 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Building Closed-Domain Chat Dialogue Systems
Nov 20, 2019



This paper presents HRIChat, a framework for developing closed-domain chat dialogue systems. Being able to engage in chat dialogues has been found effective for improving communication between humans and dialogue systems. This paper focuses on closed-domain systems because they would be useful when combined with task-oriented dialogue systems in the same domain. HRIChat enables domain-dependent language understanding so that it can deal well with domain-specific utterances. In addition, HRIChat makes it possible to integrate state transition network-based dialogue management and reaction-based dialogue management. FoodChatbot, which is an application in the food and restaurant domain, has been developed and evaluated through a user study. Its results suggest that reasonably good systems can be developed with HRIChat. This paper also reports lessons learned from the development and evaluation of FoodChatbot.
Binarized Knowledge Graph Embeddings
Feb 08, 2019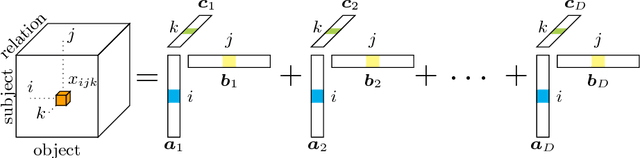
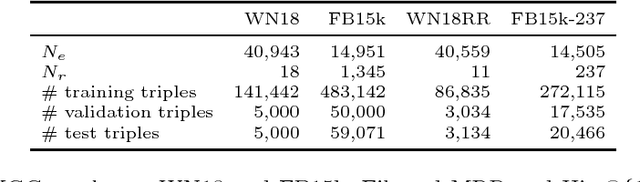
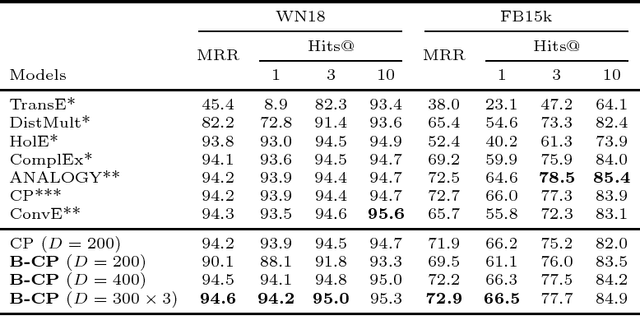

Tensor factorization has become an increasingly popular approach to knowledge graph completion(KGC), which is the task of automatically predicting missing facts in a knowledge graph. However, even with a simple model like CANDECOMP/PARAFAC(CP) tensor decomposition, KGC on existing knowledge graphs is impractical in resource-limited environments, as a large amount of memory is required to store parameters represented as 32-bit or 64-bit floating point numbers. This limitation is expected to become more stringent as existing knowledge graphs, which are already huge, keep steadily growing in scale. To reduce the memory requirement, we present a method for binarizing the parameters of the CP tensor decomposition by introducing a quantization function to the optimization problem. This method replaces floating point-valued parameters with binary ones after training, which drastically reduces the model size at run time. We investigate the trade-off between the quality and size of tensor factorization models for several KGC benchmark datasets. In our experiments, the proposed method successfully reduced the model size by more than an order of magnitude while maintaining the task performance. Moreover, a fast score computation technique can be developed with bitwise operations.