 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Sparse Attention for Memory-Bound Inference
May 03, 2026Autoregressive decoding becomes bandwidth-limited at long contexts, as generating each token requires reading all $n_k$ key and value vectors from KV cache. We present Stochastic Additive No-mulT Attention (SANTA), a method that sparsifies value-cache access by sampling $S \ll n_k$ indices from the post-softmax distribution and aggregates only those value rows. This yields an unbiased estimator of the post-softmax value aggregation while replacing value-stage multiply-accumulates with gather-and-add. We introduce stratified sampling to design variance-reduced, GPU-friendly variants, demonstrating $1.5\times$ decode-step attention kernel speedup over FlashInfer and FlashDecoding on an NVIDIA RTX 6000 Ada while matching baseline accuracy at 32k-token contexts. Finally, we propose Bernoulli $qK^\mathsf{T}$ sampling as a complementary technique to sparsify the score stage, reducing key-feature access through stochastic ternary queries. Both methods are orthogonal to upstream techniques such as ternary quantization, low-rank projections, and KV-cache compression. Together, they point toward sparse, multiplier-free, and energy-efficient inference. We open-source our kernels at: https://github.com/OPUSLab/SANTA.git
From Independent to Correlated Diffusion: Generalized Generative Modeling with Probabilistic Computers
Mar 30, 2026Diffusion models have emerged as a powerful framework for generative tasks in deep learning. They decompose generative modeling into two computational primitives: deterministic neural-network evaluation and stochastic sampling. Current implementations usually place most computation in the neural network, but diffusion as a framework allows a broader range of choices for the stochastic transition kernel. Here, we generalize the stochastic sampling component by replacing independent noise injection with Markov chain Monte Carlo (MCMC) dynamics that incorporate known interaction structure. Standard independent diffusion is recovered as a special case when couplings are set to zero. By explicitly incorporating Ising couplings into the diffusion dynamics, the noising and denoising processes exploit spatial correlations representative of the target system. The resulting framework maps naturally onto probabilistic computers (p-computers) built from probabilistic bits (p-bits), which provide orders-of-magnitude advantages in sampling throughput and energy efficiency over GPUs. We demonstrate the approach on equilibrium states of the 2D ferromagnetic Ising model and the 3D Edwards-Anderson spin glass, showing that correlated diffusion produces samples in closer agreement with MCMC reference distributions than independent diffusion. More broadly, the framework shows that p-computers can enable new classes of diffusion algorithms that exploit structured probabilistic sampling for generative modeling.
Configurable p-Neurons Using Modular p-Bits
Jan 26, 2026Probabilistic bits (p-bits) have recently been employed in neural networks (NNs) as stochastic neurons with sigmoidal probabilistic activation functions. Nonetheless, there remain a wealth of other probabilistic activation functions that are yet to be explored. Here we re-engineer the p-bit by decoupling its stochastic signal path from its input data path, giving rise to a modular p-bit that enables the realization of probabilistic neurons (p-neurons) with a range of configurable probabilistic activation functions, including a probabilistic version of the widely used Logistic Sigmoid, Tanh and Rectified Linear Unit (ReLU) activation functions. We present spintronic (CMOS + sMTJ) designs that show wide and tunable probabilistic ranges of operation. Finally, we experimentally implement digital-CMOS versions on an FPGA, with stochastic unit sharing, and demonstrate an order of magnitude (10x) saving in required hardware resources compared to conventional digital p-bit implementations.
Probabilistic Computers for Neural Quantum States
Dec 31, 2025Neural quantum states efficiently represent many-body wavefunctions with neural networks, but the cost of Monte Carlo sampling limits their scaling to large system sizes. Here we address this challenge by combining sparse Boltzmann machine architectures with probabilistic computing hardware. We implement a probabilistic computer on field programmable gate arrays (FPGAs) and use it as a fast sampler for energy-based neural quantum states. For the two-dimensional transverse-field Ising model at criticality, we obtain accurate ground-state energies for lattices up to 80 $\times$ 80 (6400 spins) using a custom multi-FPGA cluster. Furthermore, we introduce a dual-sampling algorithm to train deep Boltzmann machines, replacing intractable marginalization with conditional sampling over auxiliary layers. This enables the training of sparse deep models and improves parameter efficiency relative to shallow networks. Using this algorithm, we train deep Boltzmann machines for a system with 35 $\times$ 35 (1225 spins). Together, these results demonstrate that probabilistic hardware can overcome the sampling bottleneck in variational simulation of quantum many-body systems, opening a path to larger system sizes and deeper variational architectures.
Probabilistic Approximate Optimization: A New Variational Monte Carlo Algorithm
Jul 10, 2025We introduce a generalized \textit{Probabilistic Approximate Optimization Algorithm (PAOA)}, a classical variational Monte Carlo framework that extends and formalizes prior work by Weitz \textit{et al.}~\cite{Combes_2023}, enabling parameterized and fast sampling on present-day Ising machines and probabilistic computers. PAOA operates by iteratively modifying the couplings of a network of binary stochastic units, guided by cost evaluations from independent samples. We establish a direct correspondence between derivative-free updates and the gradient of the full $2^N \times 2^N$ Markov flow, showing that PAOA admits a principled variational formulation. Simulated annealing emerges as a limiting case under constrained parameterizations, and we implement this regime on an FPGA-based probabilistic computer with on-chip annealing to solve large 3D spin-glass problems. Benchmarking PAOA against QAOA on the canonical 26-spin Sherrington-Kirkpatrick model with matched parameters reveals superior performance for PAOA. We show that PAOA naturally extends simulated annealing by optimizing multiple temperature profiles, leading to improved performance over SA on heavy-tailed problems such as SK-L\'evy.
Mean-Field Assisted Deep Boltzmann Learning with Probabilistic Computers
Jan 03, 2024Despite their appeal as physics-inspired, energy-based and generative nature, general Boltzmann Machines (BM) are considered intractable to train. This belief led to simplified models of BMs with restricted intralayer connections or layer-by-layer training of deep BMs. Recent developments in domain-specific hardware -- specifically probabilistic computers (p-computer) with probabilistic bits (p-bit) -- may change established wisdom on the tractability of deep BMs. In this paper, we show that deep and unrestricted BMs can be trained using p-computers generating hundreds of billions of Markov Chain Monte Carlo (MCMC) samples per second, on sparse networks developed originally for use in D-Wave's annealers. To maximize the efficiency of learning the p-computer, we introduce two families of Mean-Field Theory assisted learning algorithms, or xMFTs (x = Naive and Hierarchical). The xMFTs are used to estimate the averages and correlations during the positive phase of the contrastive divergence (CD) algorithm and our custom-designed p-computer is used to estimate the averages and correlations in the negative phase. A custom Field-Programmable-Gate Array (FPGA) emulation of the p-computer architecture takes up to 45 billion flips per second, allowing the implementation of CD-$n$ where $n$ can be of the order of millions, unlike RBMs where $n$ is typically 1 or 2. Experiments on the full MNIST dataset with the combined algorithm show that the positive phase can be efficiently computed by xMFTs without much degradation when the negative phase is computed by the p-computer. Our algorithm can be used in other scalable Ising machines and its variants can be used to train BMs, previously thought to be intractable.
Machine Learning Quantum Systems with Magnetic p-bits
Oct 10, 2023The slowing down of Moore's Law has led to a crisis as the computing workloads of Artificial Intelligence (AI) algorithms continue skyrocketing. There is an urgent need for scalable and energy-efficient hardware catering to the unique requirements of AI algorithms and applications. In this environment, probabilistic computing with p-bits emerged as a scalable, domain-specific, and energy-efficient computing paradigm, particularly useful for probabilistic applications and algorithms. In particular, spintronic devices such as stochastic magnetic tunnel junctions (sMTJ) show great promise in designing integrated p-computers. Here, we examine how a scalable probabilistic computer with such magnetic p-bits can be useful for an emerging field combining machine learning and quantum physics.
CMOS + stochastic nanomagnets: heterogeneous computers for probabilistic inference and learning
Apr 18, 2023Extending Moore's law by augmenting complementary-metal-oxide semiconductor (CMOS) transistors with emerging nanotechnologies (X) has become increasingly important. Accelerating Monte Carlo algorithms that rely on random sampling with such CMOS+X technologies could have significant impact on a large number of fields from probabilistic machine learning, optimization to quantum simulation. In this paper, we show the combination of stochastic magnetic tunnel junction (sMTJ)-based probabilistic bits (p-bits) with versatile Field Programmable Gate Arrays (FPGA) to design a CMOS + X (X = sMTJ) prototype. Our approach enables high-quality true randomness that is essential for Monte Carlo based probabilistic sampling and learning. Our heterogeneous computer successfully performs probabilistic inference and asynchronous Boltzmann learning, despite device-to-device variations in sMTJs. A comprehensive comparison using a CMOS predictive process design kit (PDK) reveals that compact sMTJ-based p-bits replace 10,000 transistors while dissipating two orders of magnitude of less energy (2 fJ per random bit), compared to digital CMOS p-bits. Scaled and integrated versions of our CMOS + stochastic nanomagnet approach can significantly advance probabilistic computing and its applications in various domains by providing massively parallel and truly random numbers with extremely high throughput and energy-efficiency.
Training Deep Boltzmann Networks with Sparse Ising Machines
Mar 19, 2023The slowing down of Moore's law has driven the development of unconventional computing paradigms, such as specialized Ising machines tailored to solve combinatorial optimization problems. In this paper, we show a new application domain for probabilistic bit (p-bit) based Ising machines by training deep generative AI models with them. Using sparse, asynchronous, and massively parallel Ising machines we train deep Boltzmann networks in a hybrid probabilistic-classical computing setup. We use the full MNIST dataset without any downsampling or reduction in hardware-aware network topologies implemented in moderately sized Field Programmable Gate Arrays (FPGA). Our machine, which uses only 4,264 nodes (p-bits) and about 30,000 parameters, achieves the same classification accuracy (90%) as an optimized software-based restricted Boltzmann Machine (RBM) with approximately 3.25 million parameters. Additionally, the sparse deep Boltzmann network can generate new handwritten digits, a task the 3.25 million parameter RBM fails at despite achieving the same accuracy. Our hybrid computer takes a measured 50 to 64 billion probabilistic flips per second, which is at least an order of magnitude faster than superficially similar Graphics and Tensor Processing Unit (GPU/TPU) based implementations. The massively parallel architecture can comfortably perform the contrastive divergence algorithm (CD-n) with up to n = 10 million sweeps per update, beyond the capabilities of existing software implementations. These results demonstrate the potential of using Ising machines for traditionally hard-to-train deep generative Boltzmann networks, with further possible improvement in nanodevice-based realizations.
Physics-inspired Ising Computing with Ring Oscillator Activated p-bits
May 15, 2022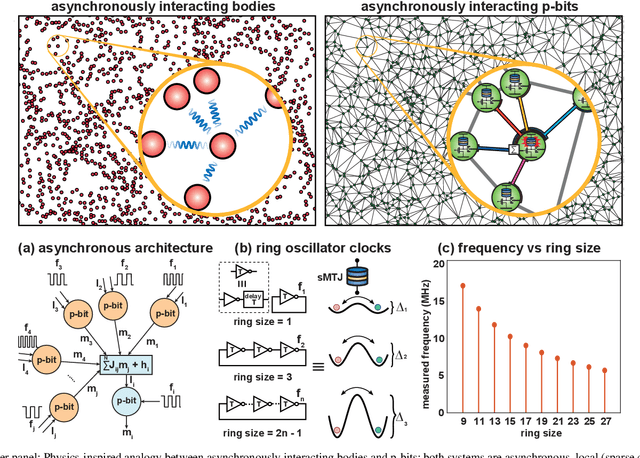
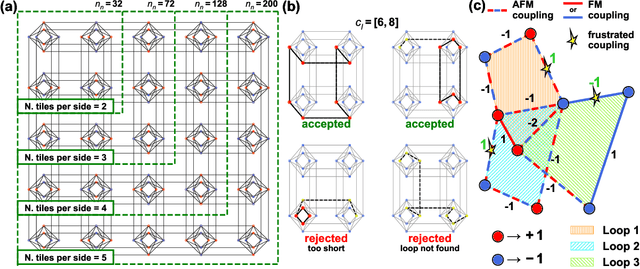
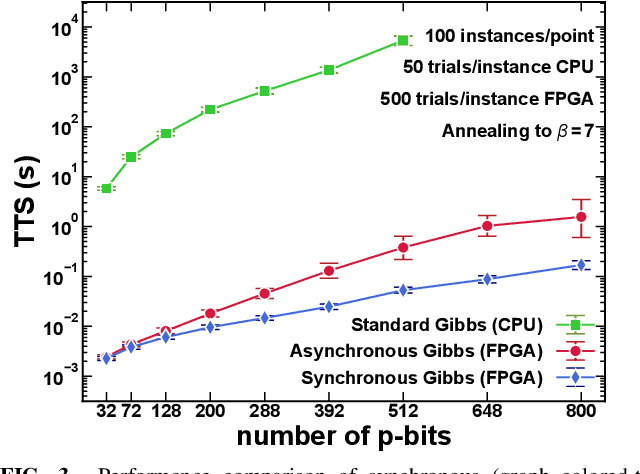
The nearing end of Moore's Law has been driving the development of domain-specific hardware tailored to solve a special set of problems. Along these lines, probabilistic computing with inherently stochastic building blocks (p-bits) have shown significant promise, particularly in the context of hard optimization and statistical sampling problems. p-bits have been proposed and demonstrated in different hardware substrates ranging from small-scale stochastic magnetic tunnel junctions (sMTJs) in asynchronous architectures to large-scale CMOS in synchronous architectures. Here, we design and implement a truly asynchronous and medium-scale p-computer (with $\approx$ 800 p-bits) that closely emulates the asynchronous dynamics of sMTJs in Field Programmable Gate Arrays (FPGAs). Using hard instances of the planted Ising glass problem on the Chimera lattice, we evaluate the performance of the asynchronous architecture against an ideal, synchronous design that performs parallelized (chromatic) exact Gibbs sampling. We find that despite the lack of any careful synchronization, the asynchronous design achieves parallelism with comparable algorithmic scaling in the ideal, carefully tuned and parallelized synchronous design. Our results highlight the promise of massively scaled p-computers with millions of free-running p-bits made out of nanoscale building blocks such as stochastic magnetic tunnel junctions.