 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGReAT: A Graph Regularized Adversarial Training Method
Oct 09, 2023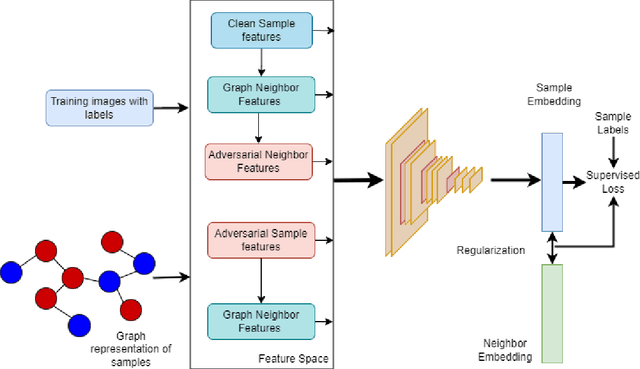
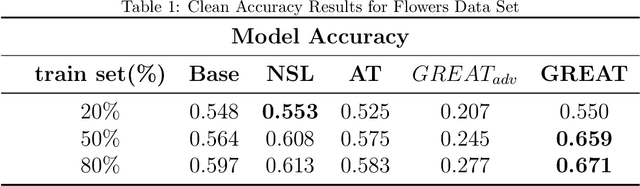

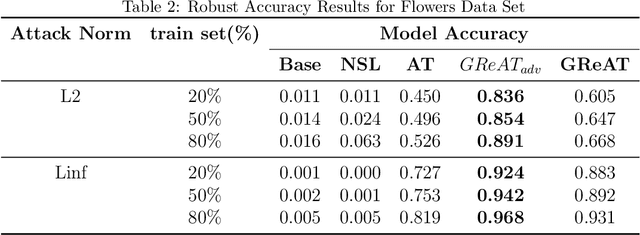
This paper proposes a regularization method called GReAT, Graph Regularized Adversarial Training, to improve deep learning models' classification performance. Adversarial examples are a well-known challenge in machine learning, where small, purposeful perturbations to input data can mislead models. Adversarial training, a powerful and one of the most effective defense strategies, involves training models with both regular and adversarial examples. However, it often neglects the underlying structure of the data. In response, we propose GReAT, a method that leverages data graph structure to enhance model robustness. GReAT deploys the graph structure of the data into the adversarial training process, resulting in more robust models that better generalize its testing performance and defend against adversarial attacks. Through extensive evaluation on benchmark datasets, we demonstrate GReAT's effectiveness compared to state-of-the-art classification methods, highlighting its potential in improving deep learning models' classification performance.
A Black-Box Attack on Optical Character Recognition Systems
Aug 30, 2022
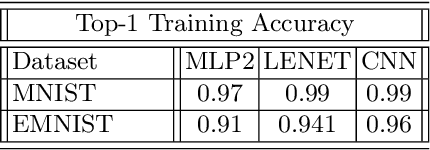


Adversarial machine learning is an emerging area showing the vulnerability of deep learning models. Exploring attack methods to challenge state of the art artificial intelligence (A.I.) models is an area of critical concern. The reliability and robustness of such A.I. models are one of the major concerns with an increasing number of effective adversarial attack methods. Classification tasks are a major vulnerable area for adversarial attacks. The majority of attack strategies are developed for colored or gray-scaled images. Consequently, adversarial attacks on binary image recognition systems have not been sufficiently studied. Binary images are simple two possible pixel-valued signals with a single channel. The simplicity of binary images has a significant advantage compared to colored and gray scaled images, namely computation efficiency. Moreover, most optical character recognition systems (O.C.R.s), such as handwritten character recognition, plate number identification, and bank check recognition systems, use binary images or binarization in their processing steps. In this paper, we propose a simple yet efficient attack method, Efficient Combinatorial Black-box Adversarial Attack, on binary image classifiers. We validate the efficiency of the attack technique on two different data sets and three classification networks, demonstrating its performance. Furthermore, we compare our proposed method with state-of-the-art methods regarding advantages and disadvantages as well as applicability.
A Probabilistic Representation of DNNs: Bridging Mutual Information and Generalization
Jun 18, 2021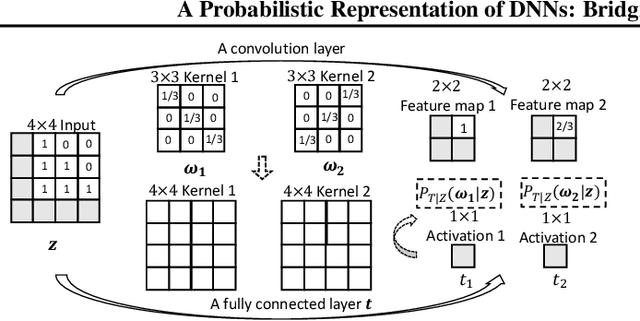

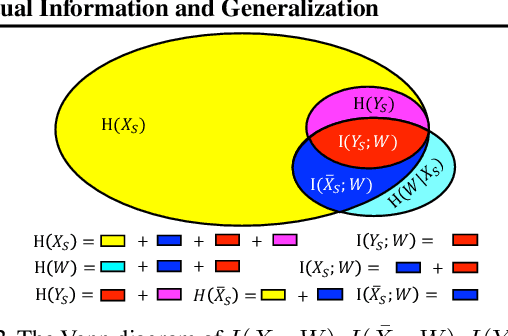

Recently, Mutual Information (MI) has attracted attention in bounding the generalization error of Deep Neural Networks (DNNs). However, it is intractable to accurately estimate the MI in DNNs, thus most previous works have to relax the MI bound, which in turn weakens the information theoretic explanation for generalization. To address the limitation, this paper introduces a probabilistic representation of DNNs for accurately estimating the MI. Leveraging the proposed MI estimator, we validate the information theoretic explanation for generalization, and derive a tighter generalization bound than the state-of-the-art relaxations.
Automatic Group Cohesiveness Detection With Multi-modal Features
Oct 02, 2019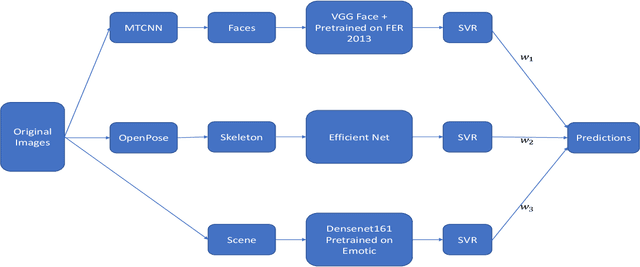
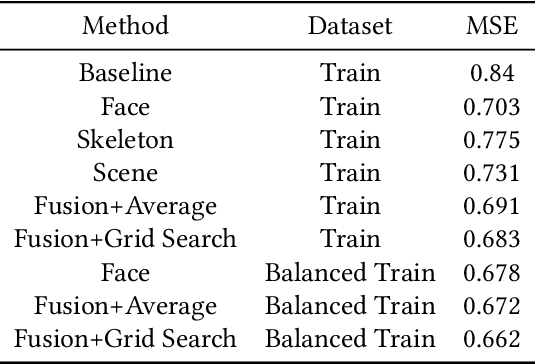

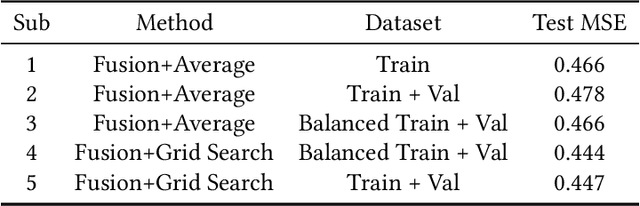
Group cohesiveness is a compelling and often studied composition in group dynamics and group performance. The enormous number of web images of groups of people can be used to develop an effective method to detect group cohesiveness. This paper introduces an automatic group cohesiveness prediction method for the 7th Emotion Recognition in the Wild (EmotiW 2019) Grand Challenge in the category of Group-based Cohesion Prediction. The task is to predict the cohesive level for a group of people in images. To tackle this problem, a hybrid network including regression models which are separately trained on face features, skeleton features, and scene features is proposed. Predicted regression values, corresponding to each feature, are fused for the final cohesive intensity. Experimental results demonstrate that the proposed hybrid network is effective and makes promising improvements. A mean squared error (MSE) of 0.444 is achieved on the testing sets which outperforms the baseline MSE of 0.5.