 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing 3D finger knuckle recognition via deep feature learning
Jan 07, 2023Contactless 3D finger knuckle patterns have emerged as an effective biometric identifier due to its discriminativeness, visibility from a distance, and convenience. Recent research has developed a deep feature collaboration network which simultaneously incorporates intermediate features from deep neural networks with multiple scales. However, this approach results in a large feature dimension, and the trained classification layer is required for comparing probe samples, which limits the introduction of new classes. This paper advances this approach by investigating the possibility of learning a discriminative feature vector with the least possible dimension for representing 3D finger knuckle images. Experimental results are presented using a publicly available 3D finger knuckle images database with comparisons to popular deep learning architectures and the state-of-the-art 3D finger knuckle recognition methods. The proposed approach offers outperforming results in classification and identification tasks under the more practical feature comparison scenario, i.e., using the extracted deep feature instead of the trained classification layer for comparing probe samples. More importantly, this approach can offer 99% reduction in the size of feature templates, which is highly attractive for deploying biometric systems in the real world. Experiments are also performed using other two public biometric databases with similar patterns to ascertain the effectiveness and generalizability of our proposed approach.
Flexible-Modal Face Anti-Spoofing: A Benchmark
Feb 16, 2022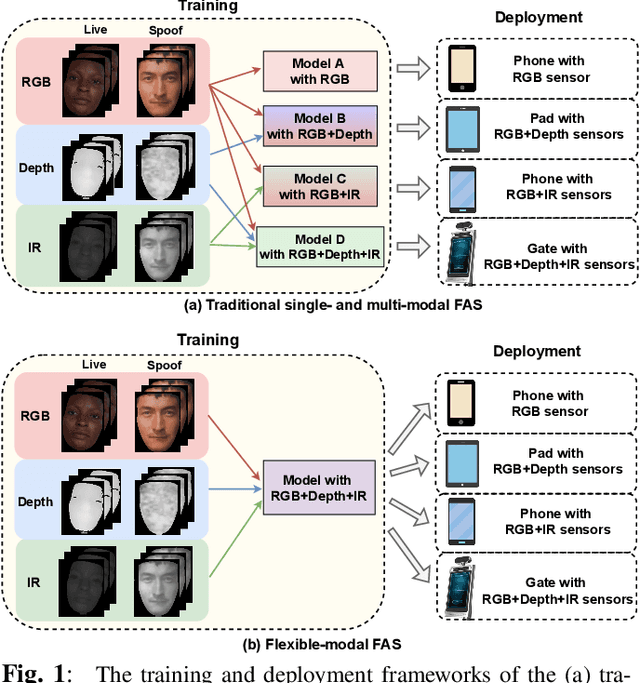


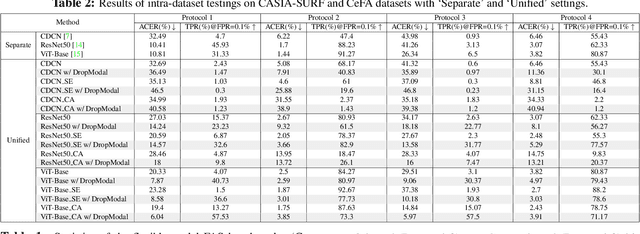
Face anti-spoofing (FAS) plays a vital role in securing face recognition systems from presentation attacks. Benefitted from the maturing camera sensors, single-modal (RGB) and multi-modal (e.g., RGB+Depth) FAS has been applied in various scenarios with different configurations of sensors/modalities. Existing single- and multi-modal FAS methods usually separately train and deploy models for each possible modality scenario, which might be redundant and inefficient. Can we train a unified model, and flexibly deploy it under various modality scenarios? In this paper, we establish the first flexible-modal FAS benchmark with the principle `train one for all'. To be specific, with trained multi-modal (RGB+Depth+IR) FAS models, both intra- and cross-dataset testings are conducted on four flexible-modal sub-protocols (RGB, RGB+Depth, RGB+IR, and RGB+Depth+IR). We also investigate prevalent deep models and feature fusion strategies for flexible-modal FAS. We hope this new benchmark will facilitate the future research of the multi-modal FAS. The protocols and codes are available at https://github.com/ZitongYu/Flex-Modal-FAS.