 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGReAT: A Graph Regularized Adversarial Training Method
Paper and Code
Oct 09, 2023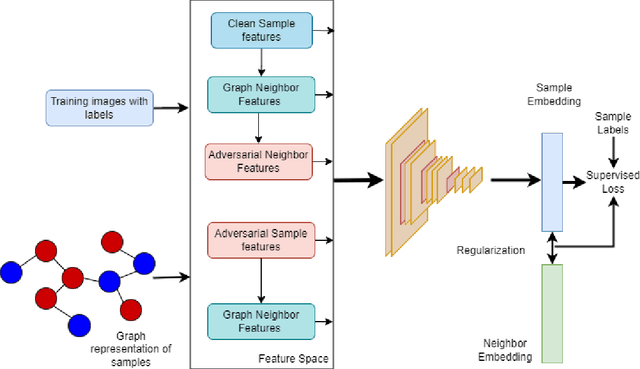
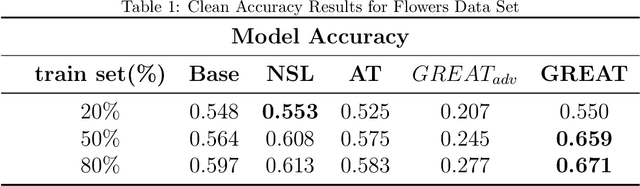

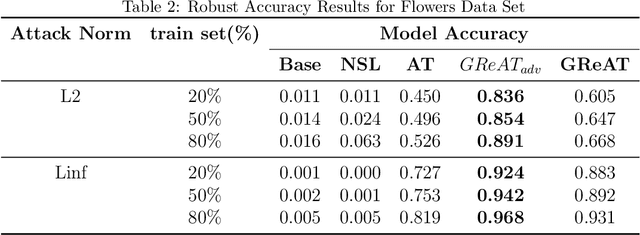
This paper proposes a regularization method called GReAT, Graph Regularized Adversarial Training, to improve deep learning models' classification performance. Adversarial examples are a well-known challenge in machine learning, where small, purposeful perturbations to input data can mislead models. Adversarial training, a powerful and one of the most effective defense strategies, involves training models with both regular and adversarial examples. However, it often neglects the underlying structure of the data. In response, we propose GReAT, a method that leverages data graph structure to enhance model robustness. GReAT deploys the graph structure of the data into the adversarial training process, resulting in more robust models that better generalize its testing performance and defend against adversarial attacks. Through extensive evaluation on benchmark datasets, we demonstrate GReAT's effectiveness compared to state-of-the-art classification methods, highlighting its potential in improving deep learning models' classification performance.