 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual and Continuous Backchannel Prediction: A Cross-lingual Study
Dec 16, 2025
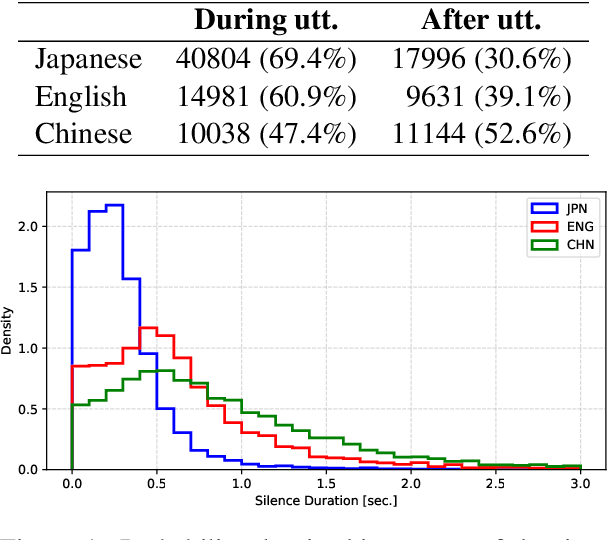
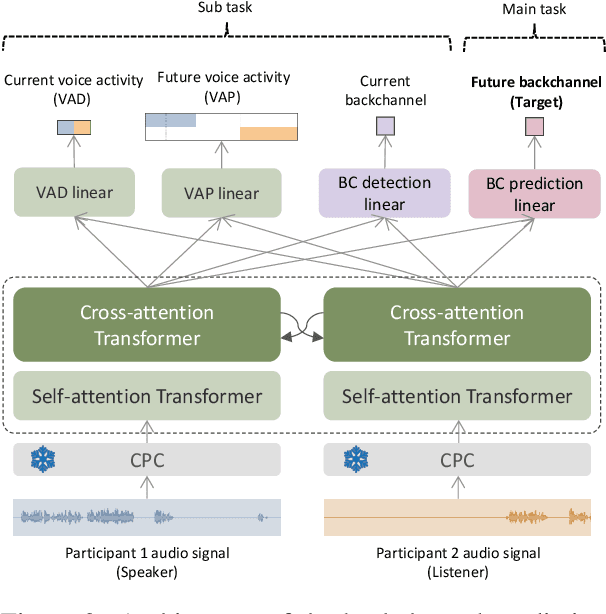
We present a multilingual, continuous backchannel prediction model for Japanese, English, and Chinese, and use it to investigate cross-linguistic timing behavior. The model is Transformer-based and operates at the frame level, jointly trained with auxiliary tasks on approximately 300 hours of dyadic conversations. Across all three languages, the multilingual model matches or surpasses monolingual baselines, indicating that it learns both language-universal cues and language-specific timing patterns. Zero-shot transfer with two-language training remains limited, underscoring substantive cross-lingual differences. Perturbation analyses reveal distinct cue usage: Japanese relies more on short-term linguistic information, whereas English and Chinese are more sensitive to silence duration and prosodic variation; multilingual training encourages shared yet adaptable representations and reduces overreliance on pitch in Chinese. A context-length study further shows that Japanese is relatively robust to shorter contexts, while Chinese benefits markedly from longer contexts. Finally, we integrate the trained model into a real-time processing software, demonstrating CPU-only inference. Together, these findings provide a unified model and empirical evidence for how backchannel timing differs across languages, informing the design of more natural, culturally-aware spoken dialogue systems.
Triadic Multi-party Voice Activity Projection for Turn-taking in Spoken Dialogue Systems
Jul 10, 2025Turn-taking is a fundamental component of spoken dialogue, however conventional studies mostly involve dyadic settings. This work focuses on applying voice activity projection (VAP) to predict upcoming turn-taking in triadic multi-party scenarios. The goal of VAP models is to predict the future voice activity for each speaker utilizing only acoustic data. This is the first study to extend VAP into triadic conversation. We trained multiple models on a Japanese triadic dataset where participants discussed a variety of topics. We found that the VAP trained on triadic conversation outperformed the baseline for all models but that the type of conversation affected the accuracy. This study establishes that VAP can be used for turn-taking in triadic dialogue scenarios. Future work will incorporate this triadic VAP turn-taking model into spoken dialogue systems.
Does the Appearance of Autonomous Conversational Robots Affect User Spoken Behaviors in Real-World Conference Interactions?
Mar 17, 2025We investigate the impact of robot appearance on users' spoken behavior during real-world interactions by comparing a human-like android, ERICA, with a less anthropomorphic humanoid, TELECO. Analyzing data from 42 participants at SIGDIAL 2024, we extracted linguistic features such as disfluencies and syntactic complexity from conversation transcripts. The results showed moderate effect sizes, suggesting that participants produced fewer disfluencies and employed more complex syntax when interacting with ERICA. Further analysis involving training classification models like Na\"ive Bayes, which achieved an F1-score of 71.60\%, and conducting feature importance analysis, highlighted the significant role of disfluencies and syntactic complexity in interactions with robots of varying human-like appearances. Discussing these findings within the frameworks of cognitive load and Communication Accommodation Theory, we conclude that designing robots to elicit more structured and fluent user speech can enhance their communicative alignment with humans.
An LLM Benchmark for Addressee Recognition in Multi-modal Multi-party Dialogue
Jan 28, 2025



Handling multi-party dialogues represents a significant step for advancing spoken dialogue systems, necessitating the development of tasks specific to multi-party interactions. To address this challenge, we are constructing a multi-modal multi-party dialogue corpus of triadic (three-participant) discussions. This paper focuses on the task of addressee recognition, identifying who is being addressed to take the next turn, a critical component unique to multi-party dialogue systems. A subset of the corpus was annotated with addressee information, revealing that explicit addressees are indicated in approximately 20% of conversational turns. To evaluate the task's complexity, we benchmarked the performance of a large language model (GPT-4o) on addressee recognition. The results showed that GPT-4o achieved an accuracy only marginally above chance, underscoring the challenges of addressee recognition in multi-party dialogue. These findings highlight the need for further research to enhance the capabilities of large language models in understanding and navigating the intricacies of multi-party conversational dynamics.
Why Do We Laugh? Annotation and Taxonomy Generation for Laughable Contexts in Spontaneous Text Conversation
Jan 28, 2025Laughter serves as a multifaceted communicative signal in human interaction, yet its identification within dialogue presents a significant challenge for conversational AI systems. This study addresses this challenge by annotating laughable contexts in Japanese spontaneous text conversation data and developing a taxonomy to classify the underlying reasons for such contexts. Initially, multiple annotators manually labeled laughable contexts using a binary decision (laughable or non-laughable). Subsequently, an LLM was used to generate explanations for the binary annotations of laughable contexts, which were then categorized into a taxonomy comprising ten categories, including "Empathy and Affinity" and "Humor and Surprise," highlighting the diverse range of laughter-inducing scenarios. The study also evaluated GPT-4's performance in recognizing the majority labels of laughable contexts, achieving an F1 score of 43.14%. These findings contribute to the advancement of conversational AI by establishing a foundation for more nuanced recognition and generation of laughter, ultimately fostering more natural and engaging human-AI interactions.
Human-Like Embodied AI Interviewer: Employing Android ERICA in Real International Conference
Dec 13, 2024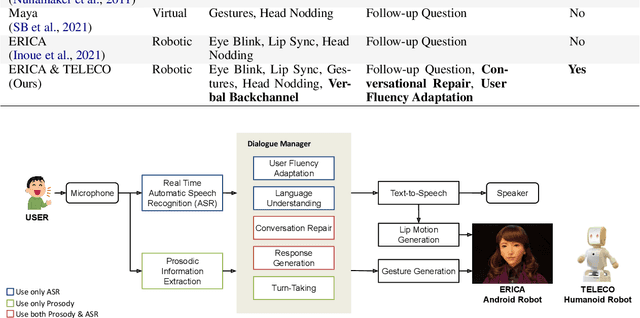
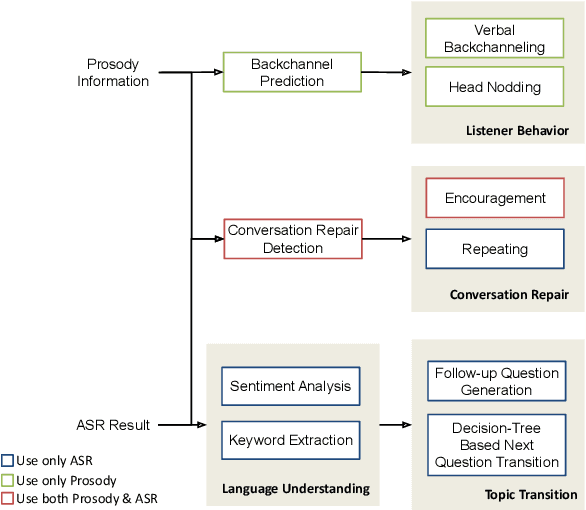

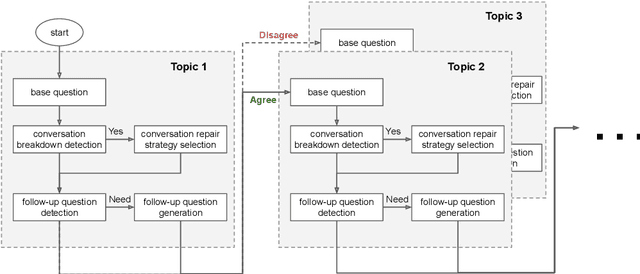
This paper introduces the human-like embodied AI interviewer which integrates android robots equipped with advanced conversational capabilities, including attentive listening, conversational repairs, and user fluency adaptation. Moreover, it can analyze and present results post-interview. We conducted a real-world case study at SIGDIAL 2024 with 42 participants, of whom 69% reported positive experiences. This study demonstrated the system's effectiveness in conducting interviews just like a human and marked the first employment of such a system at an international conference. The demonstration video is available at https://youtu.be/jCuw9g99KuE.
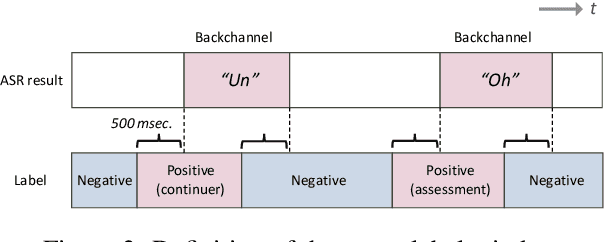
Yeah, Un, Oh: Continuous and Real-time Backchannel Prediction with Fine-tuning of Voice Activity Projection
Oct 21, 2024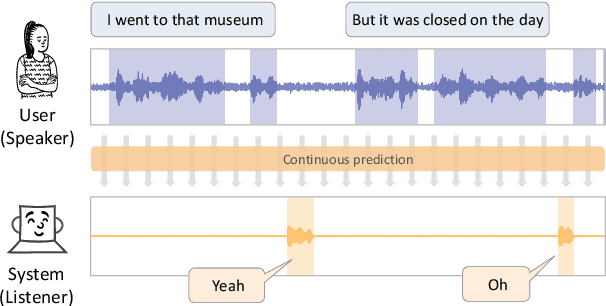
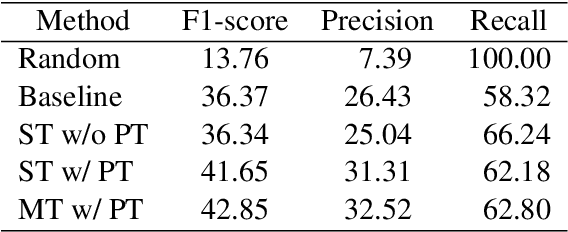

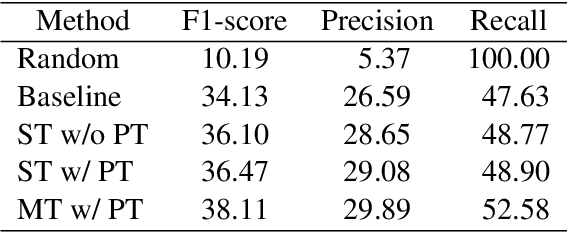
In human conversations, short backchannel utterances such as "yeah" and "oh" play a crucial role in facilitating smooth and engaging dialogue. These backchannels signal attentiveness and understanding without interrupting the speaker, making their accurate prediction essential for creating more natural conversational agents. This paper proposes a novel method for real-time, continuous backchannel prediction using a fine-tuned Voice Activity Projection (VAP) model. While existing approaches have relied on turn-based or artificially balanced datasets, our approach predicts both the timing and type of backchannels in a continuous and frame-wise manner on unbalanced, real-world datasets. We first pre-train the VAP model on a general dialogue corpus to capture conversational dynamics and then fine-tune it on a specialized dataset focused on backchannel behavior. Experimental results demonstrate that our model outperforms baseline methods in both timing and type prediction tasks, achieving robust performance in real-time environments. This research offers a promising step toward more responsive and human-like dialogue systems, with implications for interactive spoken dialogue applications such as virtual assistants and robots.
Analysis and Detection of Differences in Spoken User Behaviors between Autonomous and Wizard-of-Oz Systems
Oct 04, 2024
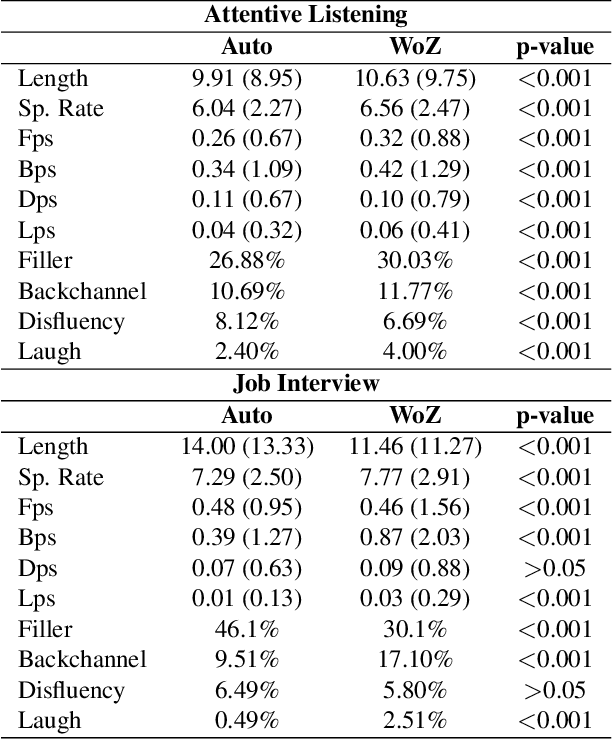
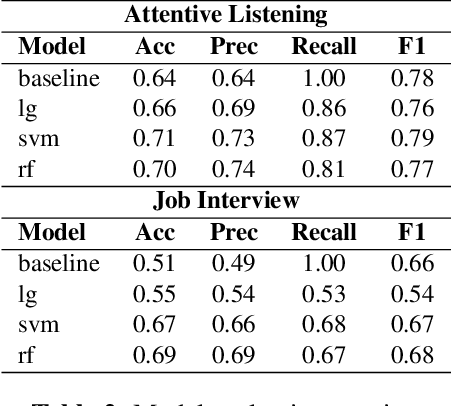
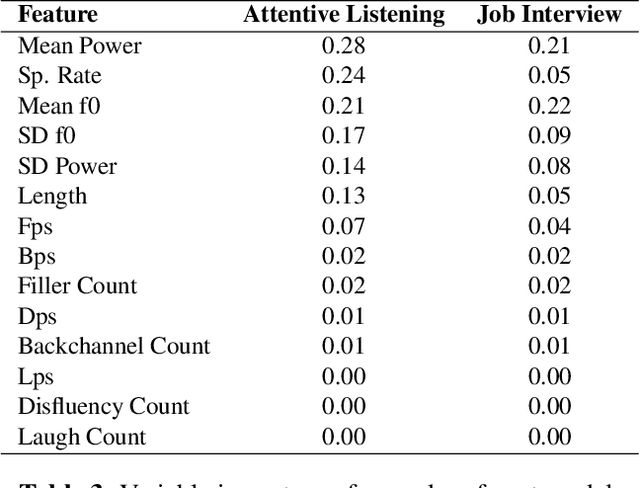
This study examined users' behavioral differences in a large corpus of Japanese human-robot interactions, comparing interactions between a tele-operated robot and an autonomous dialogue system. We analyzed user spoken behaviors in both attentive listening and job interview dialogue scenarios. Results revealed significant differences in metrics such as speech length, speaking rate, fillers, backchannels, disfluencies, and laughter between operator-controlled and autonomous conditions. Furthermore, we developed predictive models to distinguish between operator and autonomous system conditions. Our models demonstrated higher accuracy and precision compared to the baseline model, with several models also achieving a higher F1 score than the baseline.
Evaluation of a semi-autonomous attentive listening system with takeover prompting
Feb 21, 2024The handling of communication breakdowns and loss of engagement is an important aspect of spoken dialogue systems, particularly for chatting systems such as attentive listening, where the user is mostly speaking. We presume that a human is best equipped to handle this task and rescue the flow of conversation. To this end, we propose a semi-autonomous system, where a remote operator can take control of an autonomous attentive listening system in real-time. In order to make human intervention easy and consistent, we introduce automatic detection of low interest and engagement to provide explicit takeover prompts to the remote operator. We implement this semi-autonomous system which detects takeover points for the operator and compare it to fully tele-operated and fully autonomous attentive listening systems. We find that the semi-autonomous system is generally perceived more positively than the autonomous system. The results suggest that identifying points of conversation when the user starts to lose interest may help us improve a fully autonomous dialogue system.
Acknowledgment of Emotional States: Generating Validating Responses for Empathetic Dialogue
Feb 20, 2024



In the realm of human-AI dialogue, the facilitation of empathetic responses is important. Validation is one of the key communication techniques in psychology, which entails recognizing, understanding, and acknowledging others' emotional states, thoughts, and actions. This study introduces the first framework designed to engender empathetic dialogue with validating responses. Our approach incorporates a tripartite module system: 1) validation timing detection, 2) users' emotional state identification, and 3) validating response generation. Utilizing Japanese EmpatheticDialogues dataset - a textual-based dialogue dataset consisting of 8 emotional categories from Plutchik's wheel of emotions - the Task Adaptive Pre-Training (TAPT) BERT-based model outperforms both random baseline and the ChatGPT performance, in term of F1-score, in all modules. Further validation of our model's efficacy is confirmed in its application to the TUT Emotional Storytelling Corpus (TESC), a speech-based dialogue dataset, by surpassing both random baseline and the ChatGPT. This consistent performance across both textual and speech-based dialogues underscores the effectiveness of our framework in fostering empathetic human-AI communication.