 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Method for Learning Large-Scale Computational Construction Grammars from Semantically Annotated Corpora
Mar 13, 2026We present a method for learning large-scale, broad-coverage construction grammars from corpora of language use. Starting from utterances annotated with constituency structure and semantic frames, the method facilitates the learning of human-interpretable computational construction grammars that capture the intricate relationship between syntactic structures and the semantic relations they express. The resulting grammars consist of networks of tens of thousands of constructions formalised within the Fluid Construction Grammar framework. Not only do these grammars support the frame-semantic analysis of open-domain text, they also house a trove of information about the syntactico-semantic usage patterns present in the data they were learnt from. The method and learnt grammars contribute to the scaling of usage-based, constructionist approaches to language, as they corroborate the scalability of a number of fundamental construction grammar conjectures while also providing a practical instrument for the constructionist study of English argument structure in broad-coverage corpora.
PyFCG: Fluid Construction Grammar in Python
May 19, 2025We present PyFCG, an open source software library that ports Fluid Construction Grammar (FCG) to the Python programming language. PyFCG enables its users to seamlessly integrate FCG functionality into Python programs, and to use FCG in combination with other libraries within Python's rich ecosystem. Apart from a general description of the library, this paper provides three walkthrough tutorials that demonstrate example usage of PyFCG in typical use cases of FCG: (i) formalising and testing construction grammar analyses, (ii) learning usage-based construction grammars from corpora, and (iii) implementing agent-based experiments on emergent communication.
The Proof is in the Almond Cookies
Jan 03, 2025This paper presents a case study on how to process cooking recipes (and more generally, how-to instructions) in a way that makes it possible for a robot or artificial cooking assistant to support human chefs in the kitchen. Such AI assistants would be of great benefit to society, as they can help to sustain the autonomy of aging adults or people with a physical impairment, or they may reduce the stress in a professional kitchen. We propose a novel approach to computational recipe understanding that mimics the human sense-making process, which is narrative-based. Using an English recipe for almond crescent cookies as illustration, we show how recipes can be modelled as rich narrative structures by integrating various knowledge sources such as language processing, ontologies, and mental simulation. We show how such narrative structures can be used for (a) dealing with the challenges of recipe language, such as zero anaphora, (b) optimizing a robot's planning process, (c) measuring how well an AI system understands its current tasks, and (d) allowing recipe annotations to become language-independent.
The Computational Learning of Construction Grammars: State of the Art and Prospective Roadmap
Jul 10, 2024This paper documents and reviews the state of the art concerning computational models of construction grammar learning. It brings together prior work on the computational learning of form-meaning pairings, which has so far been studied in several distinct areas of research. The goal of this paper is threefold. First of all, it aims to synthesise the variety of methodologies that have been proposed to date and the results that have been obtained. Second, it aims to identify those parts of the challenge that have been successfully tackled and reveal those that require further research. Finally, it aims to provide a roadmap which can help to boost and streamline future research efforts on the computational learning of large-scale, usage-based construction grammars.
Decentralised Emergence of Robust and Adaptive Linguistic Conventions in Populations of Autonomous Agents Grounded in Continuous Worlds
Jan 16, 2024This paper introduces a methodology through which a population of autonomous agents can establish a linguistic convention that enables them to refer to arbitrary entities that they observe in their environment. The linguistic convention emerges in a decentralised manner through local communicative interactions between pairs of agents drawn from the population. The convention consists of symbolic labels (word forms) associated to concept representations (word meanings) that are grounded in a continuous feature space. The concept representations of each agent are individually constructed yet compatible on a communicative level. Through a range of experiments, we show (i) that the methodology enables a population to converge on a communicatively effective, coherent and human-interpretable linguistic convention, (ii) that it is naturally robust against sensor defects in individual agents, (iii) that it can effectively deal with noisy observations, uncalibrated sensors and heteromorphic populations, (iv) that the method is adequate for continual learning, and (v) that the convention self-adapts to changes in the environment and communicative needs of the agents.
Construction Grammar and Artificial Intelligence
Aug 31, 2023In this chapter, we argue that it is highly beneficial for the contemporary construction grammarian to have a thorough understanding of the strong relationship between the research fields of construction grammar and artificial intelligence. We start by unravelling the historical links between the two fields, showing that their relationship is rooted in a common attitude towards human communication and language. We then discuss the first direction of influence, focussing in particular on how insights and techniques from the field of artificial intelligence play an important role in operationalising, validating and scaling constructionist approaches to language. We then proceed to the second direction of influence, highlighting the relevance of construction grammar insights and analyses to the artificial intelligence endeavour of building truly intelligent agents. We support our case with a variety of illustrative examples and conclude that the further elaboration of this relationship will play a key role in shaping the future of the field of construction grammar.
Usage-based learning of grammatical categories
Apr 14, 2022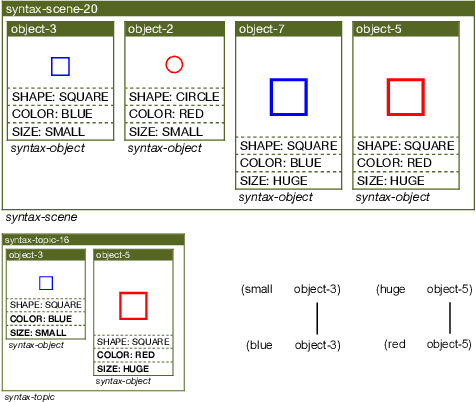
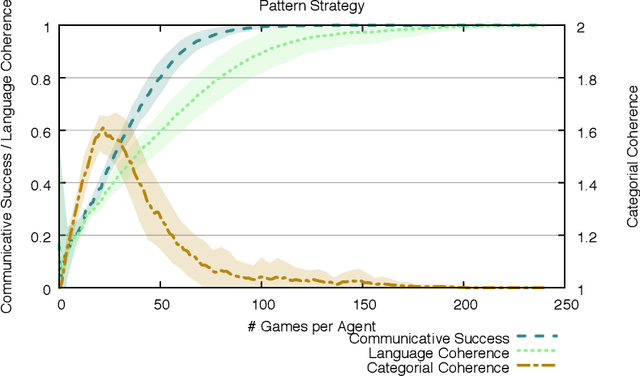
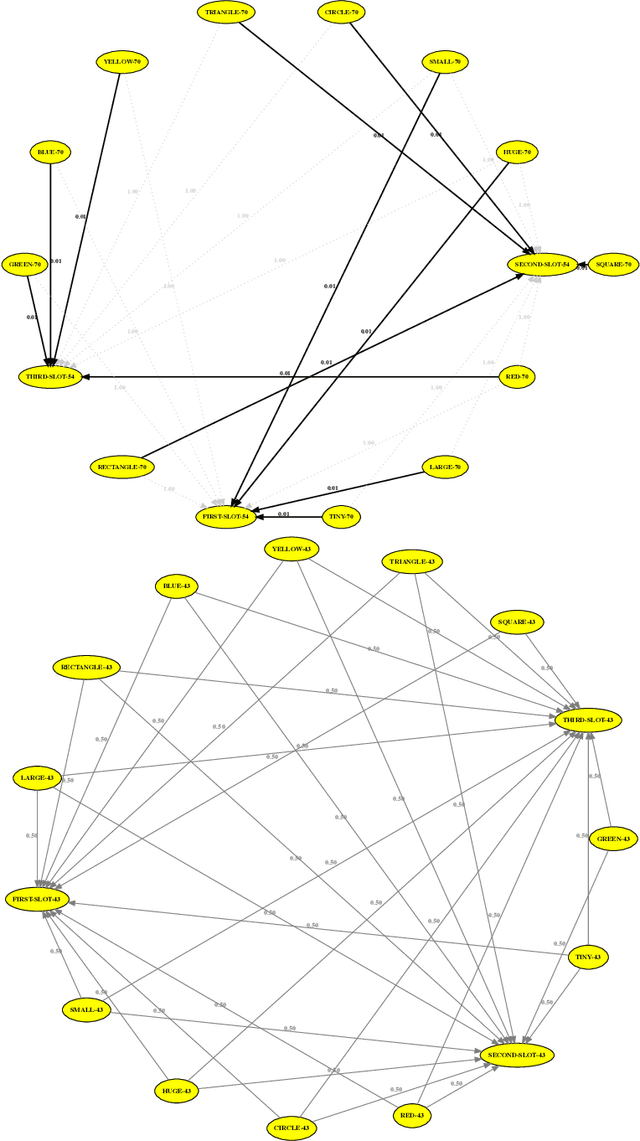
Human languages use a wide range of grammatical categories to constrain which words or phrases can fill certain slots in grammatical patterns and to express additional meanings, such as tense or aspect, through morpho-syntactic means. These grammatical categories, which are most often language-specific and changing over time, are difficult to define and learn. This paper raises the question how these categories can be acquired and where they have come from. We explore a usage-based approach. This means that categories and grammatical constructions are selected and aligned by their success in language interactions. We report on a multi-agent experiment in which agents are endowed with mechanisms for understanding and producing utterances as well as mechanisms for expanding their inventories using a meta-level learning process based on pro- and anti-unification. We show that a categorial type network which has scores based on the success in a language interaction leads to the spontaneous formation of grammatical categories in tandem with the formation of grammatical patterns.
* Published after double-blind review as: Steels, L., Van Eecke, P. & Beuls, K. (2018). Usage-based learning of grammatical categories. Belgian/Netherlands Artificial Intelligence Conference (BNAIC) 2018 Preproceedings (pp. 253-264)
A Practical Guide to Studying Emergent Communication through Grounded Language Games
Apr 20, 2020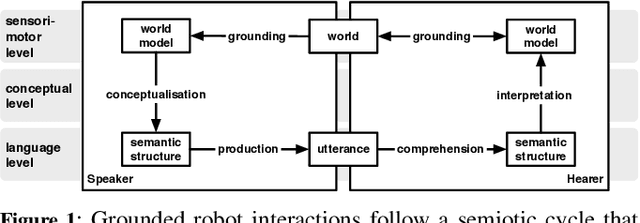



The question of how an effective and efficient communication system can emerge in a population of agents that need to solve a particular task attracts more and more attention from researchers in many fields, including artificial intelligence, linguistics and statistical physics. A common methodology for studying this question consists of carrying out multi-agent experiments in which a population of agents takes part in a series of scripted and task-oriented communicative interactions, called 'language games'. While each individual language game is typically played by two agents in the population, a large series of games allows the population to converge on a shared communication system. Setting up an experiment in which a rich system for communicating about the real world emerges is a major enterprise, as it requires a variety of software components for running multi-agent experiments, for interacting with sensors and actuators, for conceptualising and interpreting semantic structures, and for mapping between these semantic structures and linguistic utterances. The aim of this paper is twofold. On the one hand, it introduces a high-level robot interface that extends the Babel software system, presenting for the first time a toolkit that provides flexible modules for dealing with each subtask involved in running advanced grounded language game experiments. On the other hand, it provides a practical guide to using the toolkit for implementing such experiments, taking a grounded colour naming game experiment as a didactic example.
Re-conceptualising the Language Game Paradigm in the Framework of Multi-Agent Reinforcement Learning
Apr 09, 2020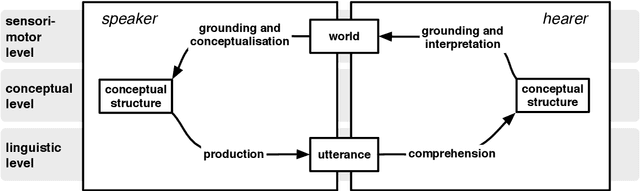
In this paper, we formulate the challenge of re-conceptualising the language game experimental paradigm in the framework of multi-agent reinforcement learning (MARL). If successful, future language game experiments will benefit from the rapid and promising methodological advances in the MARL community, while future MARL experiments on learning emergent communication will benefit from the insights and results gained from language game experiments. We strongly believe that this cross-pollination has the potential to lead to major breakthroughs in the modelling of how human-like languages can emerge and evolve in multi-agent systems.
Facilitating on-line opinion dynamics by mining expressions of causation. The case of climate change debates on The Guardian
Dec 03, 2019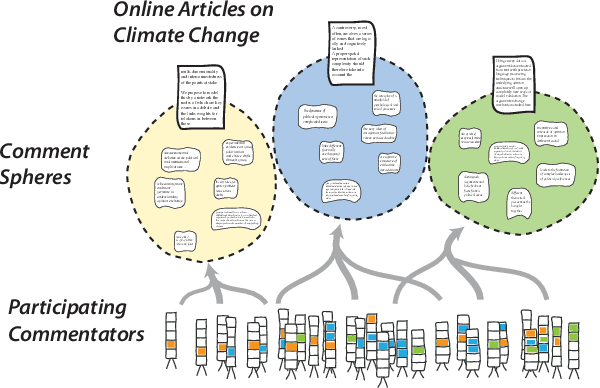


News website comment sections are spaces where potentially conflicting opinions and beliefs are voiced. Addressing questions of how to study such cultural and societal conflicts through technological means, the present article critically examines possibilities and limitations of machine-guided exploration and potential facilitation of on-line opinion dynamics. These investigations are guided by a discussion of an experimental observatory for mining and analyzing opinions from climate change-related user comments on news articles from the TheGuardian.com. This observatory combines causal mapping methods with computational text analysis in order to mine beliefs and visualize opinion landscapes based on expressions of causation. By (1) introducing digital methods and open infrastructures for data exploration and analysis and (2) engaging in debates about the implications of such methods and infrastructures, notably in terms of the leap from opinion observation to debate facilitation, the article aims to make a practical and theoretical contribution to the study of opinion dynamics and conflict in new media environments.