 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-based Monitoring and Response System for Hospital Preparedness towards COVID-19 in Southeast Asia
Jul 30, 2020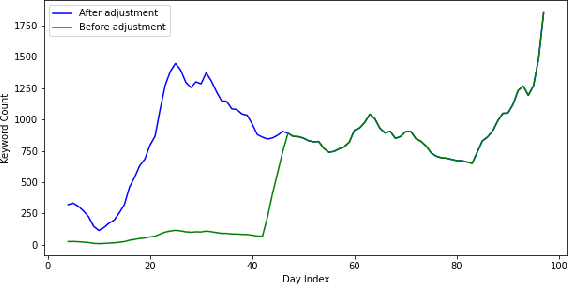
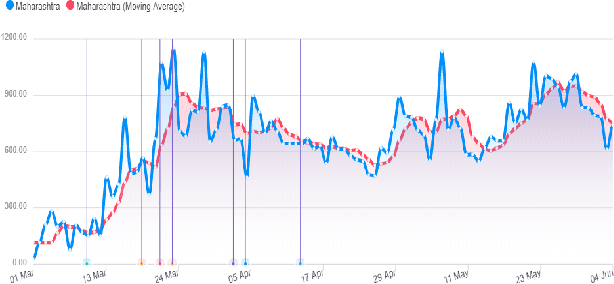
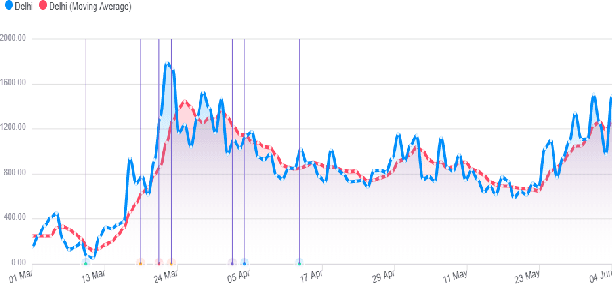
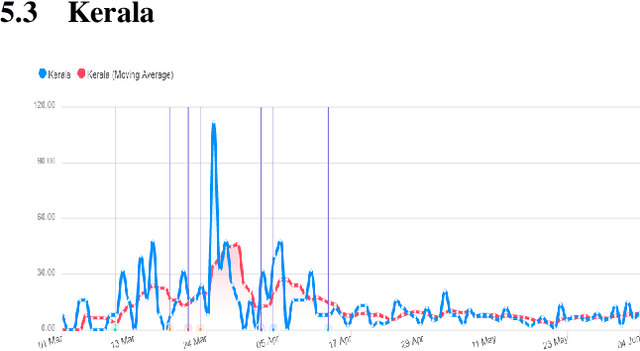
This research paper proposes a COVID-19 monitoring and response system to identify the surge in the volume of patients at hospitals and shortage of critical equipment like ventilators in South-east Asian countries, to understand the burden on health facilities. This can help authorities in these regions with resource planning measures to redirect resources to the regions identified by the model. Due to the lack of publicly available data on the influx of patients in hospitals, or the shortage of equipment, ICU units or hospital beds that regions in these countries might be facing, we leverage Twitter data for gleaning this information. The approach has yielded accurate results for states in India, and we are working on validating the model for the remaining countries so that it can serve as a reliable tool for authorities to monitor the burden on hospitals.
problemConquero at SemEval-2020 Task 12: Transformer and Soft label-based approaches
Jul 21, 2020
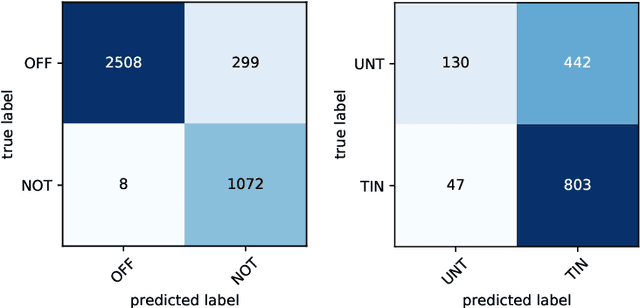

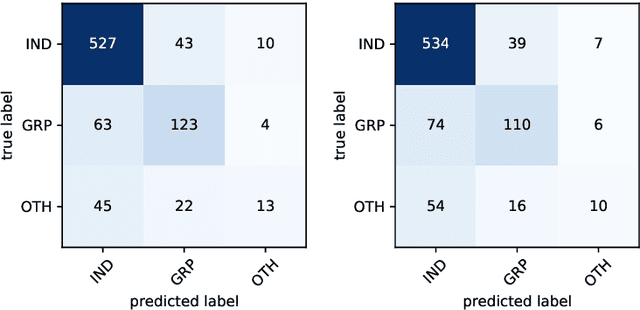
In this paper, we present various systems submitted by our team problemConquero for SemEval-2020 Shared Task 12 Multilingual Offensive Language Identification in Social Media. We participated in all the three sub-tasks of OffensEval-2020, and our final submissions during the evaluation phase included transformer-based approaches and a soft label-based approach. BERT based fine-tuned models were submitted for each language of sub-task A (offensive tweet identification). RoBERTa based fine-tuned model for sub-task B (automatic categorization of offense types) was submitted. We submitted two models for sub-task C (offense target identification), one using soft labels and the other using BERT based fine-tuned model. Our ranks for sub-task A were Greek-19 out of 37, Turkish-22 out of 46, Danish-26 out of 39, Arabic-39 out of 53, and English-20 out of 85. We achieved a rank of 28 out of 43 for sub-task B. Our best rank for sub-task C was 20 out of 39 using BERT based fine-tuned model.