 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Post Deletion in Sina Weibo: Multi-modal Classification of Hot Topics
Jul 03, 2019
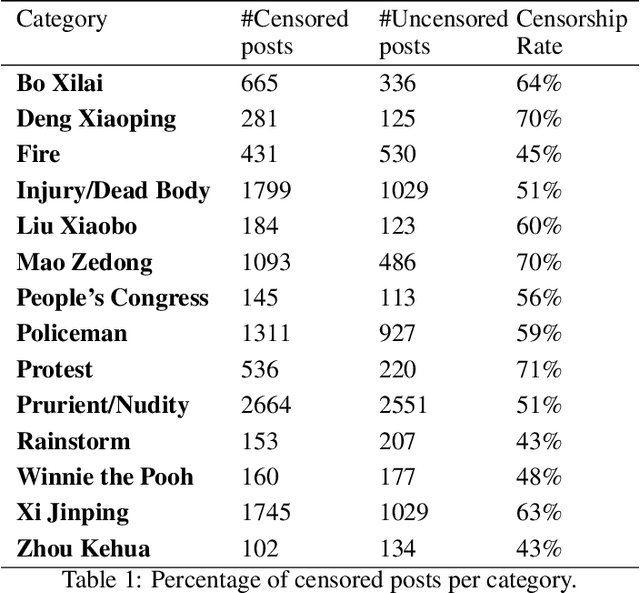
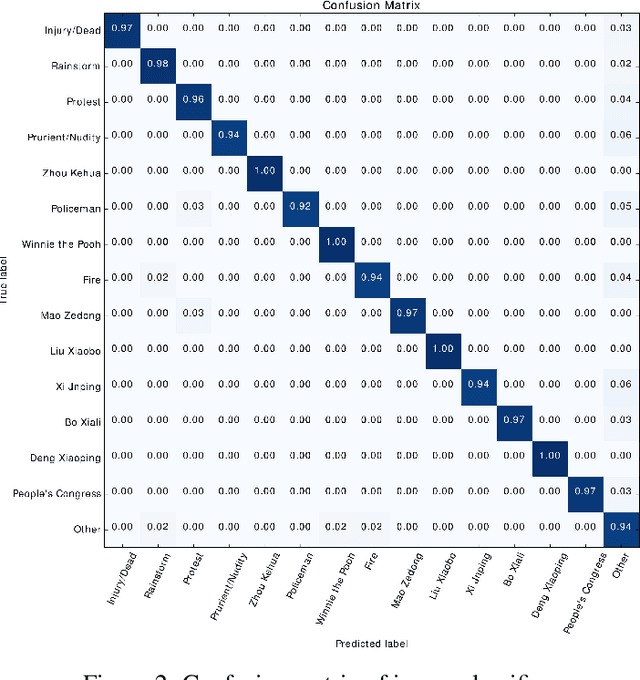
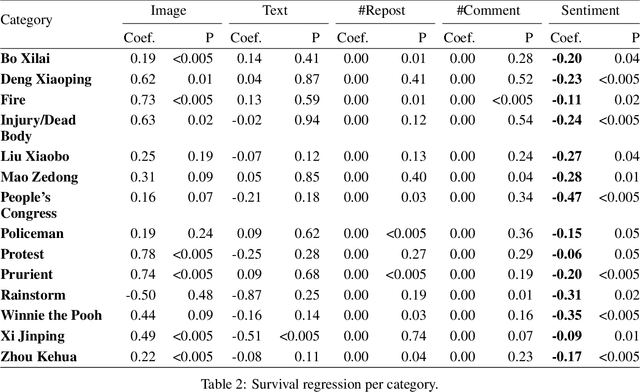
Widespread Chinese social media applications such as Weibo are widely known for monitoring and deleting posts to conform to Chinese government requirements. In this paper, we focus on analyzing a dataset of censored and uncensored posts in Weibo. Despite previous work that only considers text content of posts, we take a multi-modal approach that takes into account both text and image content. We categorize this dataset into 14 categories that have the potential to be censored on Weibo, and seek to quantify censorship by topic. Specifically, we investigate how different factors interact to affect censorship. We also investigate how consistently and how quickly different topics are censored. To this end, we have assembled an image dataset with 18,966 images, as well as a text dataset with 994 posts from 14 categories. We then utilized deep learning, CNN localization, and NLP techniques to analyze the target dataset and extract categories, for further analysis to better understand censorship mechanisms in Weibo. We found that sentiment is the only indicator of censorship that is consistent across the variety of topics we identified. Our finding matches with recently leaked logs from Sina Weibo. We also discovered that most categories like those related to anti-government actions (e.g. protest) or categories related to politicians (e.g. Xi Jinping) are often censored, whereas some categories such as crisis-related categories (e.g. rainstorm) are less frequently censored. We also found that censored posts across all categories are deleted in three hours on average.
A Pointillism Approach for Natural Language Processing of Social Media
Jun 21, 2012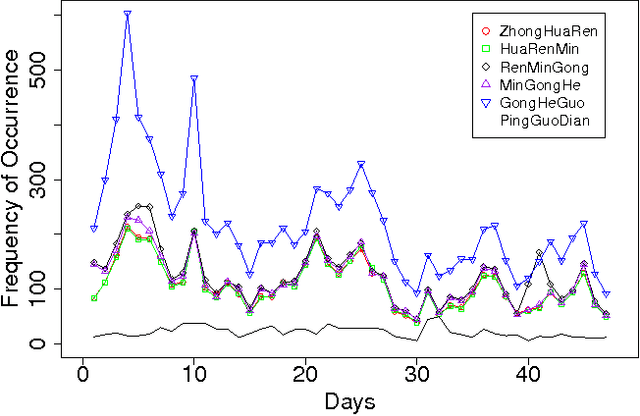
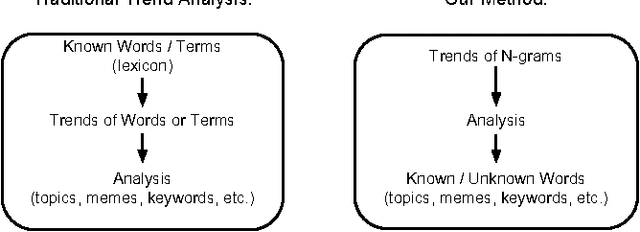
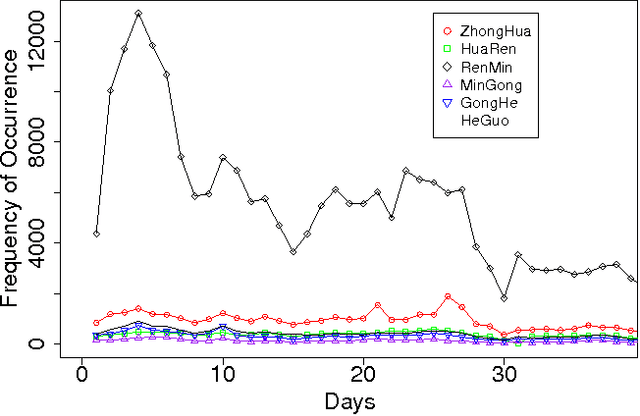
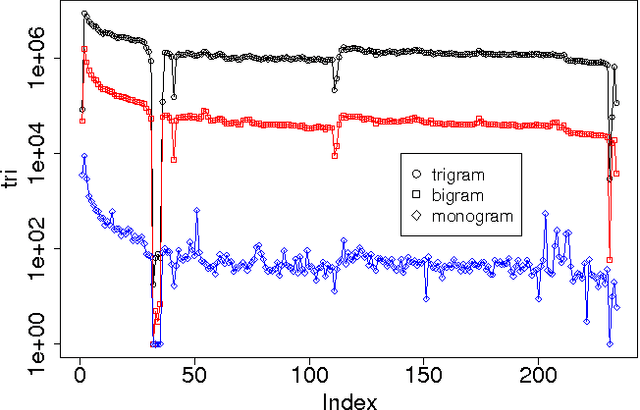
The Chinese language poses challenges for natural language processing based on the unit of a word even for formal uses of the Chinese language, social media only makes word segmentation in Chinese even more difficult. In this document we propose a pointillism approach to natural language processing. Rather than words that have individual meanings, the basic unit of a pointillism approach is trigrams of characters. These grams take on meaning in aggregate when they appear together in a way that is correlated over time. Our results from three kinds of experiments show that when words and topics do have a meme-like trend, they can be reconstructed from only trigrams. For example, for 4-character idioms that appear at least 99 times in one day in our data, the unconstrained precision (that is, precision that allows for deviation from a lexicon when the result is just as correct as the lexicon version of the word or phrase) is 0.93. For longer words and phrases collected from Wiktionary, including neologisms, the unconstrained precision is 0.87. We consider these results to be very promising, because they suggest that it is feasible for a machine to reconstruct complex idioms, phrases, and neologisms with good precision without any notion of words. Thus the colorful and baroque uses of language that typify social media in challenging languages such as Chinese may in fact be accessible to machines.