 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA fully automated method for 3D individual tooth identification and segmentation in dental CBCT
Feb 11, 2021Accurate and automatic segmentation of three-dimensional (3D) individual teeth from cone-beam computerized tomography (CBCT) images is a challenging problem because of the difficulty in separating an individual tooth from adjacent teeth and its surrounding alveolar bone. Thus, this paper proposes a fully automated method of identifying and segmenting 3D individual teeth from dental CBCT images. The proposed method addresses the aforementioned difficulty by developing a deep learning-based hierarchical multi-step model. First, it automatically generates upper and lower jaws panoramic images to overcome the computational complexity caused by high-dimensional data and the curse of dimensionality associated with limited training dataset. The obtained 2D panoramic images are then used to identify 2D individual teeth and capture loose- and tight- regions of interest (ROIs) of 3D individual teeth. Finally, accurate 3D individual tooth segmentation is achieved using both loose and tight ROIs. Experimental results showed that the proposed method achieved an F1-score of 93.35% for tooth identification and a Dice similarity coefficient of 94.79% for individual 3D tooth segmentation. The results demonstrate that the proposed method provides an effective clinical and practical framework for digital dentistry.
Framelet Pooling Aided Deep Learning Network : The Method to Process High Dimensional Medical Data
Jul 25, 2019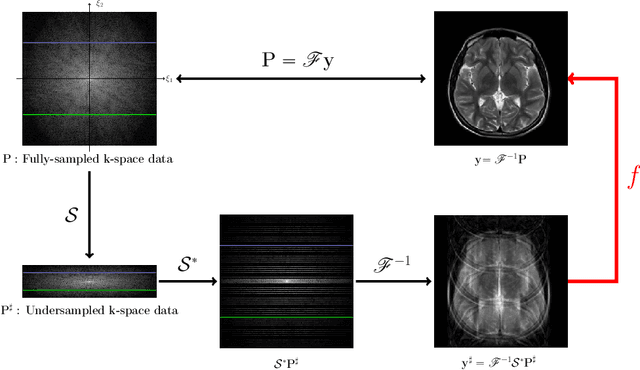
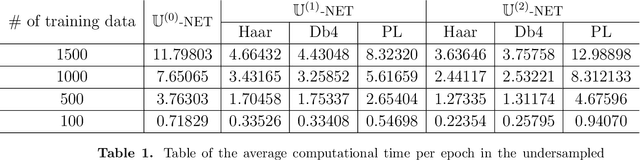
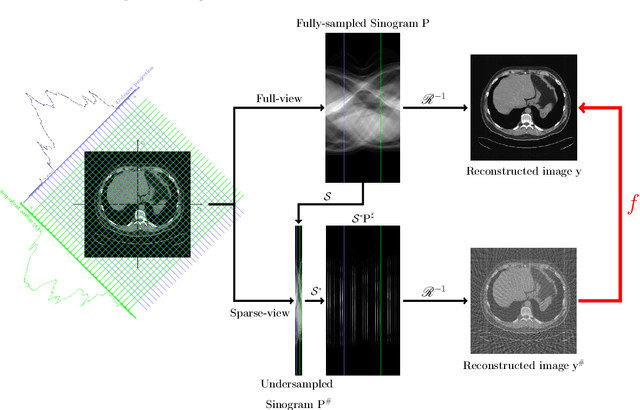
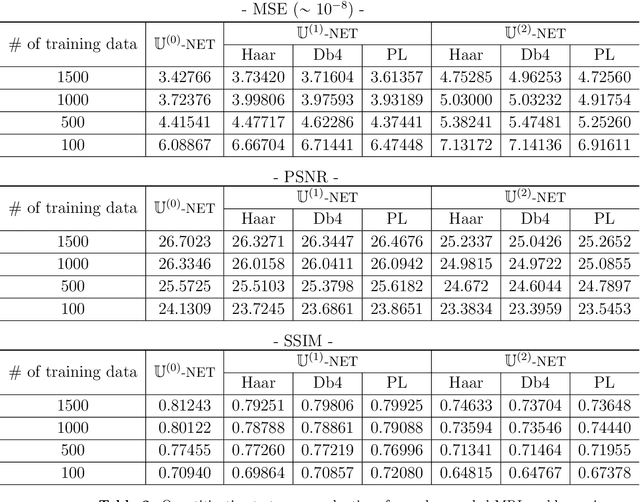
Machine learning-based analysis of medical images often faces several hurdles, such as the lack of training data, the curse of dimensionality problem, and the generalization issues. One of the main difficulties is that there exists computational cost problem in dealing with input data of large size matrices which represent medical images. The purpose of this paper is to introduce a framelet-pooling aided deep learning method for mitigating computational bundle, caused by large dimensionality. By transforming high dimensional data into low dimensional components by filter banks with preserving detailed information, the proposed method aims to reduce the complexity of the neural network and computational costs significantly during the learning process. Various experiments show that our method is comparable to the standard unreduced learning method, while reducing computational burdens by decomposing large-sized learning tasks into several small-scale learning tasks.