 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Post Deletion in Sina Weibo: Multi-modal Classification of Hot Topics
Jul 03, 2019
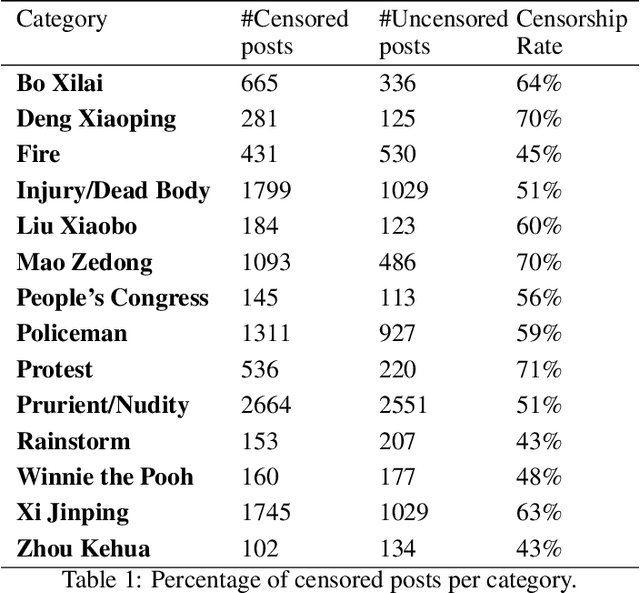
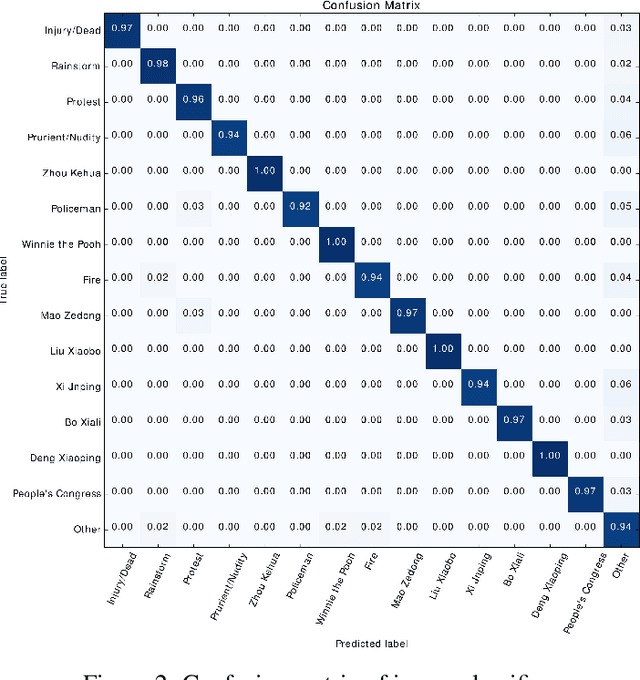
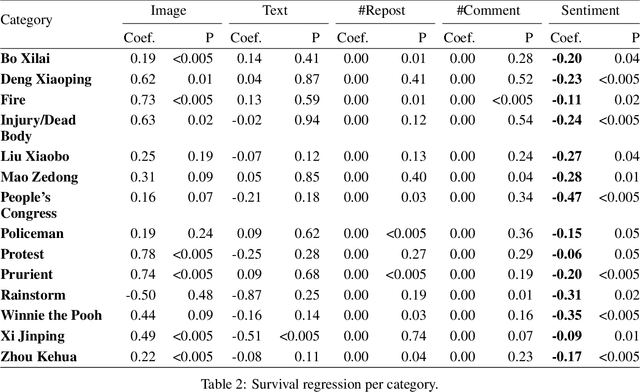
Widespread Chinese social media applications such as Weibo are widely known for monitoring and deleting posts to conform to Chinese government requirements. In this paper, we focus on analyzing a dataset of censored and uncensored posts in Weibo. Despite previous work that only considers text content of posts, we take a multi-modal approach that takes into account both text and image content. We categorize this dataset into 14 categories that have the potential to be censored on Weibo, and seek to quantify censorship by topic. Specifically, we investigate how different factors interact to affect censorship. We also investigate how consistently and how quickly different topics are censored. To this end, we have assembled an image dataset with 18,966 images, as well as a text dataset with 994 posts from 14 categories. We then utilized deep learning, CNN localization, and NLP techniques to analyze the target dataset and extract categories, for further analysis to better understand censorship mechanisms in Weibo. We found that sentiment is the only indicator of censorship that is consistent across the variety of topics we identified. Our finding matches with recently leaked logs from Sina Weibo. We also discovered that most categories like those related to anti-government actions (e.g. protest) or categories related to politicians (e.g. Xi Jinping) are often censored, whereas some categories such as crisis-related categories (e.g. rainstorm) are less frequently censored. We also found that censored posts across all categories are deleted in three hours on average.
How much is said in a microblog? A multilingual inquiry based on Weibo and Twitter
Jun 13, 2015
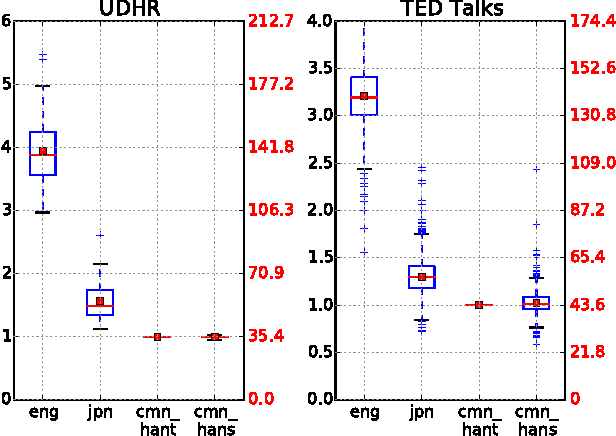

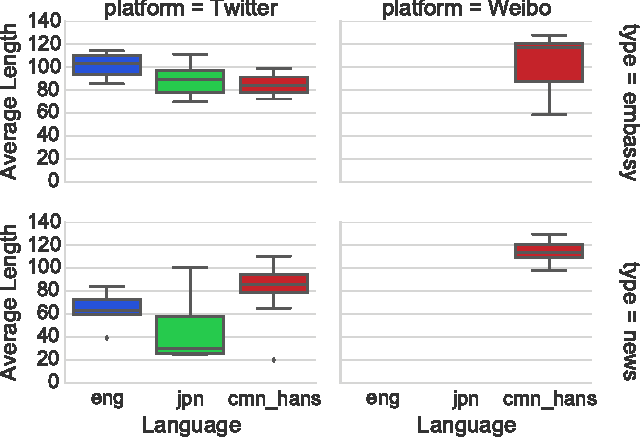
This paper presents a multilingual study on, per single post of microblog text, (a) how much can be said, (b) how much is written in terms of characters and bytes, and (c) how much is said in terms of information content in posts by different organizations in different languages. Focusing on three different languages (English, Chinese, and Japanese), this research analyses Weibo and Twitter accounts of major embassies and news agencies. We first establish our criterion for quantifying "how much can be said" in a digital text based on the openly available Universal Declaration of Human Rights and the translated subtitles from TED talks. These parallel corpora allow us to determine the number of characters and bits needed to represent the same content in different languages and character encodings. We then derive the amount of information that is actually contained in microblog posts authored by selected accounts on Weibo and Twitter. Our results confirm that languages with larger character sets such as Chinese and Japanese contain more information per character than English, but the actual information content contained within a microblog text varies depending on both the type of organization and the language of the post. We conclude with a discussion on the design implications of microblog text limits for different languages.