 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Deep Learning for Variable Type Recovery
Apr 07, 2023Compiled binary executables are often the only available artifact in reverse engineering, malware analysis, and software systems maintenance. Unfortunately, the lack of semantic information like variable types makes comprehending binaries difficult. In efforts to improve the comprehensibility of binaries, researchers have recently used machine learning techniques to predict semantic information contained in the original source code. Chen et al. implemented DIRTY, a Transformer-based Encoder-Decoder architecture capable of augmenting decompiled code with variable names and types by leveraging decompiler output tokens and variable size information. Chen et al. were able to demonstrate a substantial increase in name and type extraction accuracy on Hex-Rays decompiler outputs compared to existing static analysis and AI-based techniques. We extend the original DIRTY results by re-training the DIRTY model on a dataset produced by the open-source Ghidra decompiler. Although Chen et al. concluded that Ghidra was not a suitable decompiler candidate due to its difficulty in parsing and incorporating DWARF symbols during analysis, we demonstrate that straightforward parsing of variable data generated by Ghidra results in similar retyping performance. We hope this work inspires further interest and adoption of the Ghidra decompiler for use in research projects.
COMBO: Pre-Training Representations of Binary Code Using Contrastive Learning
Oct 11, 2022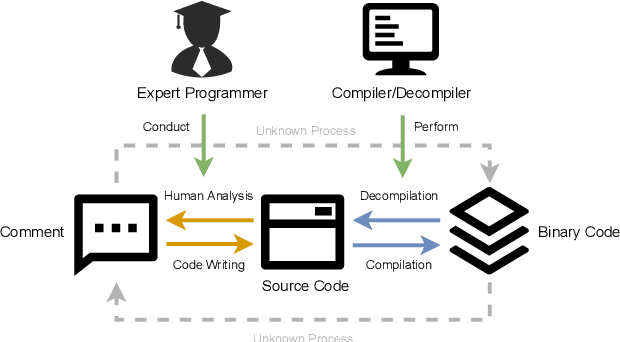
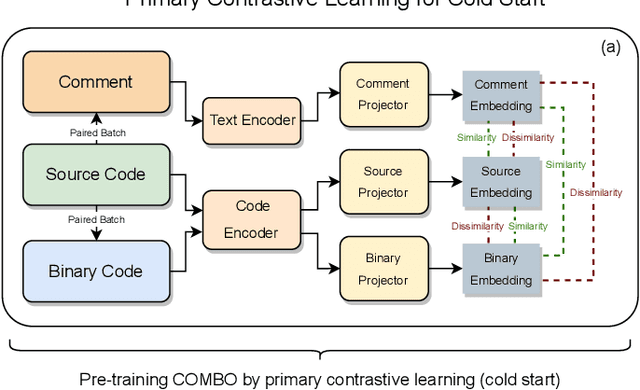
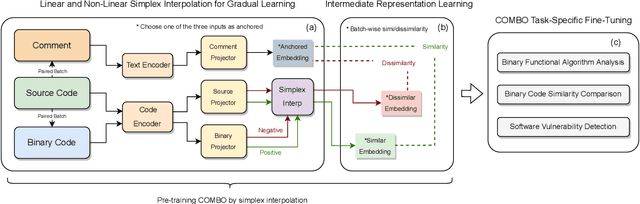
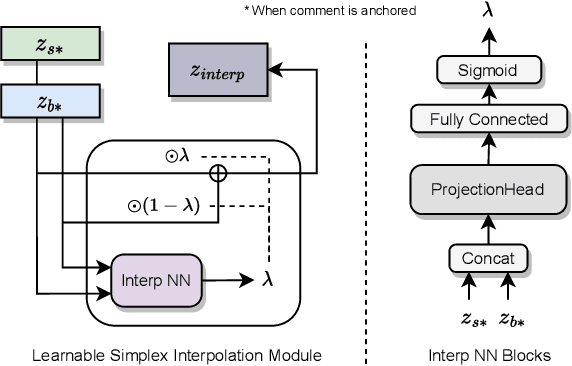
Compiled software is delivered as executable binary code. Developers write source code to express the software semantics, but the compiler converts it to a binary format that the CPU can directly execute. Therefore, binary code analysis is critical to applications in reverse engineering and computer security tasks where source code is not available. However, unlike source code and natural language that contain rich semantic information, binary code is typically difficult for human engineers to understand and analyze. While existing work uses AI models to assist source code analysis, few studies have considered binary code. In this paper, we propose a COntrastive learning Model for Binary cOde Analysis, or COMBO, that incorporates source code and comment information into binary code during representation learning. Specifically, we present three components in COMBO: (1) a primary contrastive learning method for cold-start pre-training, (2) a simplex interpolation method to incorporate source code, comments, and binary code, and (3) an intermediate representation learning algorithm to provide binary code embeddings. Finally, we evaluate the effectiveness of the pre-trained representations produced by COMBO using three indicative downstream tasks relating to binary code: algorithmic functionality classification, binary code similarity, and vulnerability detection. Our experimental results show that COMBO facilitates representation learning of binary code visualized by distribution analysis, and improves the performance on all three downstream tasks by 5.45% on average compared to state-of-the-art large-scale language representation models. To the best of our knowledge, COMBO is the first language representation model that incorporates source code, binary code, and comments into contrastive code representation learning and unifies multiple tasks for binary code analysis.