 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual and Continuous Backchannel Prediction: A Cross-lingual Study
Dec 16, 2025
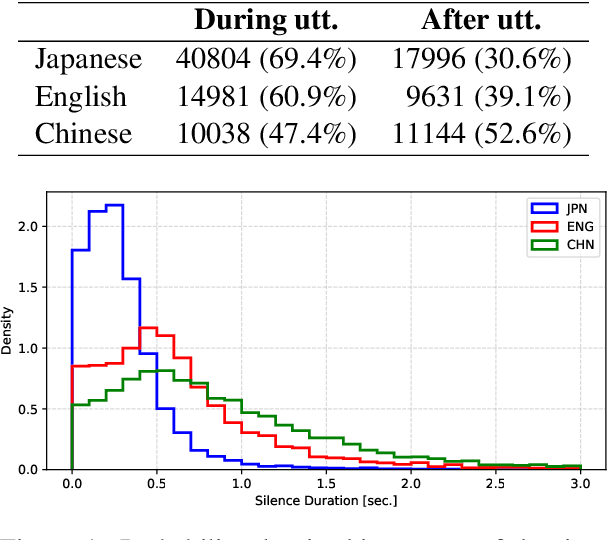
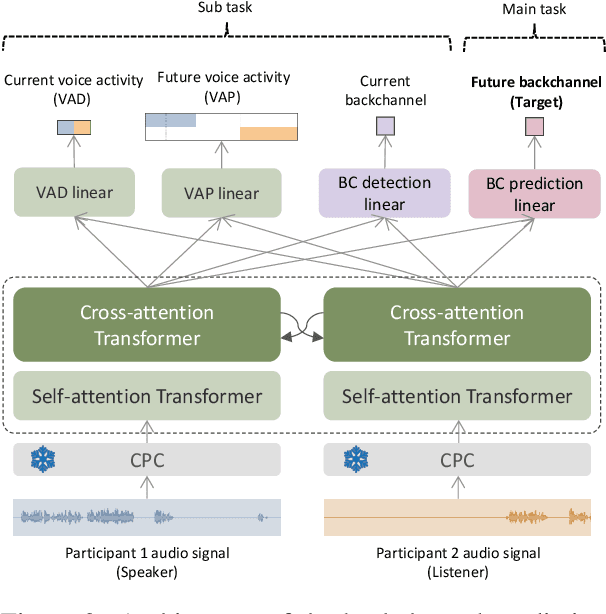
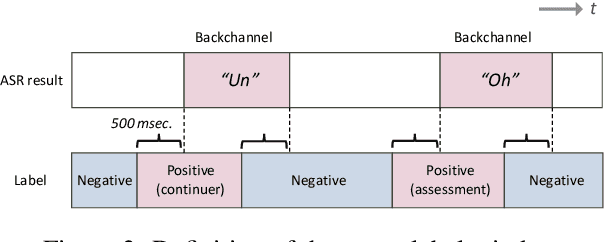
We present a multilingual, continuous backchannel prediction model for Japanese, English, and Chinese, and use it to investigate cross-linguistic timing behavior. The model is Transformer-based and operates at the frame level, jointly trained with auxiliary tasks on approximately 300 hours of dyadic conversations. Across all three languages, the multilingual model matches or surpasses monolingual baselines, indicating that it learns both language-universal cues and language-specific timing patterns. Zero-shot transfer with two-language training remains limited, underscoring substantive cross-lingual differences. Perturbation analyses reveal distinct cue usage: Japanese relies more on short-term linguistic information, whereas English and Chinese are more sensitive to silence duration and prosodic variation; multilingual training encourages shared yet adaptable representations and reduces overreliance on pitch in Chinese. A context-length study further shows that Japanese is relatively robust to shorter contexts, while Chinese benefits markedly from longer contexts. Finally, we integrate the trained model into a real-time processing software, demonstrating CPU-only inference. Together, these findings provide a unified model and empirical evidence for how backchannel timing differs across languages, informing the design of more natural, culturally-aware spoken dialogue systems.
An LLM Benchmark for Addressee Recognition in Multi-modal Multi-party Dialogue
Jan 28, 2025



Handling multi-party dialogues represents a significant step for advancing spoken dialogue systems, necessitating the development of tasks specific to multi-party interactions. To address this challenge, we are constructing a multi-modal multi-party dialogue corpus of triadic (three-participant) discussions. This paper focuses on the task of addressee recognition, identifying who is being addressed to take the next turn, a critical component unique to multi-party dialogue systems. A subset of the corpus was annotated with addressee information, revealing that explicit addressees are indicated in approximately 20% of conversational turns. To evaluate the task's complexity, we benchmarked the performance of a large language model (GPT-4o) on addressee recognition. The results showed that GPT-4o achieved an accuracy only marginally above chance, underscoring the challenges of addressee recognition in multi-party dialogue. These findings highlight the need for further research to enhance the capabilities of large language models in understanding and navigating the intricacies of multi-party conversational dynamics.
Analysis and Detection of Differences in Spoken User Behaviors between Autonomous and Wizard-of-Oz Systems
Oct 04, 2024
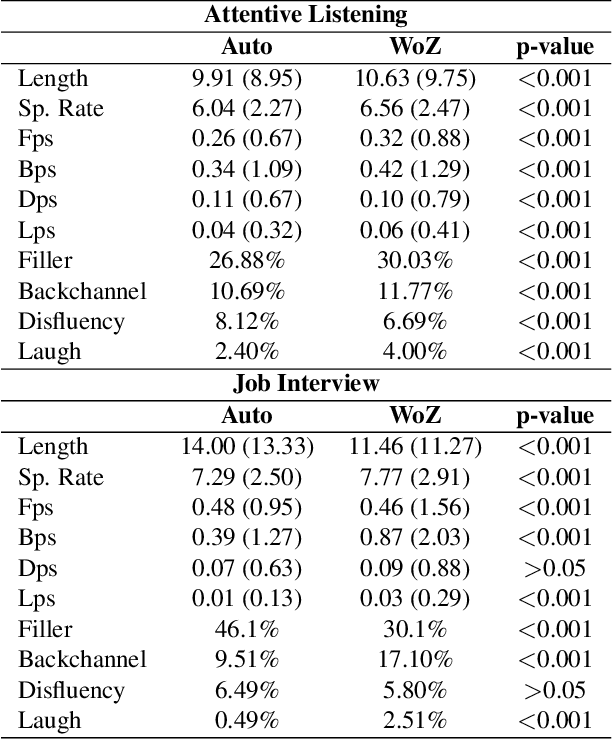
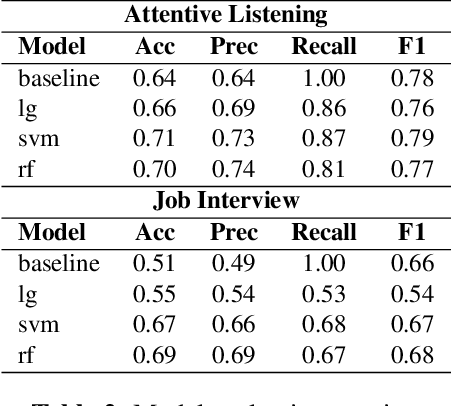
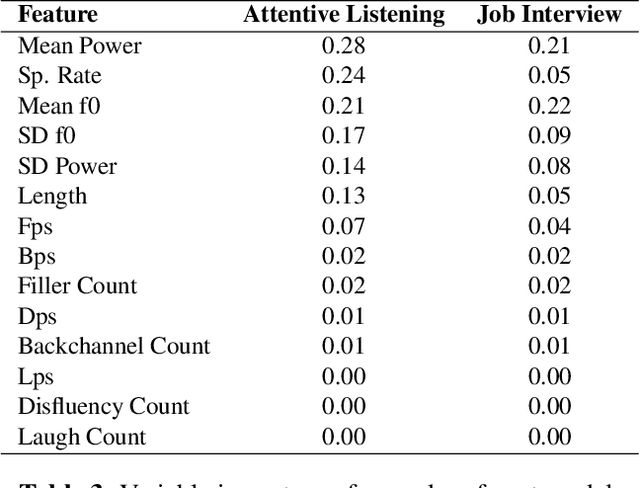
This study examined users' behavioral differences in a large corpus of Japanese human-robot interactions, comparing interactions between a tele-operated robot and an autonomous dialogue system. We analyzed user spoken behaviors in both attentive listening and job interview dialogue scenarios. Results revealed significant differences in metrics such as speech length, speaking rate, fillers, backchannels, disfluencies, and laughter between operator-controlled and autonomous conditions. Furthermore, we developed predictive models to distinguish between operator and autonomous system conditions. Our models demonstrated higher accuracy and precision compared to the baseline model, with several models also achieving a higher F1 score than the baseline.
Evaluation of a semi-autonomous attentive listening system with takeover prompting
Feb 21, 2024



The handling of communication breakdowns and loss of engagement is an important aspect of spoken dialogue systems, particularly for chatting systems such as attentive listening, where the user is mostly speaking. We presume that a human is best equipped to handle this task and rescue the flow of conversation. To this end, we propose a semi-autonomous system, where a remote operator can take control of an autonomous attentive listening system in real-time. In order to make human intervention easy and consistent, we introduce automatic detection of low interest and engagement to provide explicit takeover prompts to the remote operator. We implement this semi-autonomous system which detects takeover points for the operator and compare it to fully tele-operated and fully autonomous attentive listening systems. We find that the semi-autonomous system is generally perceived more positively than the autonomous system. The results suggest that identifying points of conversation when the user starts to lose interest may help us improve a fully autonomous dialogue system.
Acknowledgment of Emotional States: Generating Validating Responses for Empathetic Dialogue
Feb 20, 2024



In the realm of human-AI dialogue, the facilitation of empathetic responses is important. Validation is one of the key communication techniques in psychology, which entails recognizing, understanding, and acknowledging others' emotional states, thoughts, and actions. This study introduces the first framework designed to engender empathetic dialogue with validating responses. Our approach incorporates a tripartite module system: 1) validation timing detection, 2) users' emotional state identification, and 3) validating response generation. Utilizing Japanese EmpatheticDialogues dataset - a textual-based dialogue dataset consisting of 8 emotional categories from Plutchik's wheel of emotions - the Task Adaptive Pre-Training (TAPT) BERT-based model outperforms both random baseline and the ChatGPT performance, in term of F1-score, in all modules. Further validation of our model's efficacy is confirmed in its application to the TUT Emotional Storytelling Corpus (TESC), a speech-based dialogue dataset, by surpassing both random baseline and the ChatGPT. This consistent performance across both textual and speech-based dialogues underscores the effectiveness of our framework in fostering empathetic human-AI communication.
An Analysis of User Behaviors for Objectively Evaluating Spoken Dialogue Systems
Jan 23, 2024Establishing evaluation schemes for spoken dialogue systems is important, but it can also be challenging. While subjective evaluations are commonly used in user experiments, objective evaluations are necessary for research comparison and reproducibility. To address this issue, we propose a framework for indirectly but objectively evaluating systems based on users' behaviors. In this paper, to this end, we investigate the relationship between user behaviors and subjective evaluation scores in social dialogue tasks: attentive listening, job interview, and first-meeting conversation. The results reveal that in dialogue tasks where user utterances are primary, such as attentive listening and job interview, indicators like the number of utterances and words play a significant role in evaluation. Observing disfluency also can indicate the effectiveness of formal tasks, such as job interview. On the other hand, in dialogue tasks with high interactivity, such as first-meeting conversation, behaviors related to turn-taking, like average switch pause length, become more important. These findings suggest that selecting appropriate user behaviors can provide valuable insights for objective evaluation in each social dialogue task.
Towards Objective Evaluation of Socially-Situated Conversational Robots: Assessing Human-Likeness through Multimodal User Behaviors
Aug 21, 2023



This paper tackles the challenging task of evaluating socially situated conversational robots and presents a novel objective evaluation approach that relies on multimodal user behaviors. In this study, our main focus is on assessing the human-likeness of the robot as the primary evaluation metric. While previous research often relied on subjective evaluations from users, our approach aims to evaluate the robot's human-likeness based on observable user behaviors indirectly, thus enhancing objectivity and reproducibility. To begin, we created an annotated dataset of human-likeness scores, utilizing user behaviors found in an attentive listening dialogue corpus. We then conducted an analysis to determine the correlation between multimodal user behaviors and human-likeness scores, demonstrating the feasibility of our proposed behavior-based evaluation method.