 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeproblemConquero at SemEval-2020 Task 12: Transformer and Soft label-based approaches
Paper and Code

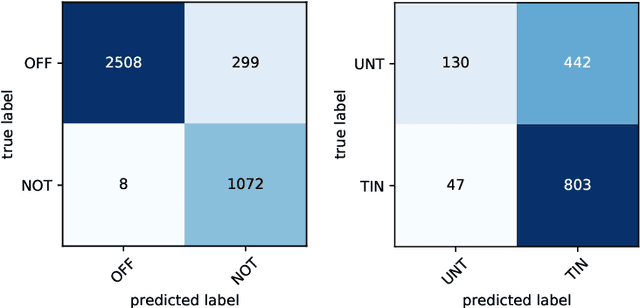

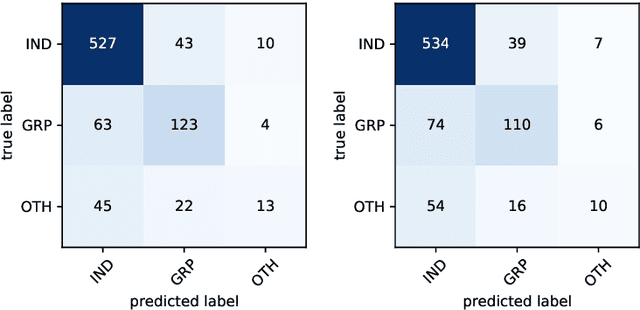
In this paper, we present various systems submitted by our team problemConquero for SemEval-2020 Shared Task 12 Multilingual Offensive Language Identification in Social Media. We participated in all the three sub-tasks of OffensEval-2020, and our final submissions during the evaluation phase included transformer-based approaches and a soft label-based approach. BERT based fine-tuned models were submitted for each language of sub-task A (offensive tweet identification). RoBERTa based fine-tuned model for sub-task B (automatic categorization of offense types) was submitted. We submitted two models for sub-task C (offense target identification), one using soft labels and the other using BERT based fine-tuned model. Our ranks for sub-task A were Greek-19 out of 37, Turkish-22 out of 46, Danish-26 out of 39, Arabic-39 out of 53, and English-20 out of 85. We achieved a rank of 28 out of 43 for sub-task B. Our best rank for sub-task C was 20 out of 39 using BERT based fine-tuned model.