 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing Rhetorical Parallelism Detection: A New Task with Datasets, Metrics, and Baselines
Nov 30, 2023Rhetoric, both spoken and written, involves not only content but also style. One common stylistic tool is $\textit{parallelism}$: the juxtaposition of phrases which have the same sequence of linguistic ($\textit{e.g.}$, phonological, syntactic, semantic) features. Despite the ubiquity of parallelism, the field of natural language processing has seldom investigated it, missing a chance to better understand the nature of the structure, meaning, and intent that humans convey. To address this, we introduce the task of $\textit{rhetorical parallelism detection}$. We construct a formal definition of it; we provide one new Latin dataset and one adapted Chinese dataset for it; we establish a family of metrics to evaluate performance on it; and, lastly, we create baseline systems and novel sequence labeling schemes to capture it. On our strictest metric, we attain $F_{1}$ scores of $0.40$ and $0.43$ on our Latin and Chinese datasets, respectively.
Representing Unordered Data Using Multiset Automata and Complex Numbers
Jan 02, 2020
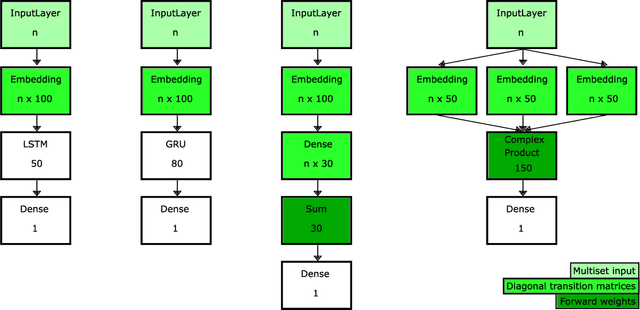
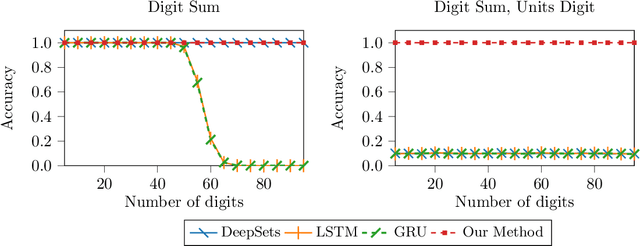
Unordered, variable-sized inputs arise in many settings across multiple fields. The ability for set- and multiset- oriented neural networks to handle this type of input has been the focus of much work in recent years. We propose to represent multisets using complex-weighted multiset automata and show how the multiset representations of certain existing neural architectures can be viewed as special cases of ours. Namely, (1) we provide a new theoretical and intuitive justification for the Transformer model's representation of positions using sinusoidal functions, and (2) we extend the DeepSets model to use complex numbers, enabling it to outperform the existing model on an extension of one of their tasks.
Part-of-Speech Tagging on an Endangered Language: a Parallel Griko-Italian Resource
Jun 11, 2018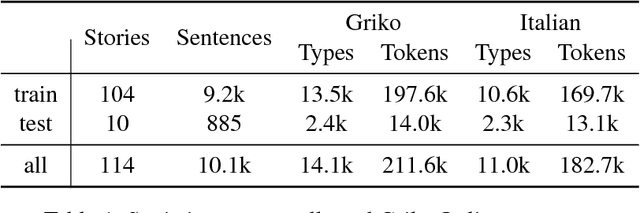

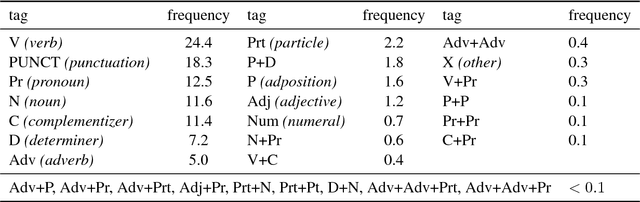

Most work on part-of-speech (POS) tagging is focused on high resource languages, or examines low-resource and active learning settings through simulated studies. We evaluate POS tagging techniques on an actual endangered language, Griko. We present a resource that contains 114 narratives in Griko, along with sentence-level translations in Italian, and provides gold annotations for the test set. Based on a previously collected small corpus, we investigate several traditional methods, as well as methods that take advantage of monolingual data or project cross-lingual POS tags. We show that the combination of a semi-supervised method with cross-lingual transfer is more appropriate for this extremely challenging setting, with the best tagger achieving an accuracy of 72.9%. With an applied active learning scheme, which we use to collect sentence-level annotations over the test set, we achieve improvements of more than 21 percentage points.