 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROS Help Desk: GenAI Powered, User-Centric Framework for ROS Error Diagnosis and Debugging
Jul 10, 2025As the robotics systems increasingly integrate into daily life, from smart home assistants to the new-wave of industrial automation systems (Industry 4.0), there's an increasing need to bridge the gap between complex robotic systems and everyday users. The Robot Operating System (ROS) is a flexible framework often utilised in writing robot software, providing tools and libraries for building complex robotic systems. However, ROS's distributed architecture and technical messaging system create barriers for understanding robot status and diagnosing errors. This gap can lead to extended maintenance downtimes, as users with limited ROS knowledge may struggle to quickly diagnose and resolve system issues. Moreover, this deficit in expertise often delays proactive maintenance and troubleshooting, further increasing the frequency and duration of system interruptions. ROS Help Desk provides intuitive error explanations and debugging support, dynamically customized to users of varying expertise levels. It features user-centric debugging tools that simplify error diagnosis, implements proactive error detection capabilities to reduce downtime, and integrates multimodal data processing for comprehensive system state understanding across multi-sensor data (e.g., lidar, RGB). Testing qualitatively and quantitatively with artificially induced errors demonstrates the system's ability to proactively and accurately diagnose problems, ultimately reducing maintenance time and fostering more effective human-robot collaboration.
'What did the Robot do in my Absence?' Video Foundation Models to Enhance Intermittent Supervision
Nov 15, 2024



This paper investigates the application of Video Foundation Models (ViFMs) for generating robot data summaries to enhance intermittent human supervision of robot teams. We propose a novel framework that produces both generic and query-driven summaries of long-duration robot vision data in three modalities: storyboards, short videos, and text. Through a user study involving 30 participants, we evaluate the efficacy of these summary methods in allowing operators to accurately retrieve the observations and actions that occurred while the robot was operating without supervision over an extended duration (40 min). Our findings reveal that query-driven summaries significantly improve retrieval accuracy compared to generic summaries or raw data, albeit with increased task duration. Storyboards are found to be the most effective presentation modality, especially for object-related queries. This work represents, to our knowledge, the first zero-shot application of ViFMs for generating multi-modal robot-to-human communication in intermittent supervision contexts, demonstrating both the promise and limitations of these models in human-robot interaction (HRI) scenarios.
Multi-modal Scene-compliant User Intention Estimation for Navigation
Jun 13, 2021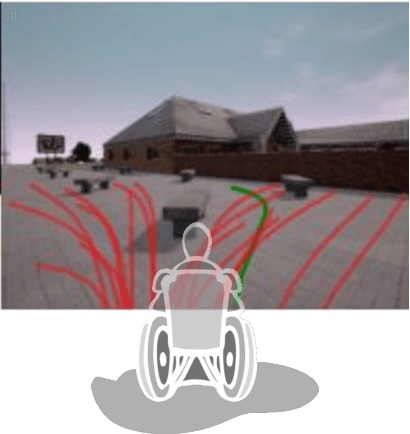
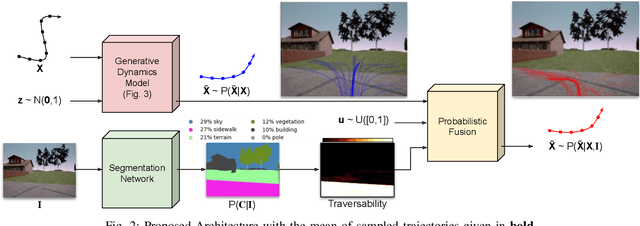
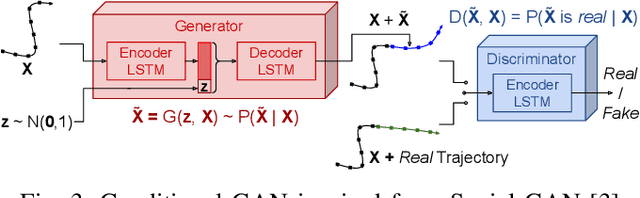

A multi-modal framework to generated user intention distributions when operating a mobile vehicle is proposed in this work. The model learns from past observed trajectories and leverages traversability information derived from the visual surroundings to produce a set of future trajectories, suitable to be directly embedded into a perception-action shared control strategy on a mobile agent, or as a safety layer to supervise the prudent operation of the vehicle. We base our solution on a conditional Generative Adversarial Network with Long-Short Term Memory cells to capture trajectory distributions conditioned on past trajectories, further fused with traversability probabilities derived from visual segmentation with a Convolutional Neural Network. The proposed data-driven framework results in a significant reduction in error of the predicted trajectories (versus the ground truth) from comparable strategies in the literature (e.g. Social-GAN) that fail to account for information other than the agent's past history. Experiments were conducted on a dataset collected with a custom wheelchair model built onto the open-source urban driving simulator CARLA, proving also that the proposed framework can be used with a small, un-annotated dataset.