 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatasheets for Datasets
Jul 09, 2018


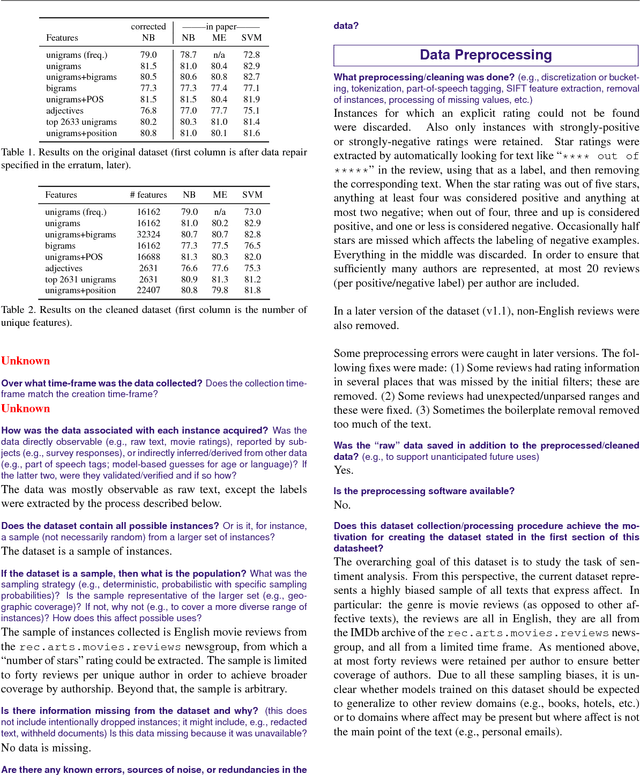
Currently there is no standard way to identify how a dataset was created, and what characteristics, motivations, and potential skews it represents. To begin to address this issue, we propose the concept of a datasheet for datasets, a short document to accompany public datasets, commercial APIs, and pretrained models. The goal of this proposal is to enable better communication between dataset creators and users, and help the AI community move toward greater transparency and accountability. By analogy, in computer hardware, it has become industry standard to accompany everything from the simplest components (e.g., resistors), to the most complex microprocessor chips, with datasheets detailing standard operating characteristics, test results, recommended usage, and other information. We outline some of the questions a datasheet for datasets should answer. These questions focus on when, where, and how the training data was gathered, its recommended use cases, and, in the case of human-centric datasets, information regarding the subjects' demographics and consent as applicable. We develop prototypes of datasheets for two well-known datasets: Labeled Faces in The Wild and the Pang \& Lee Polarity Dataset.