations suffered by blurring from multiple possible sources, non-uniform illumination as well as partial occlusions of varying percentages. Text detection performance of the proposed framework on various benchmark sample databases including ICDAR 2015, ICDAR 2017 MLT, COCO-Text and MSRA-TD500 improves respective state-of-the-art results significantly. Source code of the proposed architecture will be made available at github.