 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Better Datasets: Seven Recommendations for Responsible Design from Dataset Creators
Aug 30, 2024

The increasing demand for high-quality datasets in machine learning has raised concerns about the ethical and responsible creation of these datasets. Dataset creators play a crucial role in developing responsible practices, yet their perspectives and expertise have not yet been highlighted in the current literature. In this paper, we bridge this gap by presenting insights from a qualitative study that included interviewing 18 leading dataset creators about the current state of the field. We shed light on the challenges and considerations faced by dataset creators, and our findings underscore the potential for deeper collaboration, knowledge sharing, and collective development. Through a close analysis of their perspectives, we share seven central recommendations for improving responsible dataset creation, including issues such as data quality, documentation, privacy and consent, and how to mitigate potential harms from unintended use cases. By fostering critical reflection and sharing the experiences of dataset creators, we aim to promote responsible dataset creation practices and develop a nuanced understanding of this crucial but often undervalued aspect of machine learning research.
* 21 pages, 1 figure
The Problem of Zombie Datasets:A Framework For Deprecating Datasets
Oct 18, 2021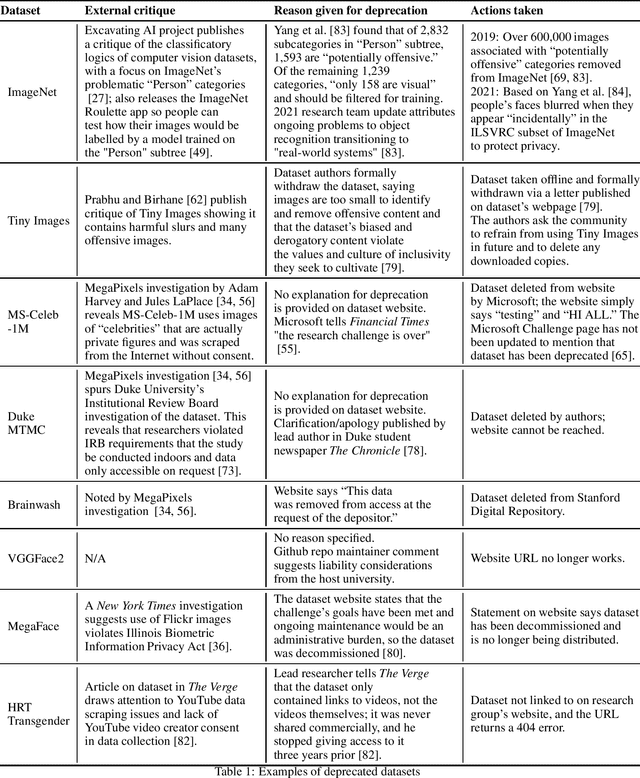
What happens when a machine learning dataset is deprecated for legal, ethical, or technical reasons, but continues to be widely used? In this paper, we examine the public afterlives of several prominent deprecated or redacted datasets, including ImageNet, 80 Million Tiny Images, MS-Celeb-1M, Duke MTMC, Brainwash, and HRT Transgender, in order to inform a framework for more consistent, ethical, and accountable dataset deprecation. Building on prior research, we find that there is a lack of consistency, transparency, and centralized sourcing of information on the deprecation of datasets, and as such, these datasets and their derivatives continue to be cited in papers and circulate online. These datasets that never die -- which we term "zombie datasets" -- continue to inform the design of production-level systems, causing technical, legal, and ethical challenges; in so doing, they risk perpetuating the harms that prompted their supposed withdrawal, including concerns around bias, discrimination, and privacy. Based on this analysis, we propose a Dataset Deprecation Framework that includes considerations of risk, mitigation of impact, appeal mechanisms, timeline, post-deprecation protocol, and publication checks that can be adapted and implemented by the machine learning community. Drawing on work on datasheets and checklists, we further offer two sample dataset deprecation sheets and propose a centralized repository that tracks which datasets have been deprecated and could be incorporated into the publication protocols of venues like NeurIPS.
Datasheets for Datasets
Jul 09, 2018


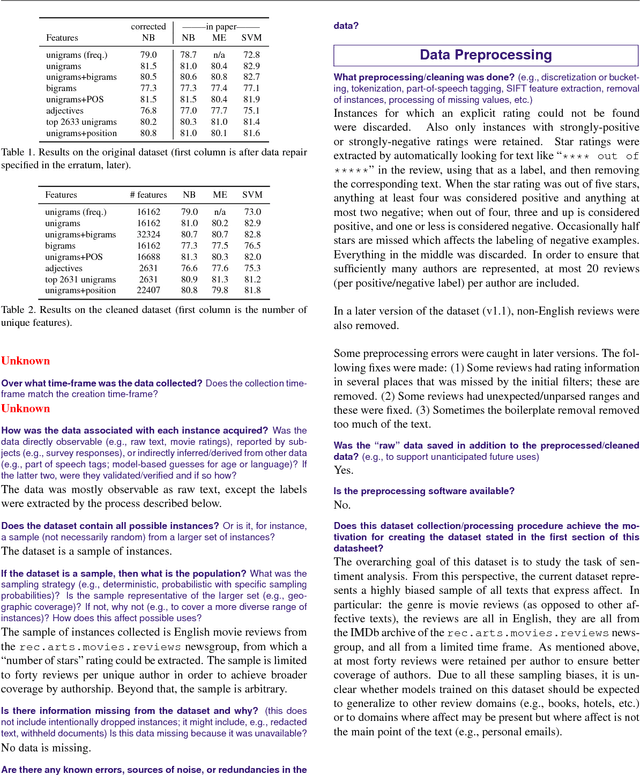
Currently there is no standard way to identify how a dataset was created, and what characteristics, motivations, and potential skews it represents. To begin to address this issue, we propose the concept of a datasheet for datasets, a short document to accompany public datasets, commercial APIs, and pretrained models. The goal of this proposal is to enable better communication between dataset creators and users, and help the AI community move toward greater transparency and accountability. By analogy, in computer hardware, it has become industry standard to accompany everything from the simplest components (e.g., resistors), to the most complex microprocessor chips, with datasheets detailing standard operating characteristics, test results, recommended usage, and other information. We outline some of the questions a datasheet for datasets should answer. These questions focus on when, where, and how the training data was gathered, its recommended use cases, and, in the case of human-centric datasets, information regarding the subjects' demographics and consent as applicable. We develop prototypes of datasheets for two well-known datasets: Labeled Faces in The Wild and the Pang \& Lee Polarity Dataset.