 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegotiated Representations for Machine Mearning Application
Nov 19, 2023Overfitting is a phenomenon that occurs when a machine learning model is trained for too long and focused too much on the exact fitness of the training samples to the provided training labels and cannot keep track of the predictive rules that would be useful on the test data. This phenomenon is commonly attributed to memorization of particular samples, memorization of the noise, and forced fitness into a data set of limited samples by using a high number of neurons. While it is true that the model encodes various peculiarities as the training process continues, we argue that most of the overfitting occurs in the process of reconciling sharply defined membership ratios. In this study, we present an approach that increases the classification accuracy of machine learning models by allowing the model to negotiate output representations of the samples with previously determined class labels. By setting up a negotiation between the models interpretation of the inputs and the provided labels, we not only increased average classification accuracy but also decreased the rate of overfitting without applying any other regularization tricks. By implementing our negotiation paradigm approach to several low regime machine learning problems by generating overfitting scenarios from publicly available data sets such as CIFAR 10, CIFAR 100, and MNIST we have demonstrated that the proposed paradigm has more capacity than its intended purpose. We are sharing the experimental results and inviting the machine learning community to explore the limits of the proposed paradigm. We also aim to incentive the community to exploit the negotiation paradigm to overcome the learning related challenges in other research fields such as continual learning. The Python code of the experimental setup is uploaded to GitHub.
GReAT: A Graph Regularized Adversarial Training Method
Oct 09, 2023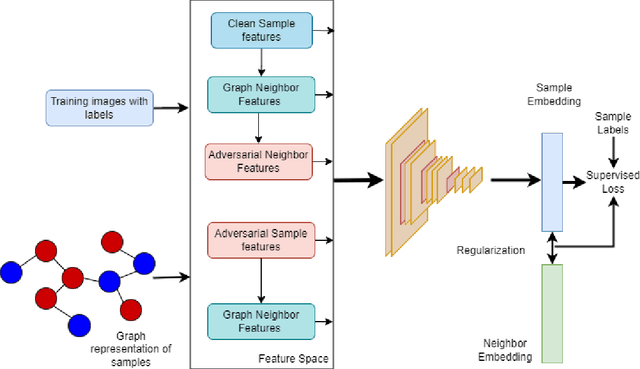
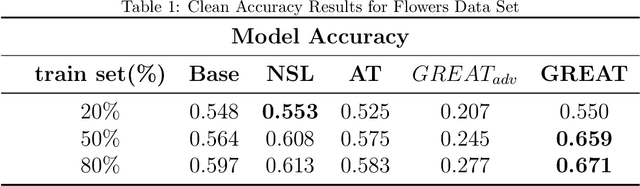

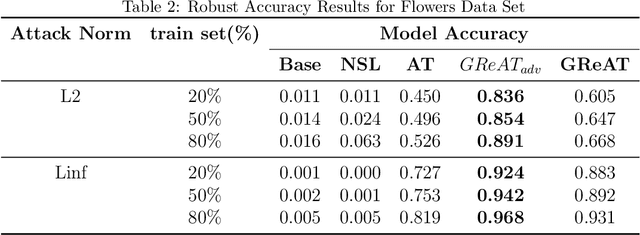
This paper proposes a regularization method called GReAT, Graph Regularized Adversarial Training, to improve deep learning models' classification performance. Adversarial examples are a well-known challenge in machine learning, where small, purposeful perturbations to input data can mislead models. Adversarial training, a powerful and one of the most effective defense strategies, involves training models with both regular and adversarial examples. However, it often neglects the underlying structure of the data. In response, we propose GReAT, a method that leverages data graph structure to enhance model robustness. GReAT deploys the graph structure of the data into the adversarial training process, resulting in more robust models that better generalize its testing performance and defend against adversarial attacks. Through extensive evaluation on benchmark datasets, we demonstrate GReAT's effectiveness compared to state-of-the-art classification methods, highlighting its potential in improving deep learning models' classification performance.
A Black-Box Attack on Optical Character Recognition Systems
Aug 30, 2022
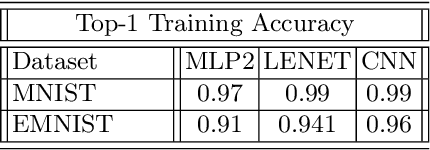


Adversarial machine learning is an emerging area showing the vulnerability of deep learning models. Exploring attack methods to challenge state of the art artificial intelligence (A.I.) models is an area of critical concern. The reliability and robustness of such A.I. models are one of the major concerns with an increasing number of effective adversarial attack methods. Classification tasks are a major vulnerable area for adversarial attacks. The majority of attack strategies are developed for colored or gray-scaled images. Consequently, adversarial attacks on binary image recognition systems have not been sufficiently studied. Binary images are simple two possible pixel-valued signals with a single channel. The simplicity of binary images has a significant advantage compared to colored and gray scaled images, namely computation efficiency. Moreover, most optical character recognition systems (O.C.R.s), such as handwritten character recognition, plate number identification, and bank check recognition systems, use binary images or binarization in their processing steps. In this paper, we propose a simple yet efficient attack method, Efficient Combinatorial Black-box Adversarial Attack, on binary image classifiers. We validate the efficiency of the attack technique on two different data sets and three classification networks, demonstrating its performance. Furthermore, we compare our proposed method with state-of-the-art methods regarding advantages and disadvantages as well as applicability.