 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Community Detection Based Genetic Algorithm for Feature Selection
Paper and Code
Aug 08, 2020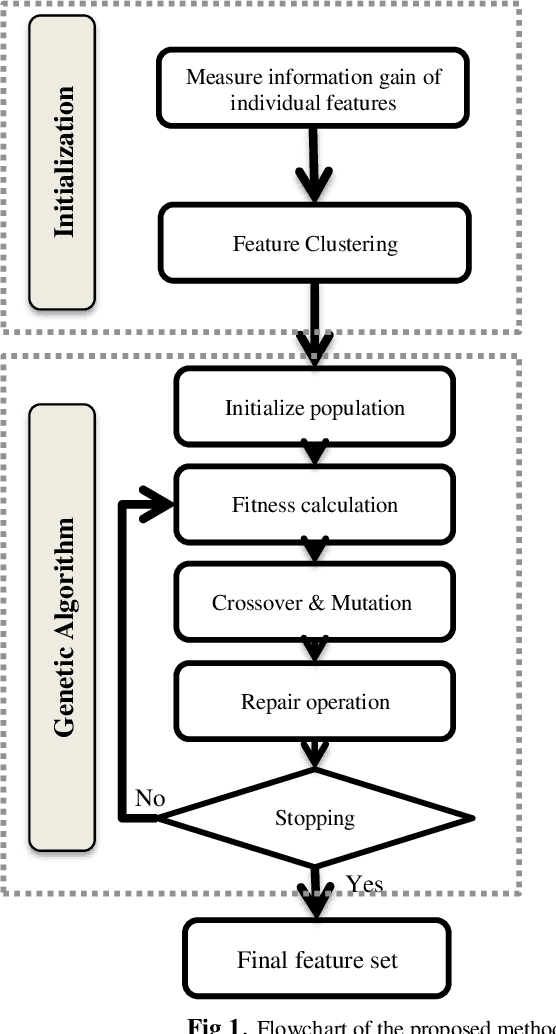
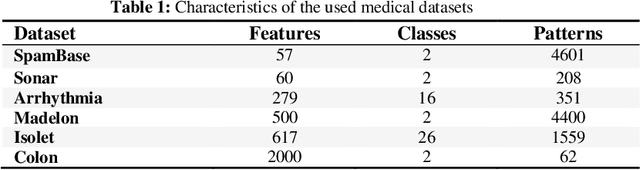
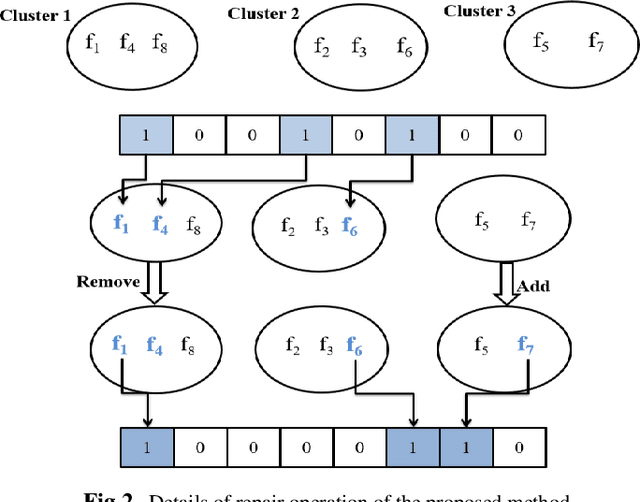

The selection of features is an essential data preprocessing stage in data mining. The core principle of feature selection seems to be to pick a subset of possible features by excluding features with almost no predictive information as well as highly associated redundant features. In the past several years, a variety of meta-heuristic methods were introduced to eliminate redundant and irrelevant features as much as possible from high-dimensional datasets. Among the main disadvantages of present meta-heuristic based approaches is that they are often neglecting the correlation between a set of selected features. In this article, for the purpose of feature selection, the authors propose a genetic algorithm based on community detection, which functions in three steps. The feature similarities are calculated in the first step. The features are classified by community detection algorithms into clusters throughout the second step. In the third step, features are picked by a genetic algorithm with a new community-based repair operation. Nine benchmark classification problems were analyzed in terms of the performance of the presented approach. Also, the authors have compared the efficiency of the proposed approach with the findings from four available algorithms for feature selection. The findings indicate that the new approach continuously yields improved classification accuracy.