 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Efficient Medical Imaging with Self-Supervision
May 19, 2022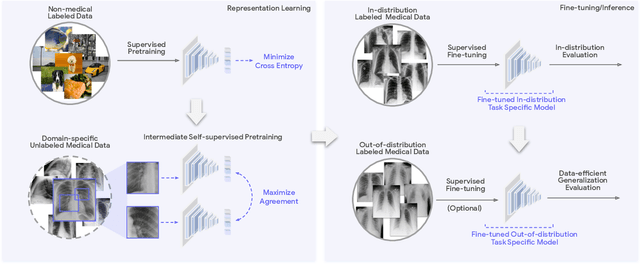
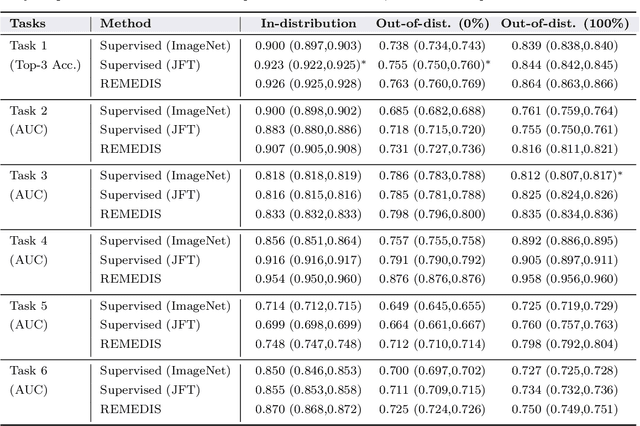
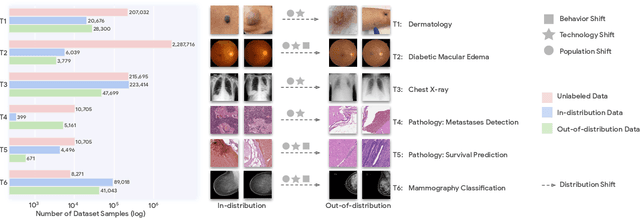

Recent progress in Medical Artificial Intelligence (AI) has delivered systems that can reach clinical expert level performance. However, such systems tend to demonstrate sub-optimal "out-of-distribution" performance when evaluated in clinical settings different from the training environment. A common mitigation strategy is to develop separate systems for each clinical setting using site-specific data [1]. However, this quickly becomes impractical as medical data is time-consuming to acquire and expensive to annotate [2]. Thus, the problem of "data-efficient generalization" presents an ongoing difficulty for Medical AI development. Although progress in representation learning shows promise, their benefits have not been rigorously studied, specifically for out-of-distribution settings. To meet these challenges, we present REMEDIS, a unified representation learning strategy to improve robustness and data-efficiency of medical imaging AI. REMEDIS uses a generic combination of large-scale supervised transfer learning with self-supervised learning and requires little task-specific customization. We study a diverse range of medical imaging tasks and simulate three realistic application scenarios using retrospective data. REMEDIS exhibits significantly improved in-distribution performance with up to 11.5% relative improvement in diagnostic accuracy over a strong supervised baseline. More importantly, our strategy leads to strong data-efficient generalization of medical imaging AI, matching strong supervised baselines using between 1% to 33% of retraining data across tasks. These results suggest that REMEDIS can significantly accelerate the life-cycle of medical imaging AI development thereby presenting an important step forward for medical imaging AI to deliver broad impact.
Adversarial Policy Gradient for Deep Learning Image Augmentation
Sep 09, 2019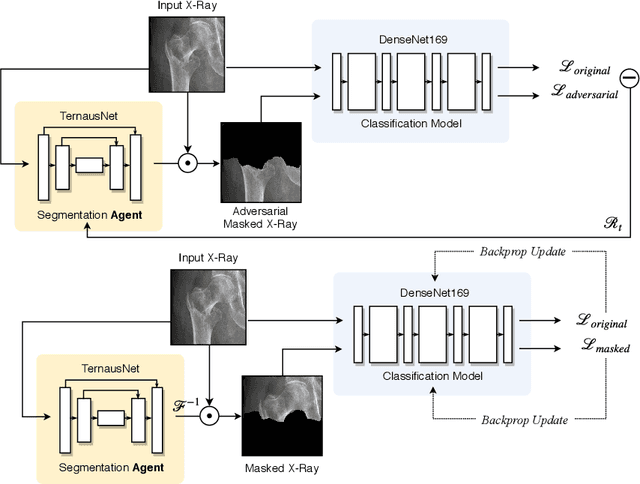
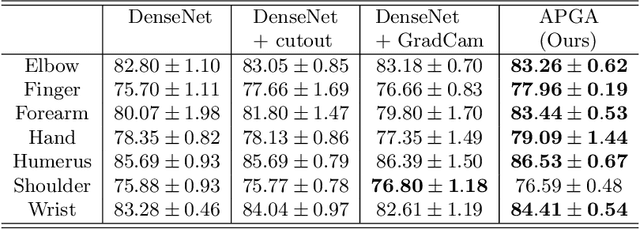

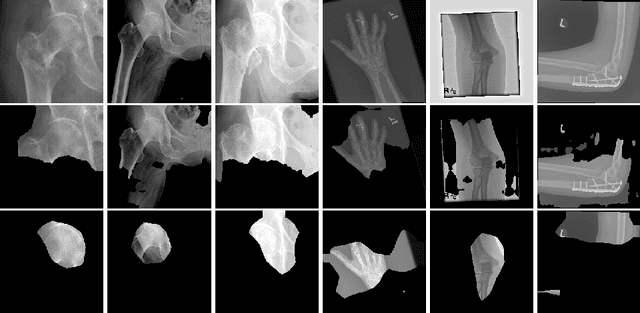
The use of semantic segmentation for masking and cropping input images has proven to be a significant aid in medical imaging classification tasks by decreasing the noise and variance of the training dataset. However, implementing this approach with classical methods is challenging: the cost of obtaining a dense segmentation is high, and the precise input area that is most crucial to the classification task is difficult to determine a-priori. We propose a novel joint-training deep reinforcement learning framework for image augmentation. A segmentation network, weakly supervised with policy gradient optimization, acts as an agent, and outputs masks as actions given samples as states, with the goal of maximizing reward signals from the classification network. In this way, the segmentation network learns to mask unimportant imaging features. Our method, Adversarial Policy Gradient Augmentation (APGA), shows promising results on Stanford's MURA dataset and on a hip fracture classification task with an increase in global accuracy of up to 7.33% and improved performance over baseline methods in 9/10 tasks evaluated. We discuss the broad applicability of our joint training strategy to a variety of medical imaging tasks.