 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyena Operator for Fast Sequential Recommendation
Mar 26, 2026Sequential recommendation models, particularly those based on attention, achieve strong accuracy but incur quadratic complexity, making long user histories prohibitively expensive. Sub-quadratic operators such as Hyena provide efficient alternatives in language modeling, but their potential in recommendation remains underexplored. We argue that Hyena faces challenges in recommendation due to limited representation capacity on sparse, long user sequences. To address these challenges, we propose HyenaRec, a novel sequential recommender that integrates polynomial-based kernel parameterization with gated convolutions. Specifically, we design convolutional kernels using Legendre orthogonal polynomials, which provides a smooth and compact basis for modeling long-term temporal dependencies. A complementary gating mechanism captures fine-grained short-term behavioral bursts, yielding a hybrid architecture that balances global temporal evolution with localized user interests under sparse feedback. This construction enhances expressiveness while scaling linearly with sequence length. Extensive experiments on multiple real-world datasets demonstrate that HyenaRec consistently outperforms Attention-, Recurrent-, and other baselines in ranking accuracy. Moreover, it trains significantly faster (up to 6x speedup), with particularly pronounced advantages on long-sequence scenarios where efficiency is maintained without sacrificing accuracy. These results highlight polynomial-based kernel parameterization as a principled and scalable alternative to attention for sequential recommendation.
Certified Signed Graph Unlearning
Nov 18, 2025Signed graphs model complex relationships through positive and negative edges, with widespread real-world applications. Given the sensitive nature of such data, selective removal mechanisms have become essential for privacy protection. While graph unlearning enables the removal of specific data influences from Graph Neural Networks (GNNs), existing methods are designed for conventional GNNs and overlook the unique heterogeneous properties of signed graphs. When applied to Signed Graph Neural Networks (SGNNs), these methods lose critical sign information, degrading both model utility and unlearning effectiveness. To address these challenges, we propose Certified Signed Graph Unlearning (CSGU), which provides provable privacy guarantees while preserving the sociological principles underlying SGNNs. CSGU employs a three-stage method: (1) efficiently identifying minimal influenced neighborhoods via triangular structures, (2) applying sociological theories to quantify node importance for optimal privacy budget allocation, and (3) performing importance-weighted parameter updates to achieve certified modifications with minimal utility degradation. Extensive experiments demonstrate that CSGU outperforms existing methods, achieving superior performance in both utility preservation and unlearning effectiveness on SGNNs.
CrimeAlarm: Towards Intensive Intent Dynamics in Fine-grained Crime Prediction
Apr 10, 2024



Granularity and accuracy are two crucial factors for crime event prediction. Within fine-grained event classification, multiple criminal intents may alternately exhibit in preceding sequential events, and progress differently in next. Such intensive intent dynamics makes training models hard to capture unobserved intents, and thus leads to sub-optimal generalization performance, especially in the intertwining of numerous potential events. To capture comprehensive criminal intents, this paper proposes a fine-grained sequential crime prediction framework, CrimeAlarm, that equips with a novel mutual distillation strategy inspired by curriculum learning. During the early training phase, spot-shared criminal intents are captured through high-confidence sequence samples. In the later phase, spot-specific intents are gradually learned by increasing the contribution of low-confidence sequences. Meanwhile, the output probability distributions are reciprocally learned between prediction networks to model unobserved criminal intents. Extensive experiments show that CrimeAlarm outperforms state-of-the-art methods in terms of NDCG@5, with improvements of 4.51% for the NYC16 and 7.73% for the CHI18 in accuracy measures.
What is Next when Sequential Prediction Meets Implicitly Hard Interaction?
Feb 14, 2022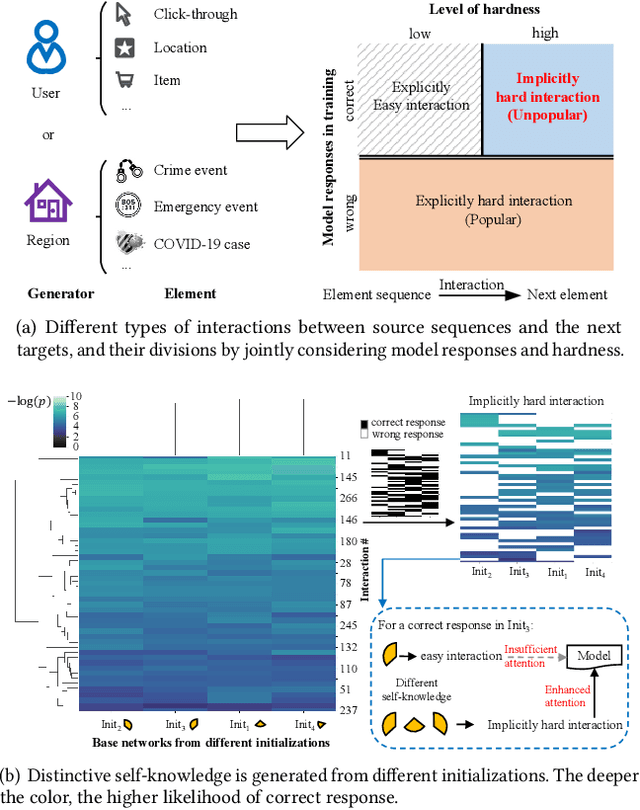
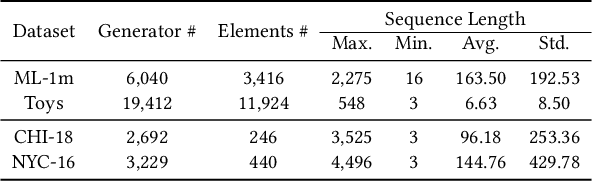
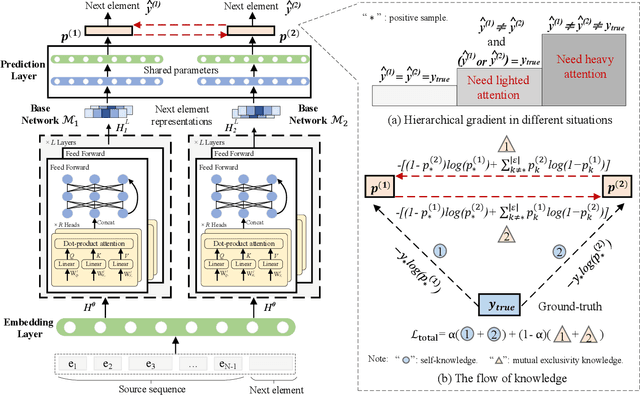
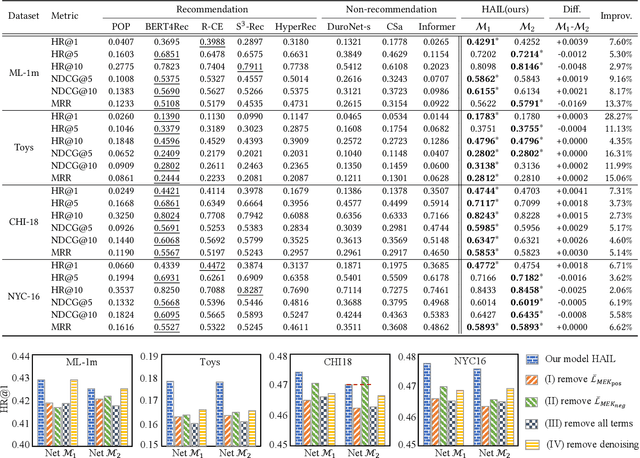
Hard interaction learning between source sequences and their next targets is challenging, which exists in a myriad of sequential prediction tasks. During the training process, most existing methods focus on explicitly hard interactions caused by wrong responses. However, a model might conduct correct responses by capturing a subset of learnable patterns, which results in implicitly hard interactions with some unlearned patterns. As such, its generalization performance is weakened. The problem gets more serious in sequential prediction due to the interference of substantial similar candidate targets. To this end, we propose a Hardness Aware Interaction Learning framework (HAIL) that mainly consists of two base sequential learning networks and mutual exclusivity distillation (MED). The base networks are initialized differently to learn distinctive view patterns, thus gaining different training experiences. The experiences in the form of the unlikelihood of correct responses are drawn from each other by MED, which provides mutual exclusivity knowledge to figure out implicitly hard interactions. Moreover, we deduce that the unlikelihood essentially introduces additional gradients to push the pattern learning of correct responses. Our framework can be easily extended to more peer base networks. Evaluation is conducted on four datasets covering cyber and physical spaces. The experimental results demonstrate that our framework outperforms several state-of-the-art methods in terms of top-k based metrics.