 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Subword Segmentation for Text Comprehension
Nov 06, 2018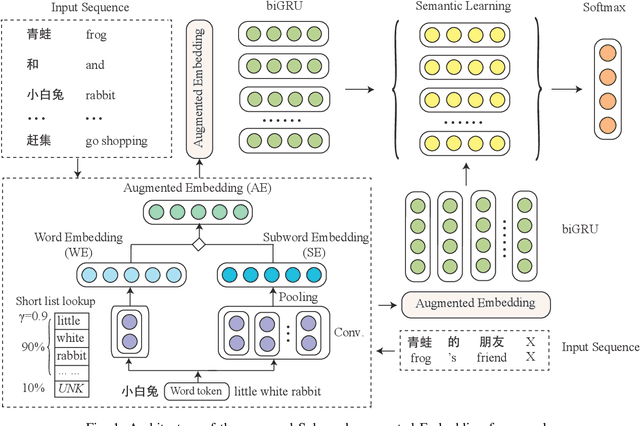
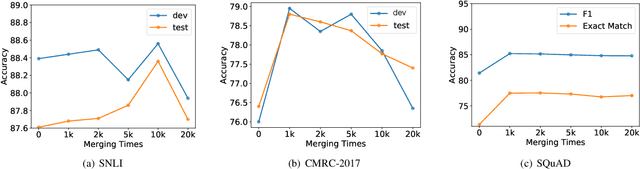


Character-level representations have been broadly adopted to alleviate the problem of effectively representing rare or complex words. However, character itself is not a natural minimal linguistic unit for representation or word embedding composing due to ignoring the linguistic coherence of consecutive characters inside word. This paper presents a general subword-augmented embedding framework for learning and composing computationally-derived subword-level representations. We survey a series of unsupervised segmentation methods for subword acquisition and different subword-augmented strategies for text understanding, showing that subword-augmented embedding significantly improves our baselines in multiple text understanding tasks on both English and Chinese languages.