 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Flipper Control of Tracked Robots
Jun 17, 2023



The autonomous control of flippers plays an important role in enhancing the intelligent operation of tracked robots within complex environments. While existing methods mainly rely on hand-crafted control models, in this paper, we introduce a novel approach that leverages deep reinforcement learning (DRL) techniques for autonomous flipper control in complex terrains. Specifically, we propose a new DRL network named AT-D3QN, which ensures safe and smooth flipper control for tracked robots. It comprises two modules, a feature extraction and fusion module for extracting and integrating robot and environment state features, and a deep Q-Learning control generation module for incorporating expert knowledge to obtain a smooth and efficient control strategy. To train the network, a novel reward function is proposed, considering both learning efficiency and passing smoothness. A simulation environment is constructed using the Pymunk physics engine for training. We then directly apply the trained model to a more realistic Gazebo simulation for quantitative analysis. The consistently high performance of the proposed approach validates its superiority over manual teleoperation.
Content-Based Top-N Recommendation using Heterogeneous Relations
Jun 27, 2016
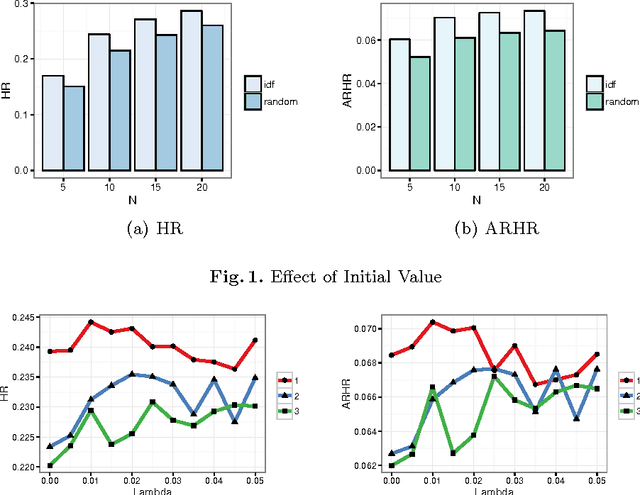
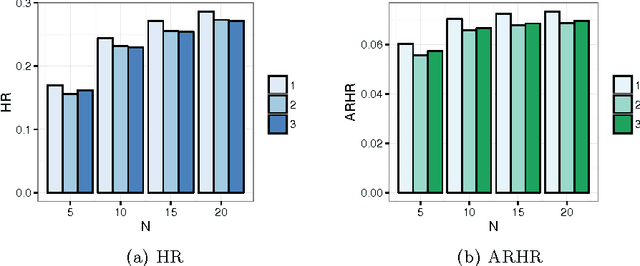
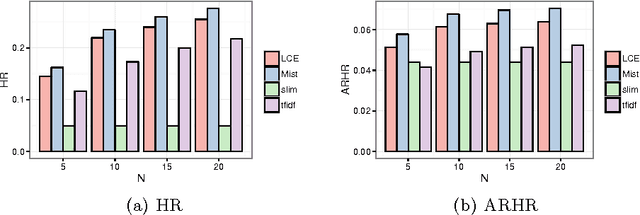
Top-$N$ recommender systems have been extensively studied. However, the sparsity of user-item activities has not been well resolved. While many hybrid systems were proposed to address the cold-start problem, the profile information has not been sufficiently leveraged. Furthermore, the heterogeneity of profiles between users and items intensifies the challenge. In this paper, we propose a content-based top-$N$ recommender system by learning the global term weights in profiles. To achieve this, we bring in PathSim, which could well measures the node similarity with heterogeneous relations (between users and items). Starting from the original TF-IDF value, the global term weights gradually converge, and eventually reflect both profile and activity information. To facilitate training, the derivative is reformulated into matrix form, which could easily be paralleled. We conduct extensive experiments, which demonstrate the superiority of the proposed method.