 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow much is said in a microblog? A multilingual inquiry based on Weibo and Twitter
Jun 13, 2015
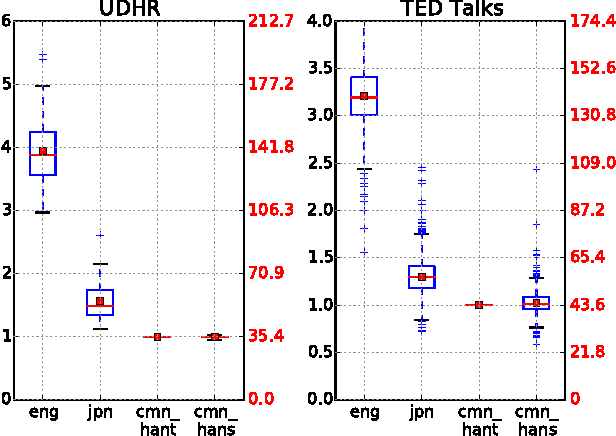

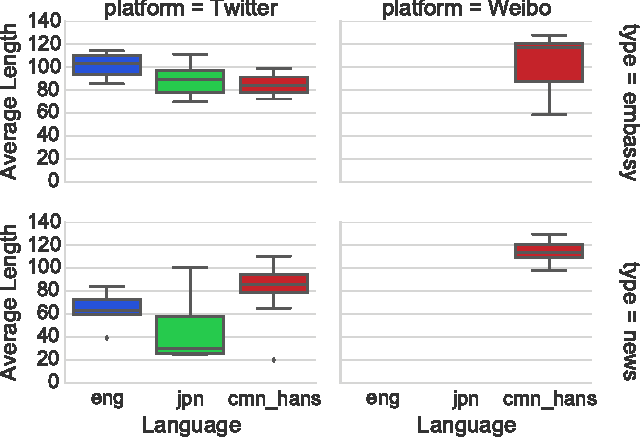
This paper presents a multilingual study on, per single post of microblog text, (a) how much can be said, (b) how much is written in terms of characters and bytes, and (c) how much is said in terms of information content in posts by different organizations in different languages. Focusing on three different languages (English, Chinese, and Japanese), this research analyses Weibo and Twitter accounts of major embassies and news agencies. We first establish our criterion for quantifying "how much can be said" in a digital text based on the openly available Universal Declaration of Human Rights and the translated subtitles from TED talks. These parallel corpora allow us to determine the number of characters and bits needed to represent the same content in different languages and character encodings. We then derive the amount of information that is actually contained in microblog posts authored by selected accounts on Weibo and Twitter. Our results confirm that languages with larger character sets such as Chinese and Japanese contain more information per character than English, but the actual information content contained within a microblog text varies depending on both the type of organization and the language of the post. We conclude with a discussion on the design implications of microblog text limits for different languages.