 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAC2L-GAD: Active Counterfactual Contrastive Learning for Graph Anomaly Detection
Jan 29, 2026Graph anomaly detection aims to identify abnormal patterns in networks, but faces significant challenges from label scarcity and extreme class imbalance. While graph contrastive learning offers a promising unsupervised solution, existing methods suffer from two critical limitations: random augmentations break semantic consistency in positive pairs, while naive negative sampling produces trivial, uninformative contrasts. We propose AC2L-GAD, an Active Counterfactual Contrastive Learning framework that addresses both limitations through principled counterfactual reasoning. By combining information-theoretic active selection with counterfactual generation, our approach identifies structurally complex nodes and generates anomaly-preserving positive augmentations alongside normal negative counterparts that provide hard contrasts, while restricting expensive counterfactual generation to a strategically selected subset. This design reduces computational overhead by approximately 65% compared to full-graph counterfactual generation while maintaining detection quality. Experiments on nine benchmark datasets, including real-world financial transaction graphs from GADBench, show that AC2L-GAD achieves competitive or superior performance compared to state-of-the-art baselines, with notable gains in datasets where anomalies exhibit complex attribute-structure interactions.
A Preference Random Walk Algorithm for Link Prediction through Mutual Influence Nodes in Complex Networks
May 20, 2021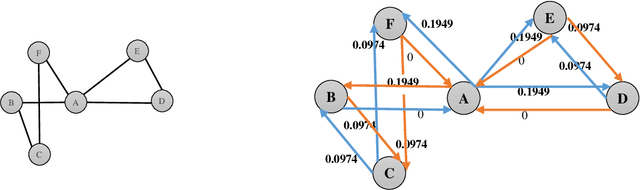
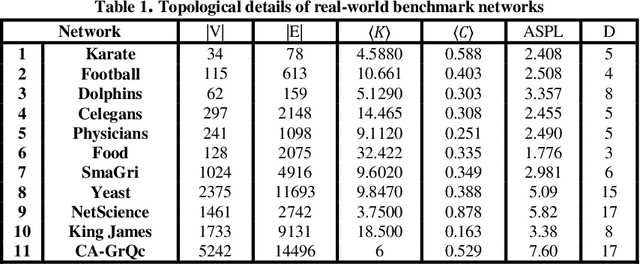
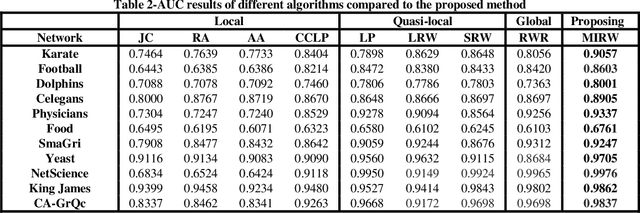
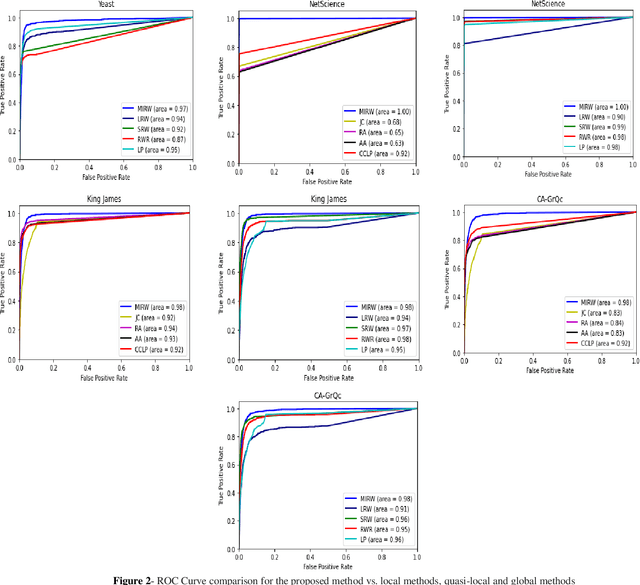
Predicting links in complex networks has been one of the essential topics within the realm of data mining and science discovery over the past few years. This problem remains an attempt to identify future, deleted, and redundant links using the existing links in a graph. Local random walk is considered to be one of the most well-known algorithms in the category of quasi-local methods. It traverses the network using the traditional random walk with a limited number of steps, randomly selecting one adjacent node in each step among the nodes which have equal importance. Then this method uses the transition probability between node pairs to calculate the similarity between them. However, in most datasets, this method is not able to perform accurately in scoring remarkably similar nodes. In the present article, an efficient method is proposed for improving local random walk by encouraging random walk to move, in every step, towards the node which has a stronger influence. Therefore, the next node is selected according to the influence of the source node. To do so, using mutual information, the concept of the asymmetric mutual influence of nodes is presented. A comparison between the proposed method and other similarity-based methods (local, quasi-local, and global) has been performed, and results have been reported for 11 real-world networks. It had a higher prediction accuracy compared with other link prediction approaches.
Presentation a Trust Walker for rating prediction in Recommender System with Biased Random Walk: Effects of H-index Centrality, Similarity in Items and Friends
Sep 10, 2020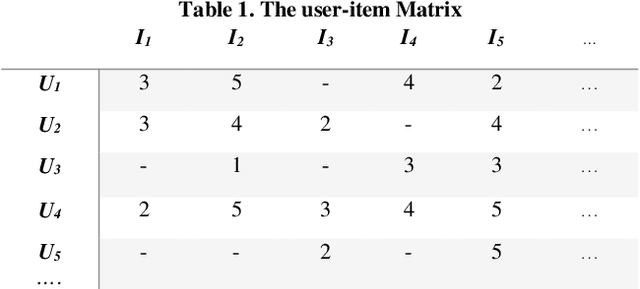

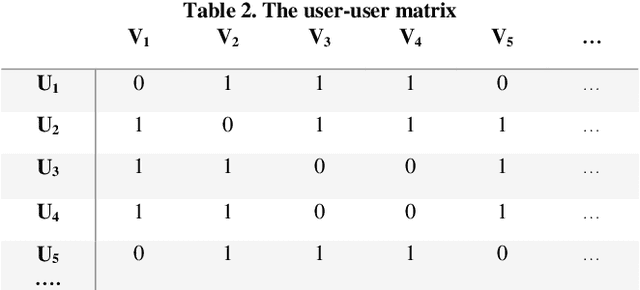
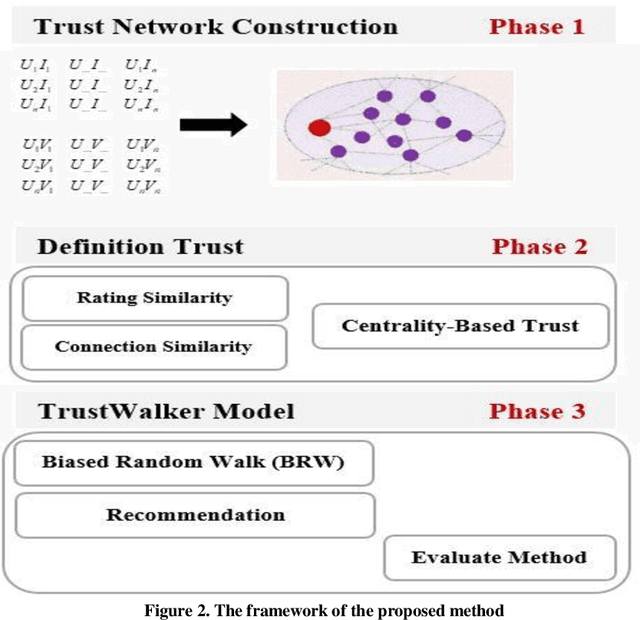
The use of recommender systems has increased dramatically to assist online social network users in the decision-making process and selecting appropriate items. On the other hand, due to many different items, users cannot score a wide range of them, and usually, there is a scattering problem for the matrix created for users. To solve the problem, the trust-based recommender systems are applied to predict the score of the desired item for the user. Various criteria have been considered to define trust, and the degree of trust between users is usually calculated based on these criteria. In this regard, it is impossible to obtain the degree of trust for all users because of the large number of them in social networks. Also, for this problem, researchers use different modes of the Random Walk algorithm to randomly visit some users, study their behavior, and gain the degree of trust between them. In the present study, a trust-based recommender system is presented that predicts the score of items that the target user has not rated, and if the item is not found, it offers the user the items dependent on that item that are also part of the user's interests. In a trusted network, by weighting the edges between the nodes, the degree of trust is determined, and a TrustWalker is developed, which uses the Biased Random Walk (BRW) algorithm to move between the nodes. The weight of the edges is effective in the selection of random steps. The implementation and evaluation of the present research method have been carried out on three datasets named Epinions, Flixster, and FilmTrust; the results reveal the high efficiency of the proposed method.
A Novel Community Detection Based Genetic Algorithm for Feature Selection
Aug 08, 2020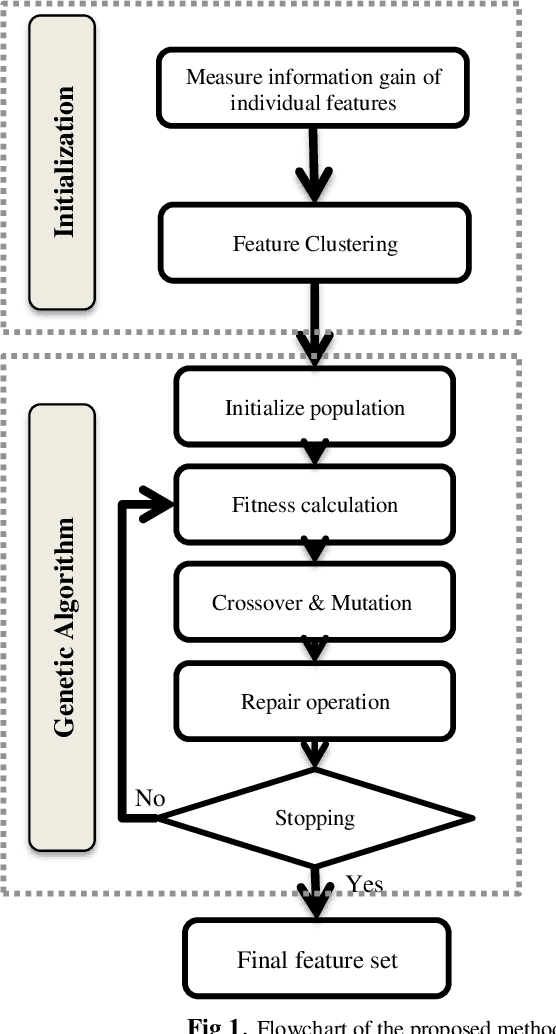
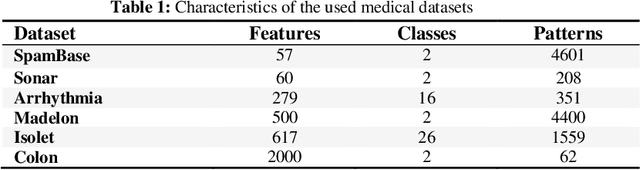
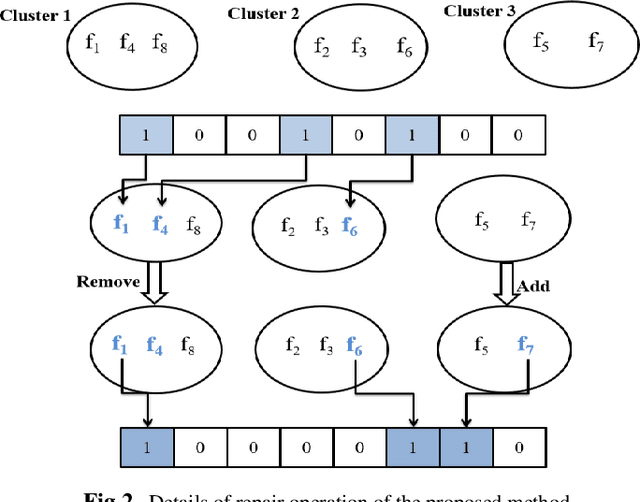

The selection of features is an essential data preprocessing stage in data mining. The core principle of feature selection seems to be to pick a subset of possible features by excluding features with almost no predictive information as well as highly associated redundant features. In the past several years, a variety of meta-heuristic methods were introduced to eliminate redundant and irrelevant features as much as possible from high-dimensional datasets. Among the main disadvantages of present meta-heuristic based approaches is that they are often neglecting the correlation between a set of selected features. In this article, for the purpose of feature selection, the authors propose a genetic algorithm based on community detection, which functions in three steps. The feature similarities are calculated in the first step. The features are classified by community detection algorithms into clusters throughout the second step. In the third step, features are picked by a genetic algorithm with a new community-based repair operation. Nine benchmark classification problems were analyzed in terms of the performance of the presented approach. Also, the authors have compared the efficiency of the proposed approach with the findings from four available algorithms for feature selection. The findings indicate that the new approach continuously yields improved classification accuracy.
Review of Swarm Intelligence-based Feature Selection Methods
Aug 07, 2020
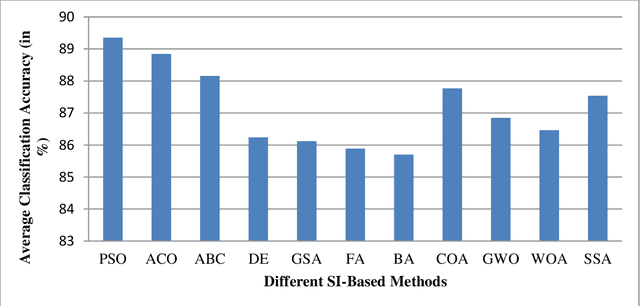
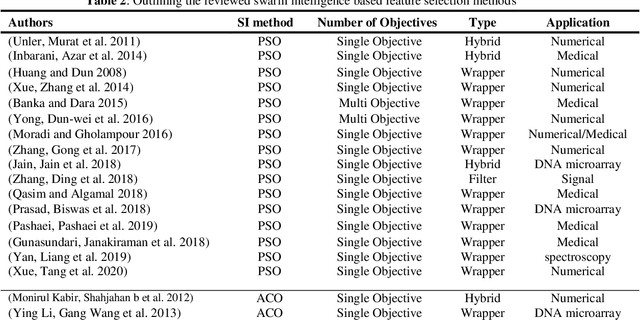
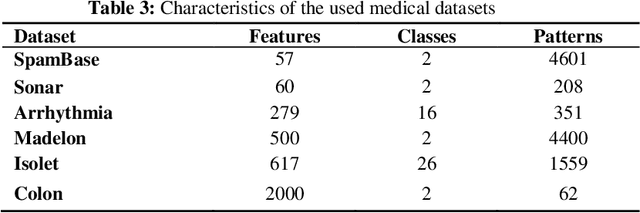
In the past decades, the rapid growth of computer and database technologies has led to the rapid growth of large-scale datasets. On the other hand, data mining applications with high dimensional datasets that require high speed and accuracy are rapidly increasing. An important issue with these applications is the curse of dimensionality, where the number of features is much higher than the number of patterns. One of the dimensionality reduction approaches is feature selection that can increase the accuracy of the data mining task and reduce its computational complexity. The feature selection method aims at selecting a subset of features with the lowest inner similarity and highest relevancy to the target class. It reduces the dimensionality of the data by eliminating irrelevant, redundant, or noisy data. In this paper, a comparative analysis of different feature selection methods is presented, and a general categorization of these methods is performed. Moreover, in this paper, state-of-the-art swarm intelligence are studied, and the recent feature selection methods based on these algorithms are reviewed. Furthermore, the strengths and weaknesses of the different studied swarm intelligence-based feature selection methods are evaluated.
Presentation of a Recommender System with Ensemble Learning and Graph Embedding: A Case on MovieLens
Jul 15, 2020


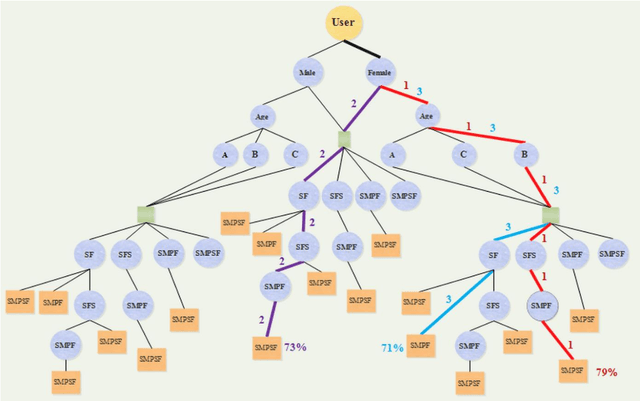
Information technology has spread widely, and extraordinarily large amounts of data have been made accessible to users, which has made it challenging to select data that are in accordance with user needs. For the resolution of the above issue, recommender systems have emerged, which much help users go through the process of decision-making and selecting relevant data. A recommender system predicts users behavior to be capable of detecting their interests and needs, and it often uses the classification technique for this purpose. It may not be sufficiently accurate to employ individual classification, where not all cases can be examined, which makes the method inappropriate to specific problems. In this research, group classification and the ensemble learning technique were used for increasing prediction accuracy in recommender systems. Another issue that is raised here concerns user analysis. Given the large size of the data and a large number of users, the process of user needs analysis and prediction (using a graph in most cases, representing the relations between users and their selected items) is complicated and cumbersome in recommender systems. Graph embedding was also proposed for resolution of this issue, where all or part of user behavior can be simulated through the generation of several vectors, resolving the problem of user behavior analysis to a large extent while maintaining high efficiency. In this research, individuals most similar to the target user were classified using ensemble learning, fuzzy rules, and the decision tree, and relevant recommendations were then made to each user with a heterogeneous knowledge graph and embedding vectors. This study was performed on the MovieLens datasets, and the obtained results indicated the high efficiency of the presented method.