 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGloss-Free End-to-End Sign Language Translation
May 22, 2023

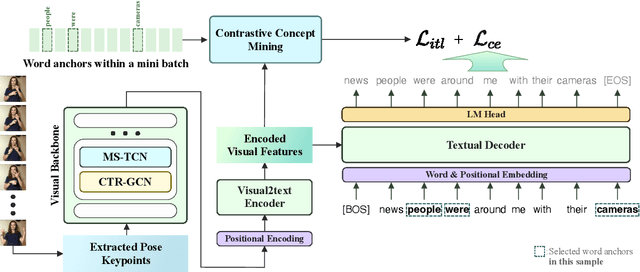

In this paper, we tackle the problem of sign language translation (SLT) without gloss annotations. Although intermediate representation like gloss has been proven effective, gloss annotations are hard to acquire, especially in large quantities. This limits the domain coverage of translation datasets, thus handicapping real-world applications. To mitigate this problem, we design the Gloss-Free End-to-end sign language translation framework (GloFE). Our method improves the performance of SLT in the gloss-free setting by exploiting the shared underlying semantics of signs and the corresponding spoken translation. Common concepts are extracted from the text and used as a weak form of intermediate representation. The global embedding of these concepts is used as a query for cross-attention to find the corresponding information within the learned visual features. In a contrastive manner, we encourage the similarity of query results between samples containing such concepts and decrease those that do not. We obtained state-of-the-art results on large-scale datasets, including OpenASL and How2Sign. The code and model will be available at https://github.com/HenryLittle/GloFE.
Less is More: Sparse Sampling for Dense Reaction Predictions
Jun 03, 2021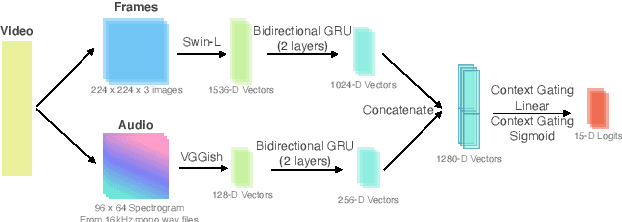



Obtaining viewer responses from videos can be useful for creators and streaming platforms to analyze the video performance and improve the future user experience. In this report, we present our method for 2021 Evoked Expression from Videos Challenge. In particular, our model utilizes both audio and image modalities as inputs to predict emotion changes of viewers. To model long-range emotion changes, we use a GRU-based model to predict one sparse signal with 1Hz. We observe that the emotion changes are smooth. Therefore, the final dense prediction is obtained via linear interpolating the signal, which is robust to the prediction fluctuation. Albeit simple, the proposed method has achieved pearson's correlation score of 0.04430 on the final private test set.