 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attention-Based Model for Predicting Contextual Informativeness and Curriculum Learning Applications
Apr 21, 2022
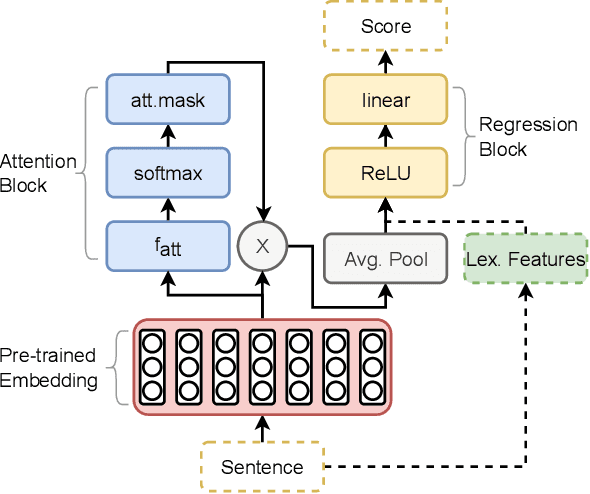


Both humans and machines learn the meaning of unknown words through contextual information in a sentence, but not all contexts are equally helpful for learning. We introduce an effective method for capturing the level of contextual informativeness with respect to a given target word. Our study makes three main contributions. First, we develop models for estimating contextual informativeness, focusing on the instructional aspect of sentences. Our attention-based approach using pre-trained embeddings demonstrates state-of-the-art performance on our single-context dataset and an existing multi-sentence context dataset. Second, we show how our model identifies key contextual elements in a sentence that are likely to contribute most to a reader's understanding of the target word. Third, we examine how our contextual informativeness model, originally developed for vocabulary learning applications for students, can be used for developing better training curricula for word embedding models in batch learning and few-shot machine learning settings. We believe our results open new possibilities for applications that support language learning for both human and machine learners
Human Perception of Surprise: A User Study
Jul 16, 2018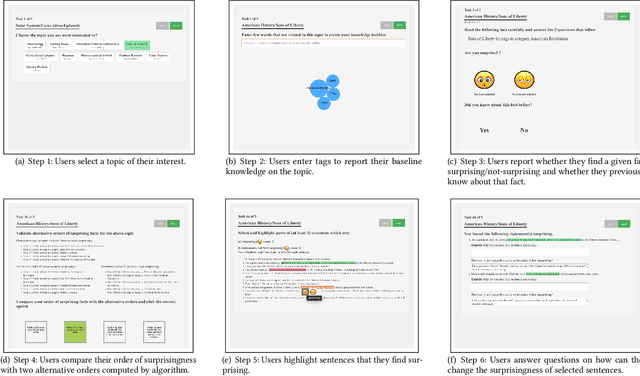
Understanding how to engage users is a critical question in many applications. Previous research has shown that unexpected or astonishing events can attract user attention, leading to positive outcomes such as engagement and learning. In this work, we investigate the similarity and differences in how people and algorithms rank the surprisingness of facts. Our crowdsourcing study, involving 106 participants, shows that computational models of surprise can be used to artificially induce surprise in humans.
Predicting the Relative Difficulty of Single Sentences With and Without Surrounding Context
Oct 25, 2016
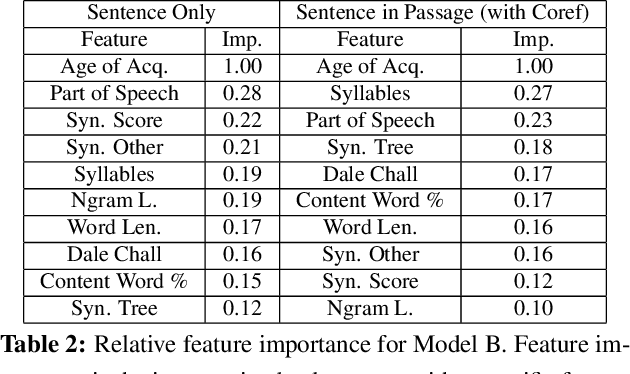
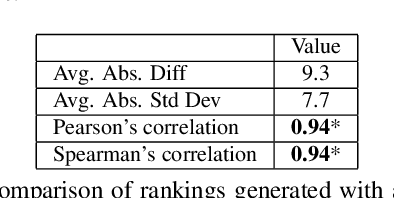
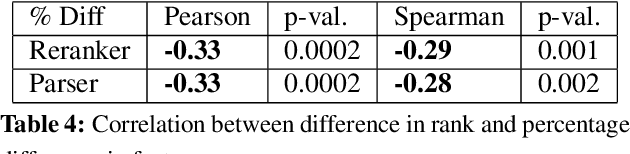
The problem of accurately predicting relative reading difficulty across a set of sentences arises in a number of important natural language applications, such as finding and curating effective usage examples for intelligent language tutoring systems. Yet while significant research has explored document- and passage-level reading difficulty, the special challenges involved in assessing aspects of readability for single sentences have received much less attention, particularly when considering the role of surrounding passages. We introduce and evaluate a novel approach for estimating the relative reading difficulty of a set of sentences, with and without surrounding context. Using different sets of lexical and grammatical features, we explore models for predicting pairwise relative difficulty using logistic regression, and examine rankings generated by aggregating pairwise difficulty labels using a Bayesian rating system to form a final ranking. We also compare rankings derived for sentences assessed with and without context, and find that contextual features can help predict differences in relative difficulty judgments across these two conditions.